Python网络爬虫实战6—下一页,模拟用户点击,切换窗口
【前期提要】感兴趣的可以看看往期文章哈~
Python网络爬虫5-实战网页爬取
Python网络爬虫4-实战爬取pdf
Pyhon网络爬虫3-模拟用户点击
Python网络爬虫实战2-下载url下的pdf
Python网络爬虫基础1
1.需求背景
针对长虹美菱电器说明书网页形式,编写爬虫代码,要求获取对应型号的pdf。
网站分析:
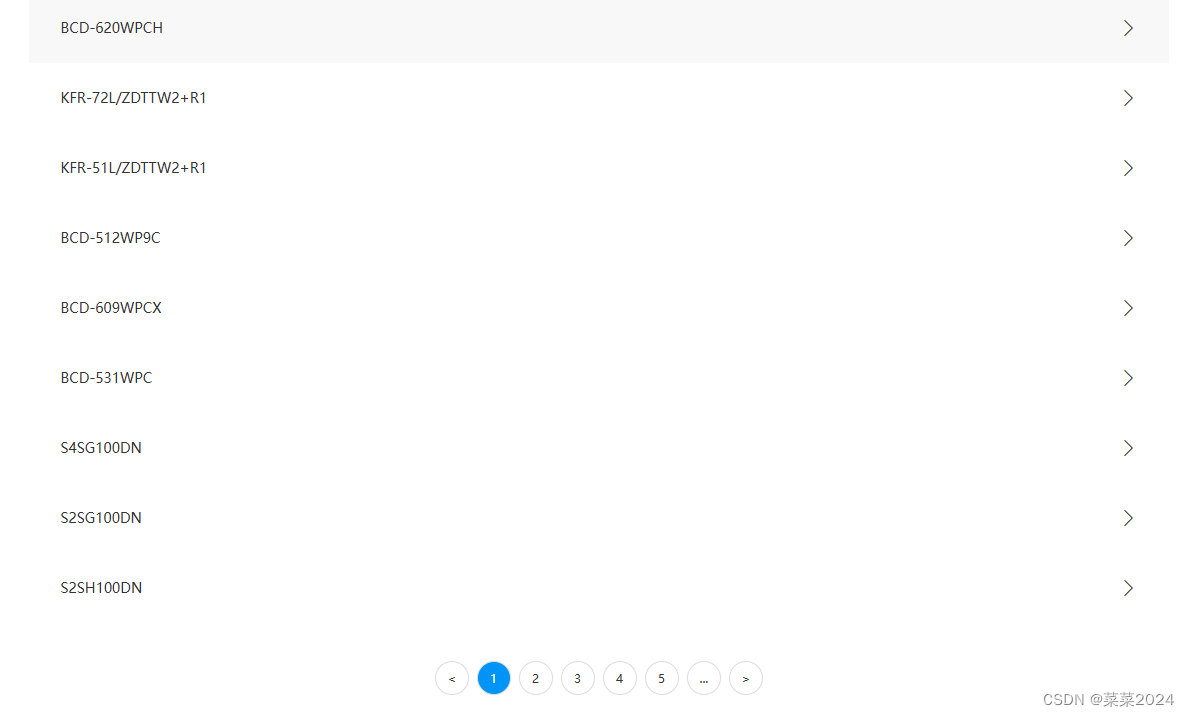
第一步:点击一个具体的型号,会打开一个新的pdf的页面,就是目标型号的pdf
第二步:在新的页面点击下载按钮,下载pdf
第三步:切换回原始的型号列表页面
第四步:点击下一页,下载其他型号pdf
