大数据集群数据传输
简单的服务器间的通信示例
netcat,简写为 nc,是 unix 系统下一个强大的命令行网络通信工具,用于在两台主机之间建立 TCP 或者 UDP 连接,并提供丰富的命令进行数据通信。nc 在网络参考模型属于应用层。使用 nc 可以做很多事情:建立连接,发送数据包,监听端口,扫描端口,处理 ip4 和 ip6,和 telnet 不同,nc 会区分错误输出和标准输出,telnet 则都是标准输出。
启动服务端 nc -l 端口号nc -l 6666启动客户端nc 服务端IP 6666Kafka 类似,但更加强大,下面是一个Kafka 生产者生产数据到topic ,消费者(flink)在topic中消费到数据,将数据落地为文件的案例:
第一步:创建一个topic
1、topic名称带有明显来源和业务的单词,例如:t_jif_tgcdr
2、topic备份数量小于等于kafka节点数;
3、topic分区数应是备份数的倍数关系;
4、检查topic是否已经存在,如果存在,需另外起名
kafka-topics.sh \
--bootstrap-server xxx.xxx.xxx.xxx:xxxx \
--create \
--replication-factor 3 \
--partitions 3 \
--topic kfk_big_data_study也许会出现这个警告,就是建议topic 名称
![]()

查看kafka是否创建成功
kafka-topics.sh --list --bootstrap-server xxx.xxx.xxx.xxx:xxxx |grep study
二、对接表字段
1、对端一定要提供数据的结构;
2、对端要提供数据样例;
3、通过样例判断是txt、json、还是混合数据格式
4、要确定数据是实时、增量、全量问题
5、在数据云调度上创建物理模型并落地hive
6、如需同步行云,需创建物理模型落地行云
这里面我们只介绍自己生产数据, 数据样例:
结构如:
name|age|kungfu
例如
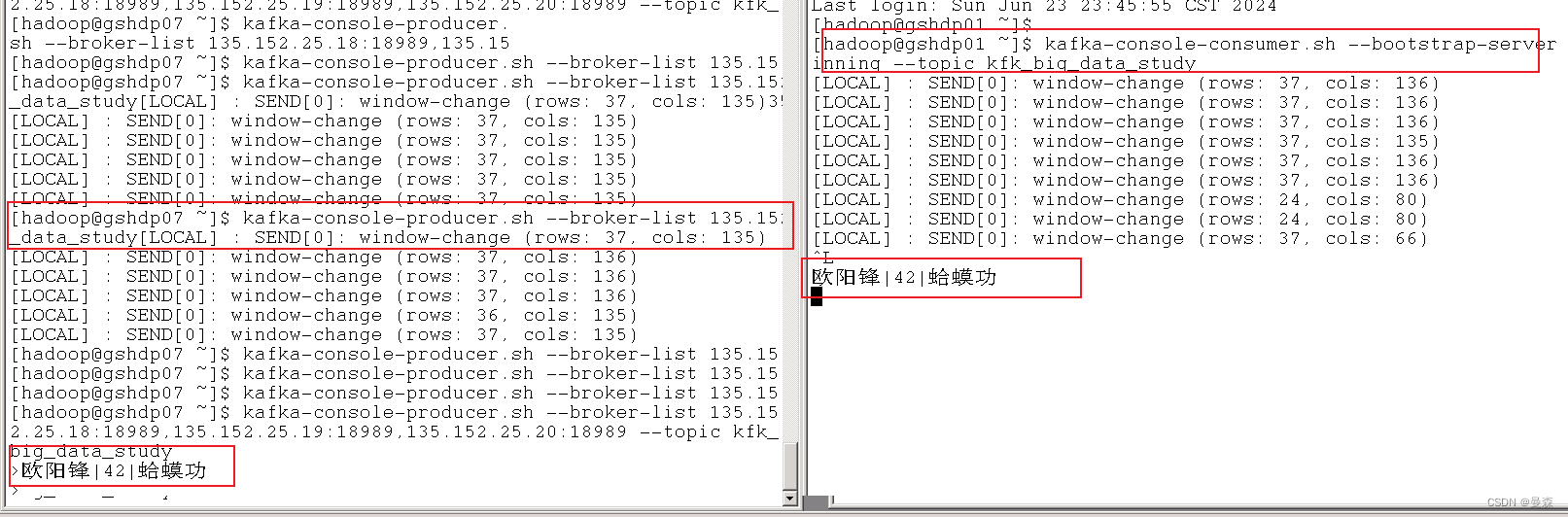
欧阳锋|42|蛤蟆功
三、创建生产者
kafka-console-producer.sh --broker-list xxx.xxx.xxx.xxx:xxxx --topic kfk_big_data_study
四、测试消费
kafka-console-consumer.sh --bootstrap-server xxx.xxx.xxx.xxx:xxxx --from-beginning --topic kfk_big_data_study
五、创建Flink来消费Topic中的数据
