Windows安装Hadoop
当初搭建Hadoop、Hive、HBase、Flink等这些没有截图写文,今为分享特重装。

下载Hadoop
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/
以管理员身份运行cmd
切换到所在目录

执行start winrar x -y hadoop-3.3.4.tar.gz,解压。
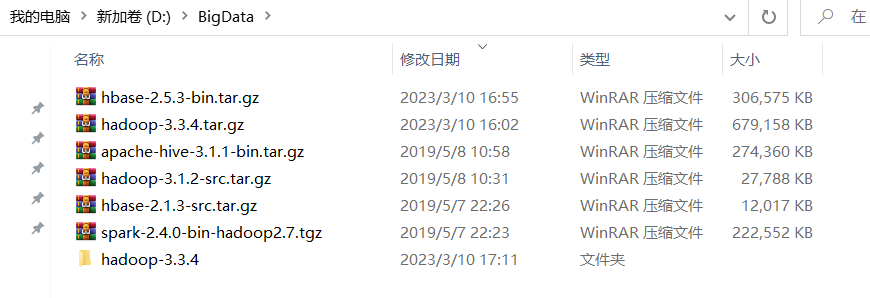
配置系统变量
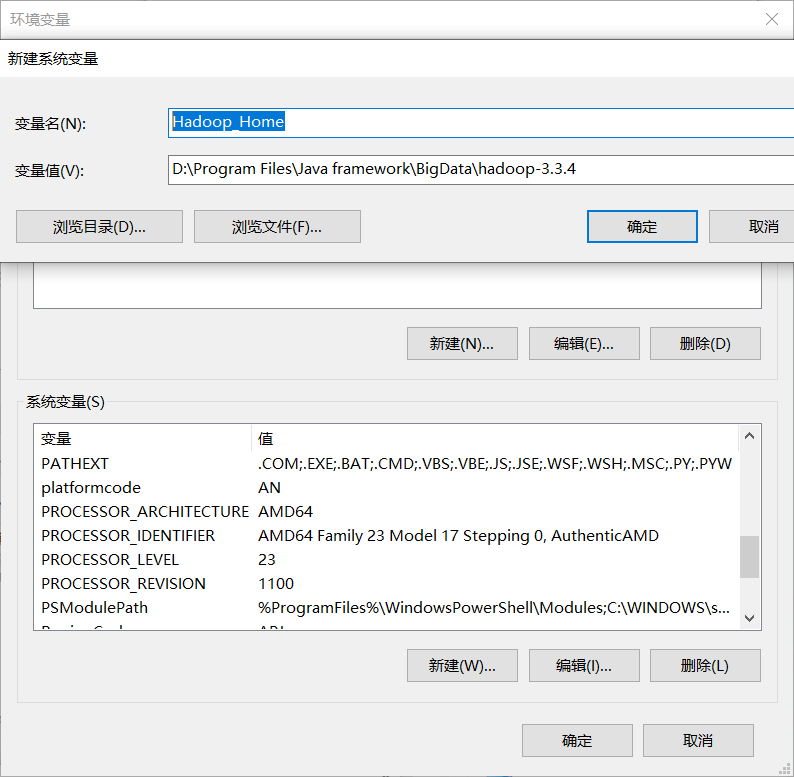
配置环境变量值
%Hadoop_Home%\bin
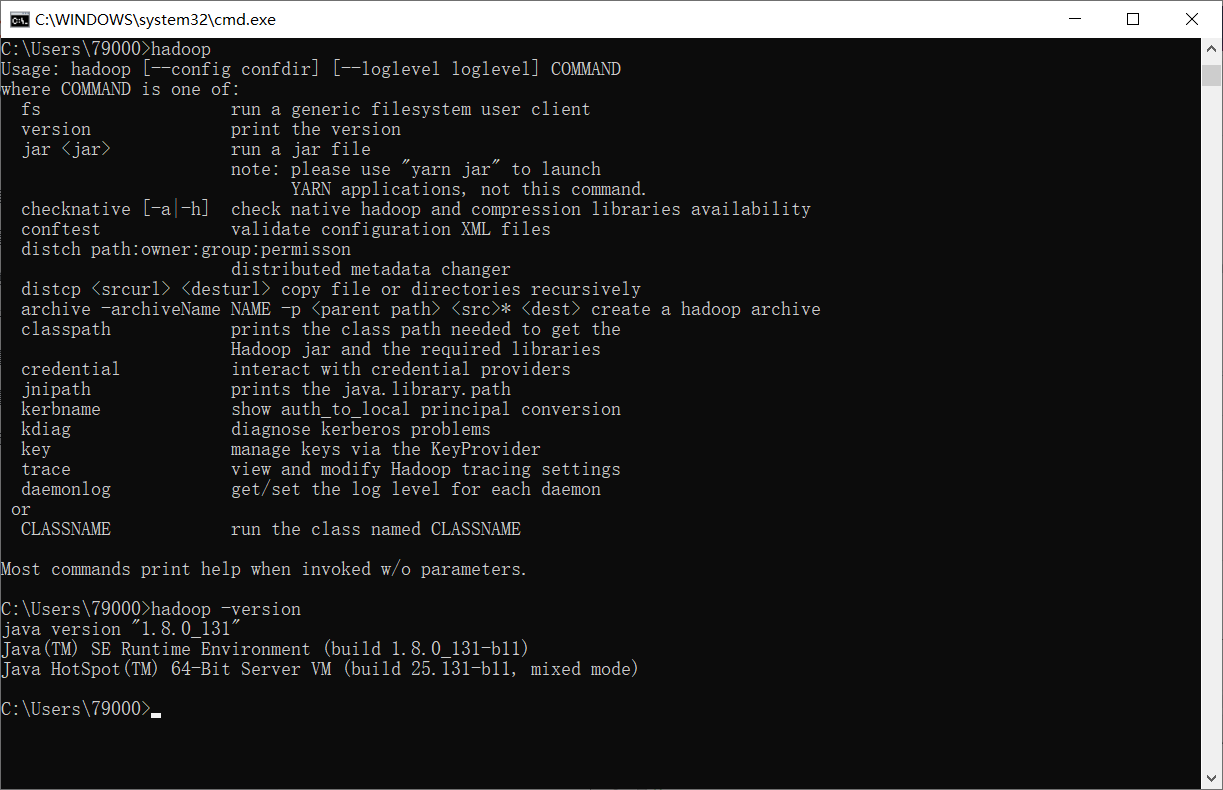
测试配置是否成功
打开cmd,输入hadoop
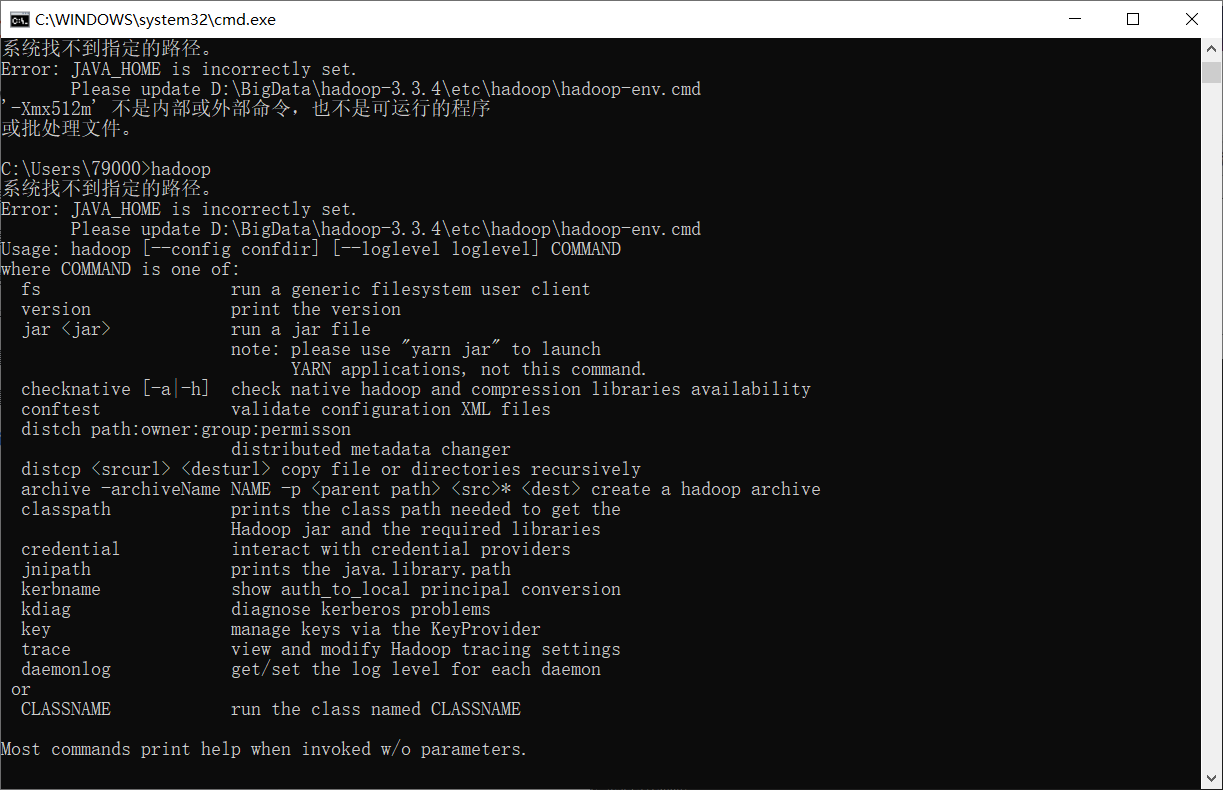