2.主要困难与解决方法
上述分析过程有以下需要解决的问题:
问题1. pdf连接不直接暴露。按F12打开开发者模式,我们可以看到,按钮链接时什么也没有的。也就是说不能采用requests获取url的方式,只能通过Selenium模拟用户点击。
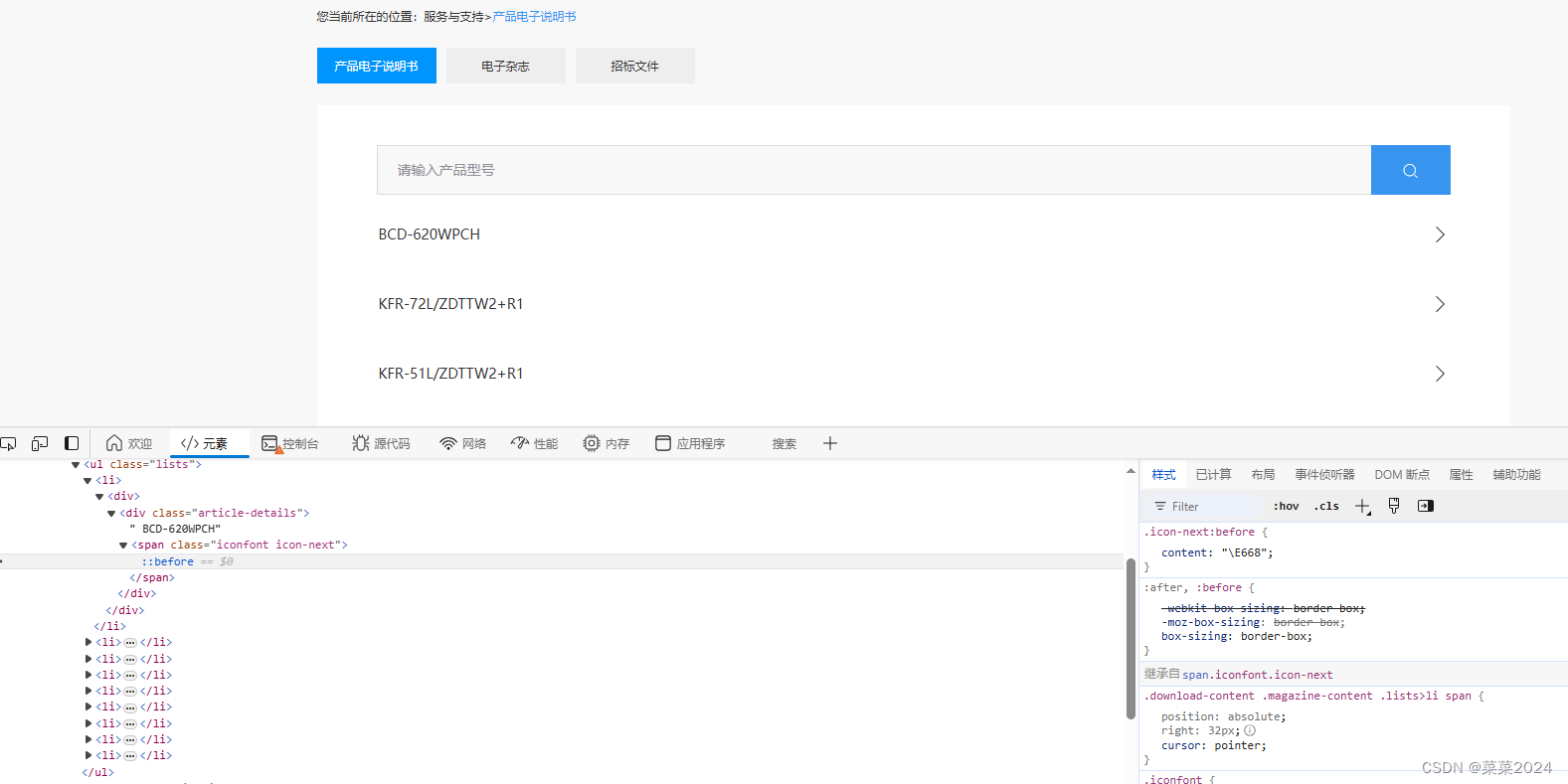
解决1:Selenium模拟用户点击,开发者模式下获取向右箭头的位置。发现第一个的Xpath为:
/html/body/div/div[2]/div/div[3]/ul/li[1]/div/div/span-----第一个
/html/body/div/div[2]/div/div[3]/ul/li[2]/div/div/span-----第二个
.....
