计算预卷积特征
当冻结卷积层和训练模型时,全连接层或dense层(vgg.classifier)的输入始终是相同的。为了更好地理解,让我们将卷积块(在示例中为vgg.features块)视为具有了已学习好的权重且在训练期间不会更改的函数。因此,计算卷积特征并保存下来将有助于我们提高训练速度。训练模型的时间减少了,因为我们只计算一次这些特征而不是每轮都计算。让我们在结合图5.21理解并实现同样的功能。
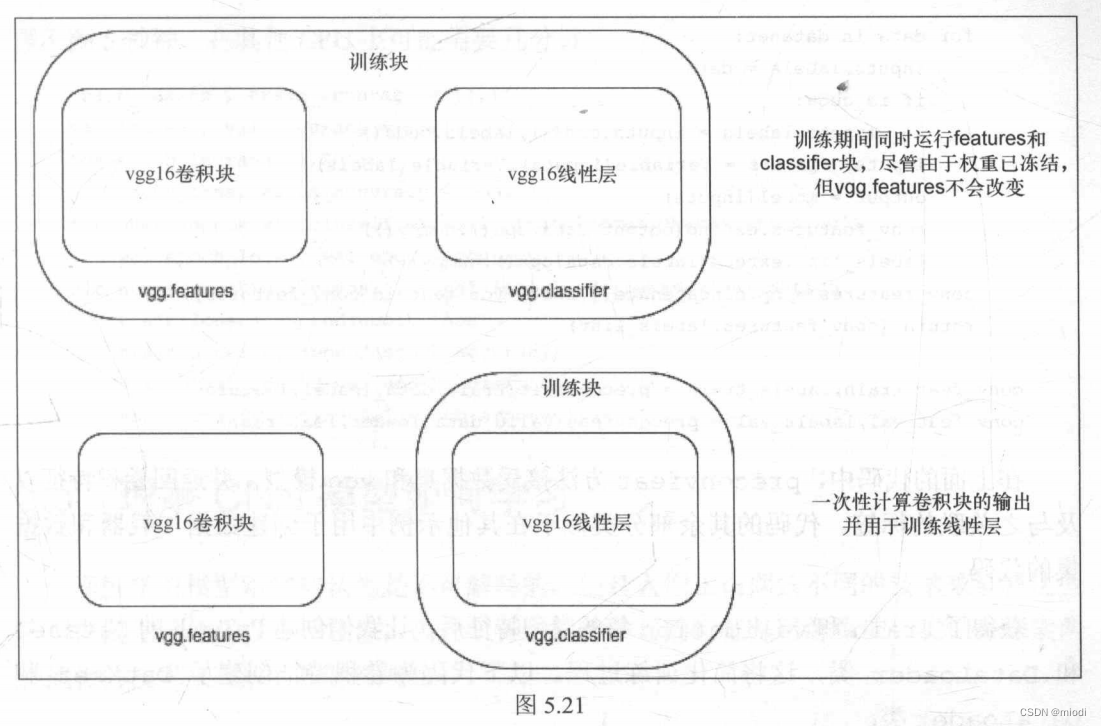
第一个框描述了一般情况下如何进行训练,这可能很慢,因为尽管值不会改变,但仍为每轮计算卷积特征。在底部的框中,一次性计算卷积特征并仅训练线性层。为了计算预卷积特征,我们将所有训练数据传给卷积块并保存它们。为了实现这一点,需要选择 VGG 模型的卷积块。幸运的是,VGG16的PyTorch实现包含了两个序列模型,所以只选择第一个序列模型的特征就可以了。以下代码执行此操作:
vgg = models.vggl6(pretrained=True)
vgg = vgg.cuda()
features = vgg.features
train_data_loader = torch.utils.data.Dataloader(train,batch_size=32,num_workers=3,shuffle=False)
valid_data_loader=
torch.utils,data.Dataloader(valid,batch_size=32,num_workers=3,shuffle=False)
def preconvfeat(dataset,model):conv_features = []labels_list = []for data in dataset:inputs,labels = dataif is_cuda:inputs,labels = inputs.cuda(),labels.cuda()inputs,labels = Variable(inputs),Variable(labels)output = model(inputs)conv_features.extend(output.data.cpu().numpy())labels_list.extend(labels.data.cpu().numpy())conv_features = np.concatenate([[feat] for feat in conv_features])return (conv_features,labels_list)
conv_feat_train,labels_train = preconvfeat(train_data_loader, features)
conv_feat_val,labels_val = preconvfeat (valid_data_loader, features) 在上面的代码中,preconvfeat 方法接受数据集和 vgg 模型,并返回卷积特征以及与之关联的标签。代码的其余部分类似于在其他示例中用于创建数据加载器和数据集的代码。
获得了 train 和 validation 集的卷积特征后,让我们创建 PyTorch 的 Dataset 和 DataLoader 类,这将简化训练过程。以下代码为卷积特征创建了 Dataset 和 DataLoader 类:
class My dataset(Dataset):def _init_(self,feat,labels):self.conv_feat = featself.labels = labelsdef _len_(self):return len(self.conv_feat)def _getitem_(self,idx):return self.conv_feat[idx],self.labels[idx]train_feat_dataset = My_dataset(conv_feat_train,labels_train)
val_feat_dataset = My_dataset(conv_feat_val,labels_val)
train_feat_loader =
DataLoader(train_feat_dataset,batch_size=64,shuffle=True)
val_feat_loader =
DataLoader(val_feat_dataset,batch_size=64,shuffle=True)由于有新的数据加载器可以生成批量的卷积特征以及标签,因此可以使用与另一个例子相同的训练函数。现在将使用 vgg.classifier 作为创建 optimizer 和 fit 方法的模型。下面的代码训练分类器模块来识别狗和猫。在Titan X GPU上,每轮训练只需不到5秒钟,在其他CPU上可能需要几分钟:
train_losses, train_accuracy = [],[]
val_losses, val_accuracy = [],[]
for epoch in range(1,20):epoch_loss, epoch_accuracy =fit_numpy(epoch,vgg.classifier,train_feat_loader,phase='training')val_epoch_loss,val_epoch_accuracy = fit_numpy(epoch,vgg.classifier,val_feat_loader,phase='validation')train_losses.append(epoch_loss)train_accuracy.append(epoch_accuracy)val_losses.append(val_epoch_loss)val_accuracy.append(val_epoch_accuracy)