https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/connectors/table/kafka/
set setexecution.checkpointing.interval=30sec;
set parallelism.default=9;
set execution.target=yarn-per-job;
set yarn.application.name=yarn_kfk_big_data_study;
set yarn.application.queue=root|default|hadoop|user-defined;--创建Kafka表
drop table if EXISTS kafka_big_data_study;
CREATE TABLE IF NOT EXISTS kafka_big_data_study(
name string,
age string,
kungfu string
) WITH ('connector' = 'kafka','topic' = 'kfk_big_data_study','properties.group.id'='group_01','properties.bootstrap.servers' = 'xxx.xxx.xxx.xxx:xxxx','scan.startup.mode' = 'earliest-offset','format' = 'csv','csv.ignore-parse-errors' = 'true','csv.allow-comments' = 'true'
);--创建Sink表
drop table IF EXISTS t_big_data_study;
CREATE TABLE t_big_data_study(
name string,
age string,
kungfu string
) WITH ('connector' = 'filesystem','path' = 'hdfs://beh001/gsdx_data/spooldirtohive/study/t_big_data_study/','format' = 'csv','csv.field-delimiter' = '|'
);--从kafka表插入数据到Sink表
insert into t_big_data_study
select
name ,
age ,
kungfu
from kafka_big_data_study;将以上脚本保存在一个自定义的sql文件中,然后使用下面的命令调用
sql-client.sh -f study.sql 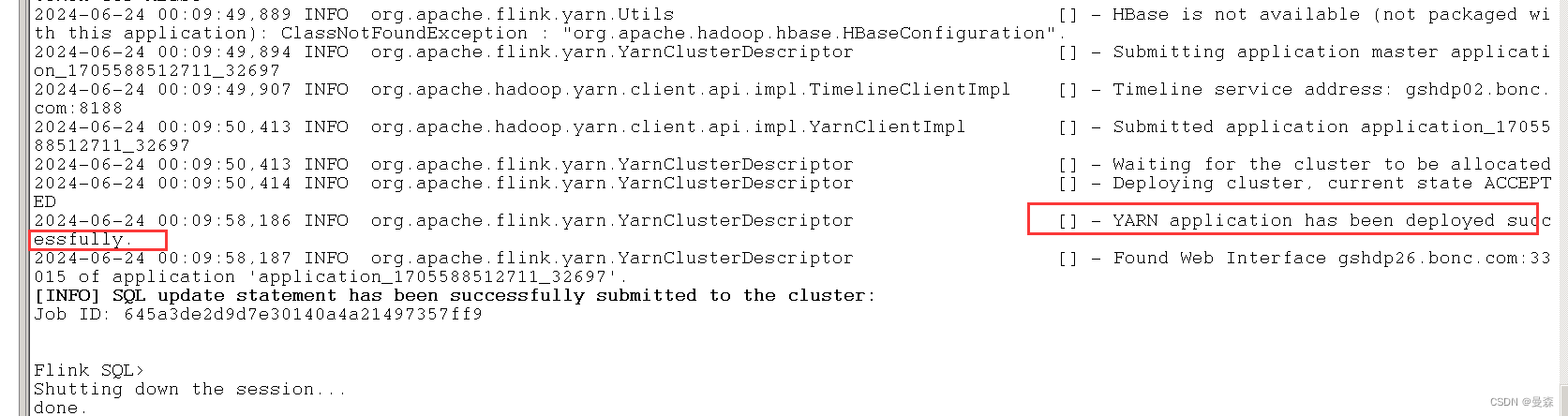
看到这个情况说明flink job已经启动;
接下来,生产一条消息看看是否会落地到hdfs目录