/html/body/div/div[2]/div/div[3]/ul/li[9]/div/div/span-----第九个个
每一页有九个,可以使用一个for循环用i变量来循环每个位置:
/html/body/div/div[2]/div/div[3]/ul/li[{i}]/div/div/span
同理,我们也可以得到对应的文字说明位置。
/html/body/div/div[2]/div/div[3]/ul/li[{i}]/div/div/text()
问题2:点击箭头打开新的连接页面,通过 self.driver.switch_to.window(handle),切换窗口,pdf_url = self.driver.current_url得到pdf连接,发现此url,无法通过使用download_file_from_url函数下载pdf。
def download_file_from_url(url, save_path, file_name):'''url为以.pdf为结尾的链接'''response = requests.get(url, timeout=10, stream=True, verify=False)if response.status_code == 200:with open(os.path.join(save_path, file_name), 'wb') as f:for chunk in response.iter_content(1024):f.write(chunk)return Trueelse:return False
报错如下:
requests.exceptions.SSLError: HTTPSConnectionPool(host=‘mlmall.meiling.com’, port=443): Max retries exceeded with url
通常表示在尝试通过HTTPS(端口443)连接到指定的主机(mlmall.meiling.com)时发生了SSL/TLS相关的问题
可能是SSL证书问题
总之,是无法从url链接下载pdf。还是只能使用模拟用户点击。
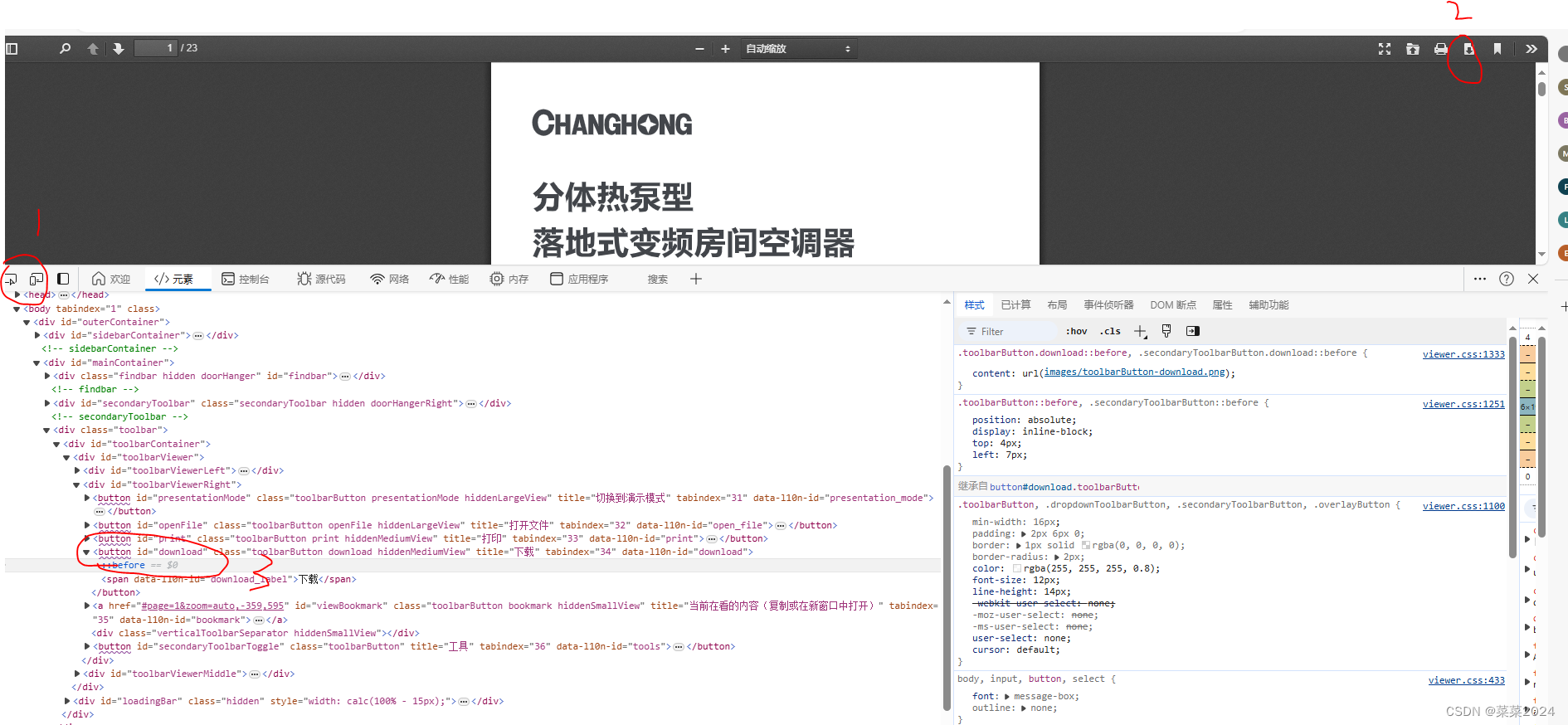
**解决2:**如图所示,找到下载按钮的xapth=//*[@id=“download”] 以此进行定位和点击。
如此便有另一个问题,就是点击此按钮就进行下载pdf了,并不能进行重命名。解决方法只能是将对应的pdf链接和下载的文件及对应的型号信息存储在excel中,爬取完成之后,再根据excel中的信息进行统一的重命名。
问题3:点击下一页
**解决3:**模拟用户点击,获取下一页的按钮,点击它
问题4:如果程序出错停止,如何不重头开始
3.代码实现
1.首先定义一个类,主要是为了更改文件下载的默认地址,和设置全局变量,存储型号文本和pdf链接,以方便存储到excel中
'''
import os
import pandas as pd
import time
import shutilfrom selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Optionsclass MeiLin():def __init__(self,url='https://mlmall.meiling.com/meiling/pages/servicesSupport.html?_v=0.1.0#/instructions',cur_page=1,# 记录当前页面):chrome_options = Options()prefs = {"download.default_directory": "E:\downl", # 下载文件夹路径"download.prompt_for_download": False,"download.directory_upgrade": True,"safebrowsing.enabled": True}chrome_options.add_experimental_option("prefs", prefs)self.res=[]self.driver = webdriver.Chrome(options=chrome_options)self.driver.get(url)2.每一页的主要执行流程
def get_one_page_pdf(self, finish_page=85, page=0):
