【后端面试题】【中间件】【NoSQL】ElasticSearch索引机制和高性能的面试思路
Elasticsearch的索引机制
Elasticsearch使用的是倒排索引,所谓的倒排索引是相对于正排索引而言的。
在一般的文件系统中,索引是文档映射到关键字,而倒排索引则相反,是从关键字映射到文档。
如果没有倒排索引的话,想找到包含关键字“Elasticsearch”的文档,需要遍历所有的文档,然后筛选出包含了“Elasticsearch”关键字的文档。有了倒排索引,就可以直接从关键字出发,找到“Elasticsearch”关键字对应的文档。
Elasticsearch依赖Lucene来维护索引,基本原理如下:
- 每次写入一个新的文档的时候,根据文档的每一个字段,Elasticsearch会使用分词器,把每个字段的值切割成一个个关键词,每一个关键词也叫做Term
- 切割之后,Elasticsearch会统计每一个关键词出现的频率,构建一个关键词到文档ID、出现频率、位置的映射,叫做
posting list

从图片里可以看到几个关键点:
- 每个字段是分散统计的
- Elasticsearch记录了两个位置信息,一个位置指的是它是第几个词,另一个偏移量指的是整个关键词的起始位置。比如World在文档0的desc里是第1个词(从0开始),它的位置是从Hello World的起始位置算的第6位字符到11位字符。
存在Elasticsearch里的文档很多,一个字段会有非常多的关键词。假设要查询的是desc里包含Hello这个关键字的文档,首先在关键词表格里找到Hello这一条。如果关键词是随机的,肯定很难找。
如果让你来设计的话,可以考虑把这些关键词排序,比如按字母来排序。但是这种类似查找单词的东西,在业界早就有成熟的方案,就是前缀树,也叫做字典树。
这个关键词表格在Elasticsearch里叫Term Dictionary。它们的目标是尽可能地把全部关键词组成地索引整个装进内存里。
之所以是尽可能,而不是一定,是因为部分字段的关键词非常多,确定装不进去。
Elastiscearch更进一步用了一个优化,就是FST(Finite State Transducers),核心思想是连公共前缀、后缀也一起压缩了。
最基本的概念如下:
假设有两个关键词cat和ct,两种数据结构看起来是这样的
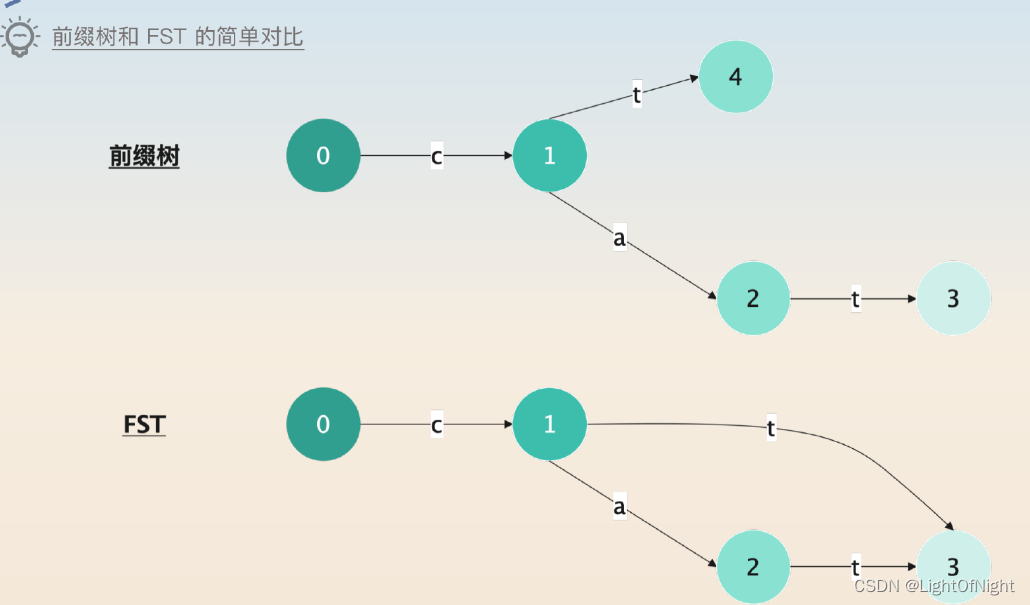
当你找到3的时候,如果经过0-1-3,就知道前缀是ct,并且能够得到ct在Term Dictionary(关键词表格)的位置,这个位置也是ct所在的Block。
如果有其他的关键词,cta、ctb等,都是用这个前缀的,当几千个关键词都共享某个前缀的时候,在一个Block内部怎么找?
