HDFS学习
3.5 HDFS存储原理
3.5.1 冗余数据保存
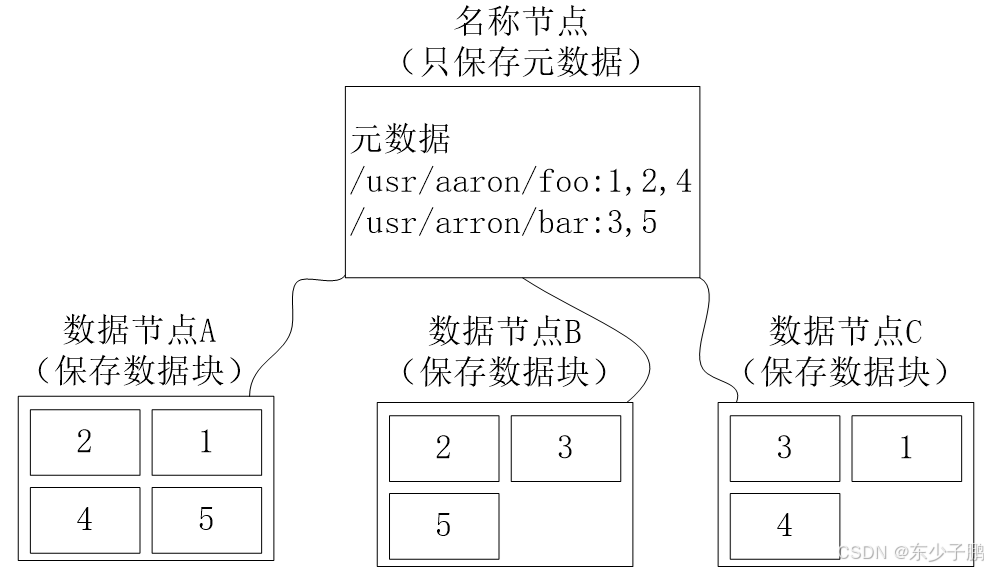
作为一个分布式文件系统,为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上。
如图所示,数据块1被分别存放到数据节点A和C上,数据块2被存放在数据节点A和B上。
这种多副本方式具有以下几个优点:
(1)加快数据传输速度
(2)容易检查数据错误
(3)保证数据可靠性
3.5.2 数据存取策略
1.数据存放
Ø第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
Ø第二个副本:放置在与第一个副本不同的机架的节点上
Ø第三个副本:与第一个副本相同机架的其他节点上
Ø更多副本:随机节点
2. 数据读取
ØHDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也可以调用API获取自己所属的机架ID
Ø当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据
3. 数据复制(采用流水线策略)
当客户端需要向HDFS中写入一个文件时,文件首先被写入本地计算机。
(1)按照HDFS的设置被切分成一定大小的块,具体大小由HDFS设置。
(2)每个块都会向HDFS的NameNode节点发起写请求。
(3)NameNode节点会根据系统中各个DataNode节点的使用情况,选择一个合适的DataNode节点列表返回给客户端。
(4)客户端随后会将数据首先写入列表中的第一个DataNode节点,同时将列表传给该节点。
3 数据复制(采用流水线策略)
(5)第一个DataNode节点在接收到一定数量的数据后,会向列表中的第二个DataNode节点发起连接请求,并把自己已经接收到的数据和列表传给第二个节点。
(6)第二个节点在接收到数据后,也会向列表中的第三个节点发起连接请求。依此类推。这样,列表中的多个DataNode节点形成了一条数据复制的流水线。
3.5.3 数据错误与恢复
HDFS具有较高的容错性,可以兼容廉价的硬件,它把硬件出错看作一种常态,而不是异常,并设计了相应的机制检测数据错误和进行自动恢复,主要包括以下几种情形:
名称节点保存了所有的元数据信息,其中,最核心的两大数据结构是FsImage和Editlog,如果这两个文件发生损坏,那么整个HDFS实例将失效。解决方案:
2. 数据节点出错
3. 数据出错