# finish_page为了指定结束的页面(在实际中发现,到了一定的页面,有的型号不含pdf链接了,新打开的页面结构也不是这样了)
# page 标识正在处理的页面try:while(page<finish_page+1):# 到了指定的页面进行下载# if page>2:# breakpage += 1if page < 4:# 发现前3页,点击下一页的按钮和之后的不一样,所以这里进行分情况,都是实战找出的啊# 为了偷懒就这样吧,实现功能但并不优雅button_xpath = '/html/body/div/div[2]/div/div[3]/nav/ul/li[8]/a'else:button_xpath = '/html/body/div/div[2]/div/div[3]/nav/ul/li[9]/a'# 每页有9个说明书for i in range(1, 10):one_mes = []#if i > 1:# breaktry:# 获取型号文本text_xpath = '/html/body/div/div[2]/div/div[3]/ul/li[{}]/div/div'.format(i)text = self.driver.find_element_by_xpath(text_xpath).textone_mes.append(text)# 点击一个具体的型号,打开了一个新的链接xpath = '/html/body/div/div[2]/div/div[3]/ul/li[{}]/div/div/span'.format(i)click_element = WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable((By.XPATH, xpath)))click_element.click()# 记录当前主要页面的句柄base_window = self.driver.current_window_handleall_handles = self.driver.window_handlesfor handle in all_handles:if handle != self.driver.current_window_handle:# 找到了新打开的页面,切换到新页面,得到urlself.driver.switch_to.window(handle)pdf_url = self.driver.current_url# 有的不是pdf链接,进行后缀判断if '.pdf' in str(pdf_url):one_mes.append(pdf_url)time.sleep(10)# 进行pdf下载try:click_element = WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="download"]')))click_element.click()time.sleep(10)except:print("第{}页的第{}个不是pdf网页,保存失败".format(page, i))passprint("完成第{}页的第{}个".format(page, i))self.res.append(one_mes)self.driver.close()except:print("第{}页的第{}个操作失败".format(page, i))# 如果失败了,还切回去原来的窗口,重新开始self.driver.switch_to.window(base_window)continue# 完成,关闭该页面,切换到原始窗口self.driver.switch_to.window(base_window)print("已经完成第{}页".format(page))# 点击下一页,进行下一页的下载try:click_element = WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable((By.XPATH, button_xpath)))click_element.click()time.sleep(3)except:print("无法点击下一页")breakexcept:print("while 循环终止")3.程序入口:
if __name__=="__main__":meilin = MeiLin()try:meilin.get_one_page_pdf(finish_page=85)except:passfinally:data = meilin.resdf = pd.DataFrame(data, columns=['电器型号', '说明书链接'])save_folder = 'E:\\HWR_files\\Pycharm_files\\HWR\\webcraw\\美菱.xlsx'df.to_excel(save_folder, index=False, sheet_name='匹配结果')print("------------------保存完成------------------")结果图:(只取了两页,每页取一个)