Elasticsearch会在Block内部有很多关键词的时候,进一步切割成所谓的Floor Block,每个Floor Block使用第一个关键词的首字母来加快查找。
在Block或Floor Block内部,是通过遍历来查找对应的关键词的,整个结构看起来是下面这样
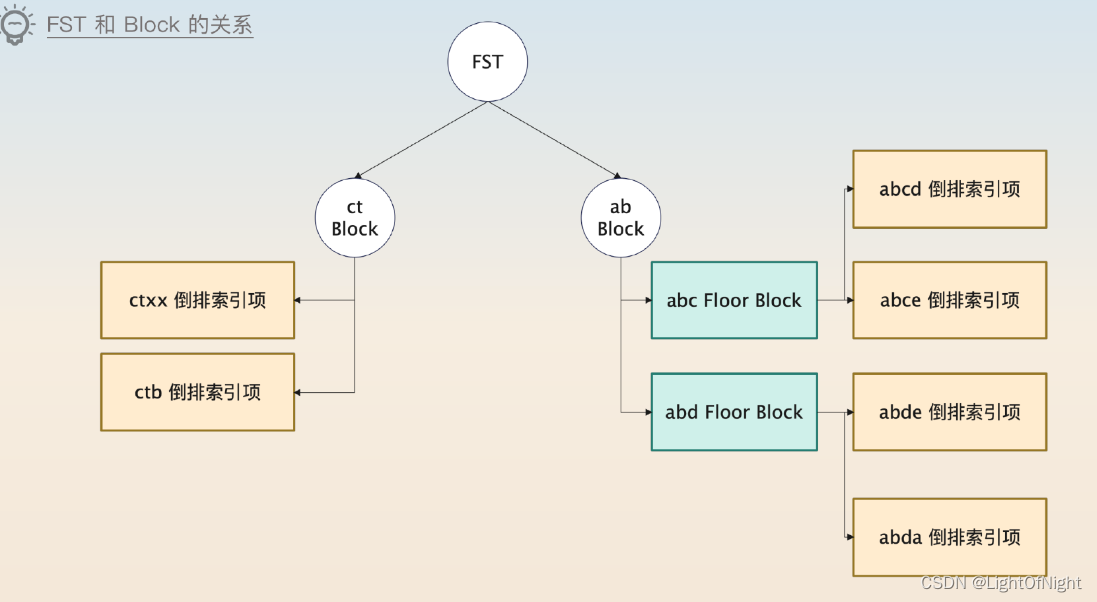
可以把查找关键词的过程理解为两步
- 根据FST找到Block
- 在Block里遍历找到关键词。如果Block进一步细分为Floor Block,就先根据前缀找到Floor Block,然后再去遍历Floor Block。
找到了关键词,也就找到了这个关键词对应的posting list,可以根据文档ID来找到具体的文档了。
面试准备
还要清楚公司内部一些和Elasticsearch有关的数据
- Elasticsearch是如何部署的?有几个节点?每个节点上面内存有多大?这些内存是怎么分配的?
- Elasticsearch上JVM的配置是什么?垃圾回收用的哪个?垃圾回收停顿的实践多长?
- Elasticsearch的哪些配置和默认值不一样,为什么修改?
- Elasticsearch性能如何,能够撑住多大的读写流量
如果本身对Elasticsearch性能优化不是很了解的话,不特别建议在简历或自我介绍的时候提起Elasticsearch性能优化。但是如果很擅长,可以特意强调一下,足以称为竞争优势。