问题
系统找不到指定的路径。
Error: JAVA_HOME is incorrectly set.Please update D:\BigData\hadoop-3.3.4\etc\hadoop\hadoop-env.cmd解决
Program Files中间有空行导致报错,把Program Files改成dos软链接名PROGRA~1:
@rem set JAVA_HOME=%JAVA_HOME%
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_131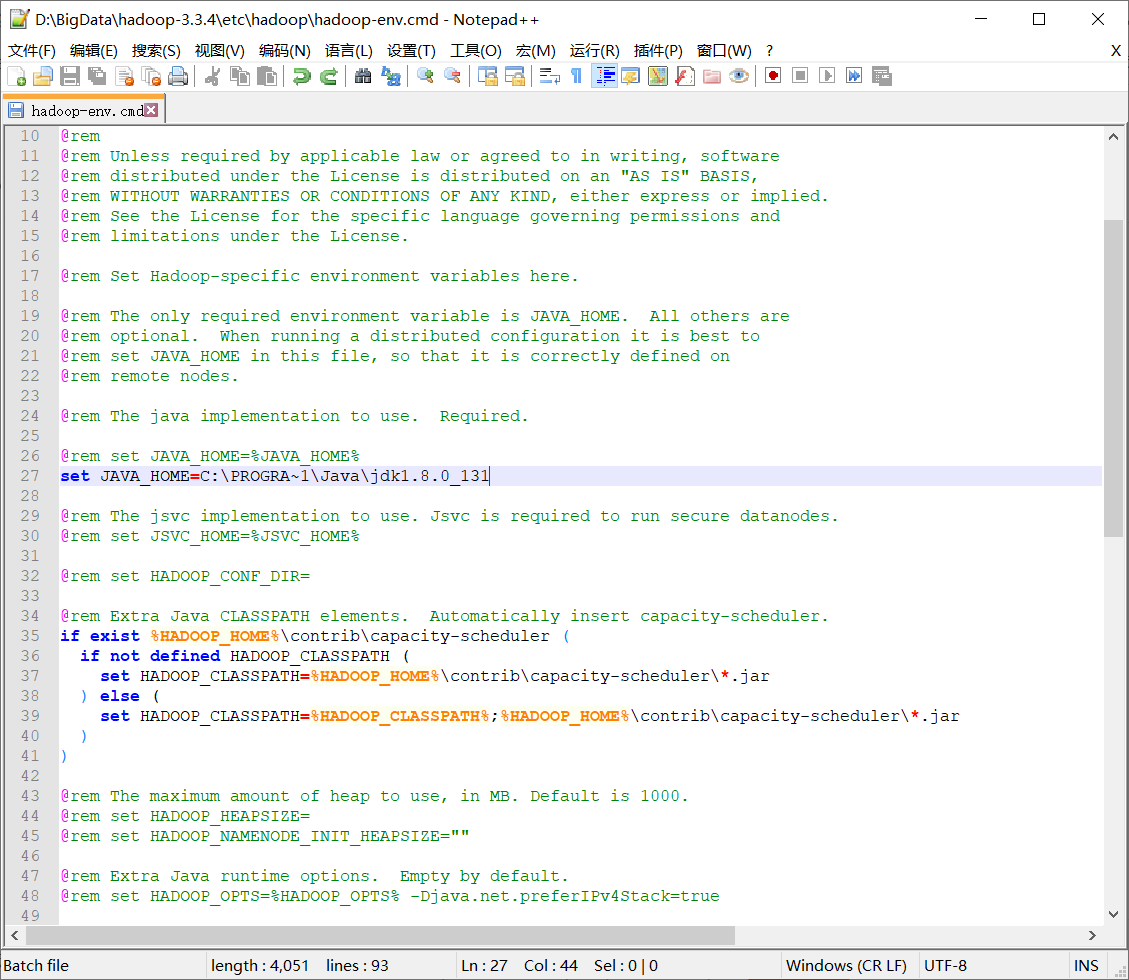
测试配置是否成功
配置 data 和 temp 文件夹
① 进入 “D:\hadoop-3.1.3”
② 新建 “data” 文件夹
③ 新建 “temp” 文件夹
