任务4.8.4 利用Spark SQL实现分组排行榜
文章目录
- 1. 任务说明
- 2. 解决思路
- 3. 准备成绩文件
- 4. 采用交互式实现
- 5. 采用Spark项目
- 实战概述:使用Spark SQL实现分组排行榜
- 任务背景
- 任务目标
- 技术选型
- 实现步骤
- 1. 准备数据
- 2. 数据上传至HDFS
- 3. 启动Spark Shell或创建Spark项目
- 4. 读取数据
- 5. 数据转换
- 6. 创建临时视图
- 7. SQL查询实现分组排行榜
- 8. 结果格式化输出
- 9. 运行程序并验证结果
- 代码实现
- 结果展示
- 总结

1. 任务说明

2. 解决思路

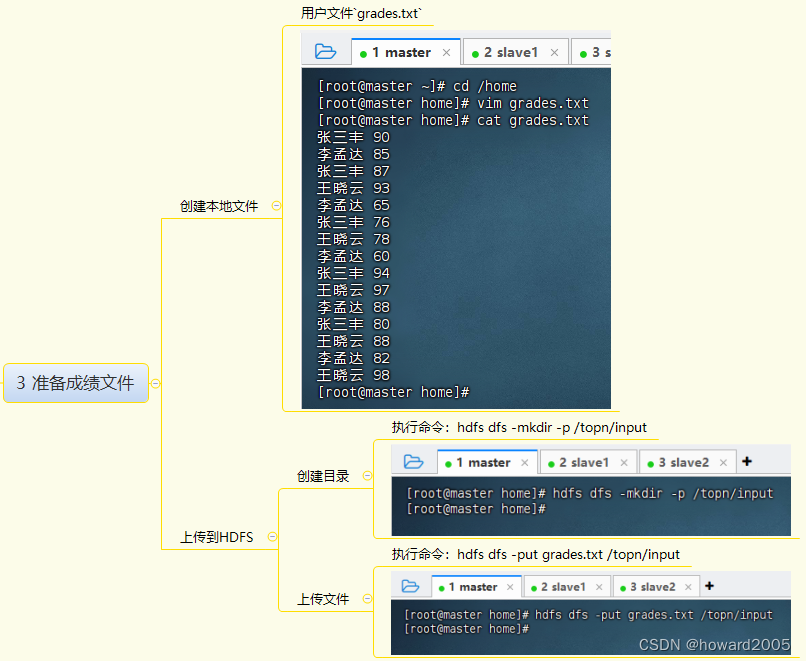
3. 准备成绩文件
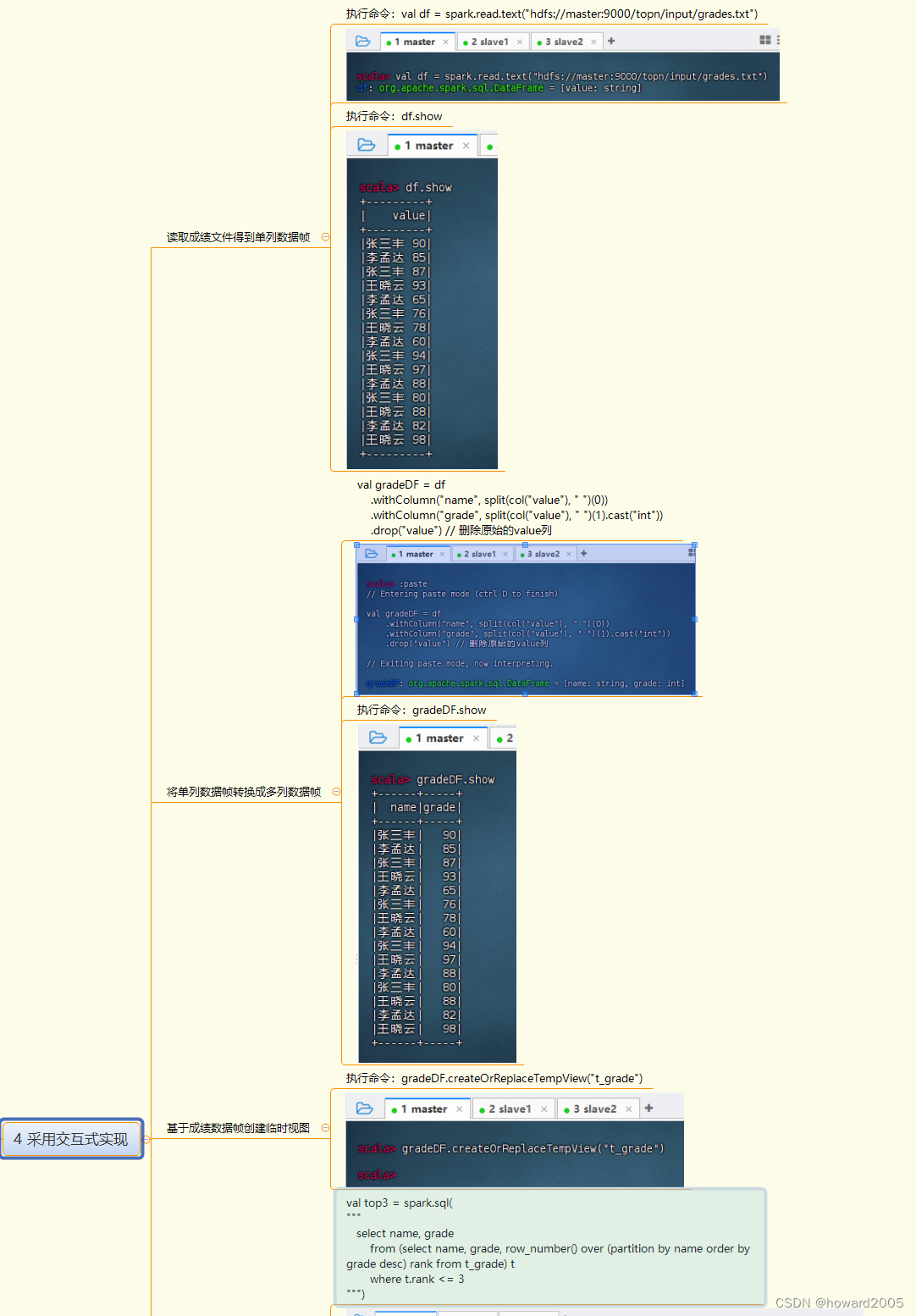
4. 采用交互式实现
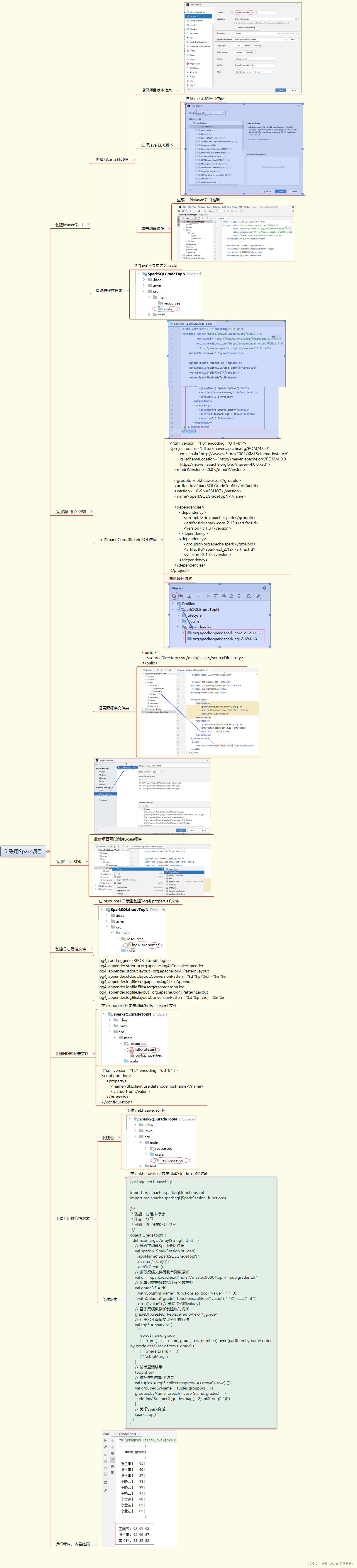
5. 采用Spark项目
实战概述:使用Spark SQL实现分组排行榜
任务背景
在教育数据分析领域,经常需要对学生的成绩进行分组和排名。本实战任务通过Apache Spark的Spark SQL模块,实现对学生成绩数据的分组,并求出每个学生分数最高的前3个成绩。
任务目标
- 处理包含多个学生多条成绩记录的数据集。
- 对每个学生的成绩进行分组,并计算每个学生最高的前3个成绩。
- 以指定的格式输出每个学生的Top3成绩。
技术选型
- 使用Apache Spark作为大数据处理框架。
- 利用Spark SQL进行数据查询和操作。
实现步骤
1. 准备数据
- 创建本地文件
grades.txt,存储学生姓名和对应的成绩。
2. 数据上传至HDFS
- 创建HDFS目录
/topn/input。 - 将
grades.txt上传至HDFS。
3. 启动Spark Shell或创建Spark项目
- 启动Spark Shell或创建Maven项目并配置Spark相关依赖。
4. 读取数据
- 使用Spark读取HDFS上的成绩文件,创建DataFrame。
5. 数据转换
- 将单列DataFrame转换成包含
name和grade的多列DataFrame。
6. 创建临时视图
- 基于DataFrame创建SQL临时视图,以便进行SQL查询。
7. SQL查询实现分组排行榜
- 使用窗口函数
row_number()和over()对每个学生的成绩进行降序排名,并筛选出排名前3的成绩。
8. 结果格式化输出
- 将查询结果转换为元组,然后按学生姓名分组,格式化输出每个学生的Top3成绩。
9. 运行程序并验证结果
- 执行Scala程序,查看输出的Top3成绩是否符合预期。
代码实现
以下是使用Scala编写的Spark程序示例,用于实现分组排行榜功能:
package net.huawei.sqlimport org.apache.spark.sql.{SparkSession, functions}object GradeTopN {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("SparkSQLGradeTopN").master("local[*]").getOrCreate()val df = spark.read.text("hdfs://master:9000/topn/input/grades.txt")val gradeDF = df.selectExpr("split(value, ' ') as (name, grade)").withColumn("grade", functions.expr("cast(grade as int)")).drop("value")gradeDF.createOrReplaceTempView("t_grade")val top3 = spark.sql("""SELECT name, gradeFROM (SELECT name, grade,ROW_NUMBER() OVER (PARTITION BY name ORDER BY grade DESC) as rankFROM t_grade) tWHERE t.rank <= 3""")top3.show()val result = top3.collect.map(row => (row.getString(0), row.getInt(1)))val grouped = result.groupBy(_._1)grouped.foreach { case (name, grades) =>println(s"$name: ${grades.map(_._2).mkString(" ")}")}spark.stop()}
}
结果展示
程序运行后,将输出每个学生的Top3成绩
张三丰: 94 90 87
李孟达: 88 85 82
王晓云: 98 97 93
总结
本实战任务展示了如何使用Spark SQL对数据进行分组和TopN计算,这是大数据领域中常见的数据处理需求。通过Spark SQL的窗口函数,可以方便地实现复杂的数据分析任务。