④ 进入 data 文件夹,新建 “datanode” 文件夹 和 “namenode” 文件夹
配置hadoop相关配置文件
进入“D:\BigData\hadoop-3.3.4\etc\hadoop”
core-site.xml中增加
<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value>
</property>
hdfs-site.xml中增加
<property><name>dfs.replication</name><value>1</value>
</property>
<property><name>dfs.namenode.http-address</name><value>localhost:50070</value>
</property>
<property><name>dfs.namenode.name.dir</name><value>/D:/BigData/hadoop-3.3.4/data/namenode</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>/D:/BigData/hadoop-3.3.4/data/datanode</value>
</property>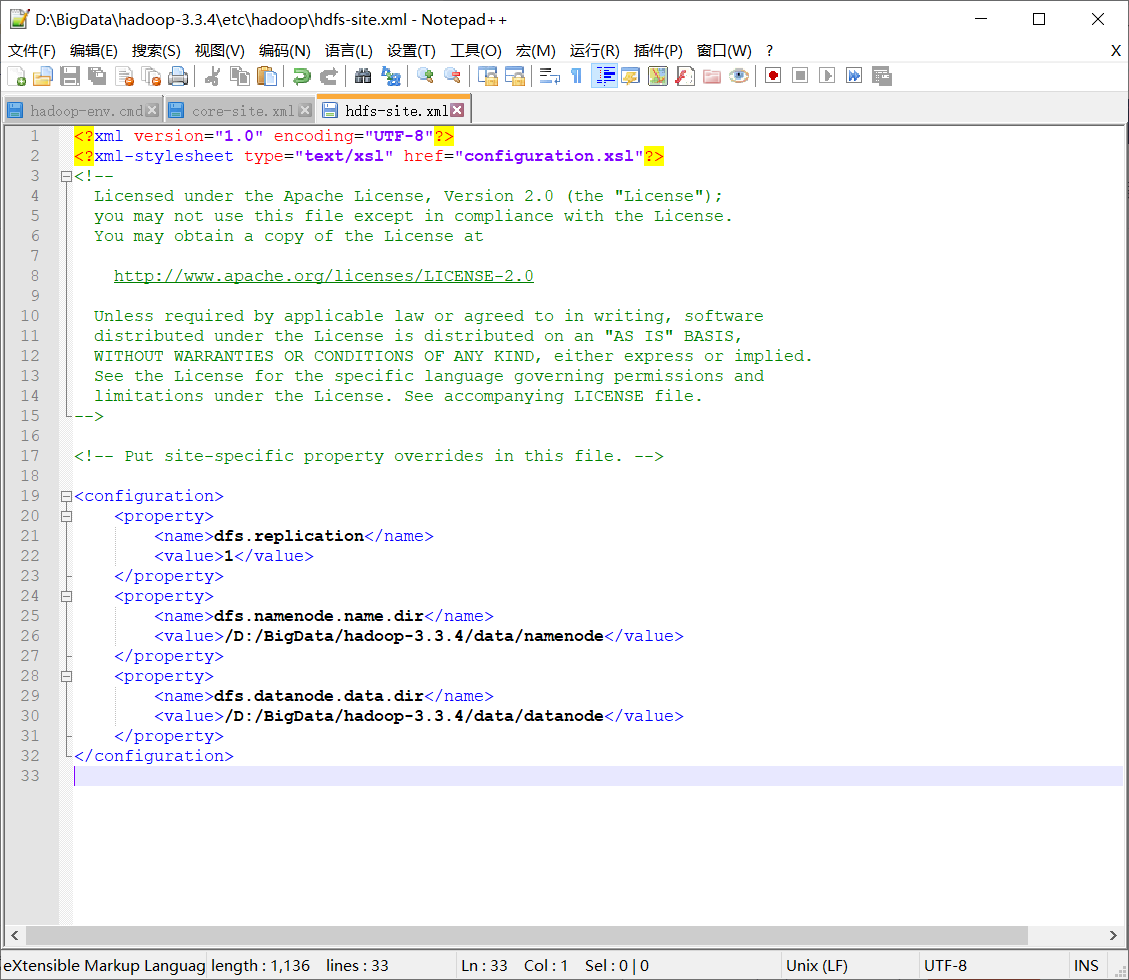
mapred-site.xml中增加
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>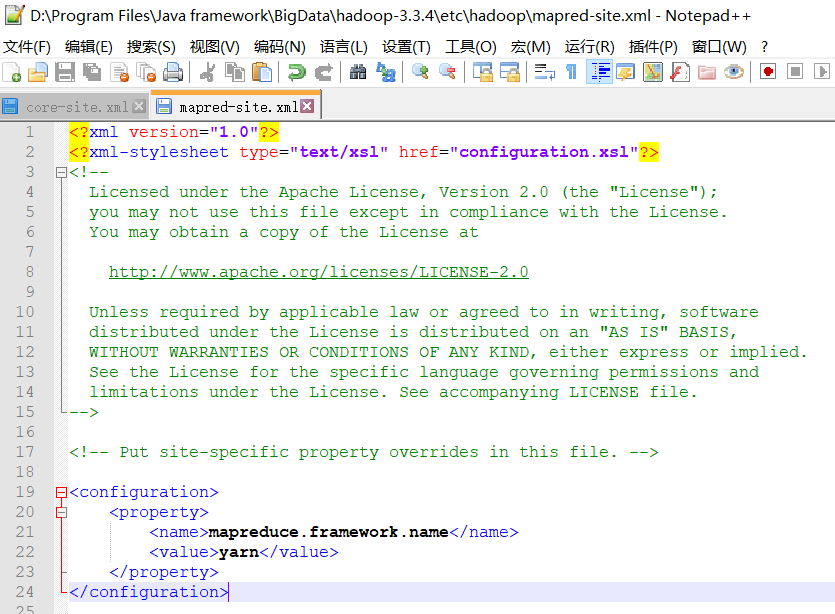
yarn-site.xml中增加
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property><name>yarn.nodemanager.resource.memory-mb</name><value>1024</value>
</property>
<property><name>yarn.nodemanager.resource.cpu-vcores</name><value>1</value>
</property>
<property><name>hadoop.tmp.dir</name><value>/D:/BigData/hadoop-3.3.4/temp/nm-local-dir</value>
</property>
<property><name>yarn.nodemanager.local-dirs</name><value>/D:/BigData/hadoop-3.3.4/temp/nm-local-dir</value>
</property>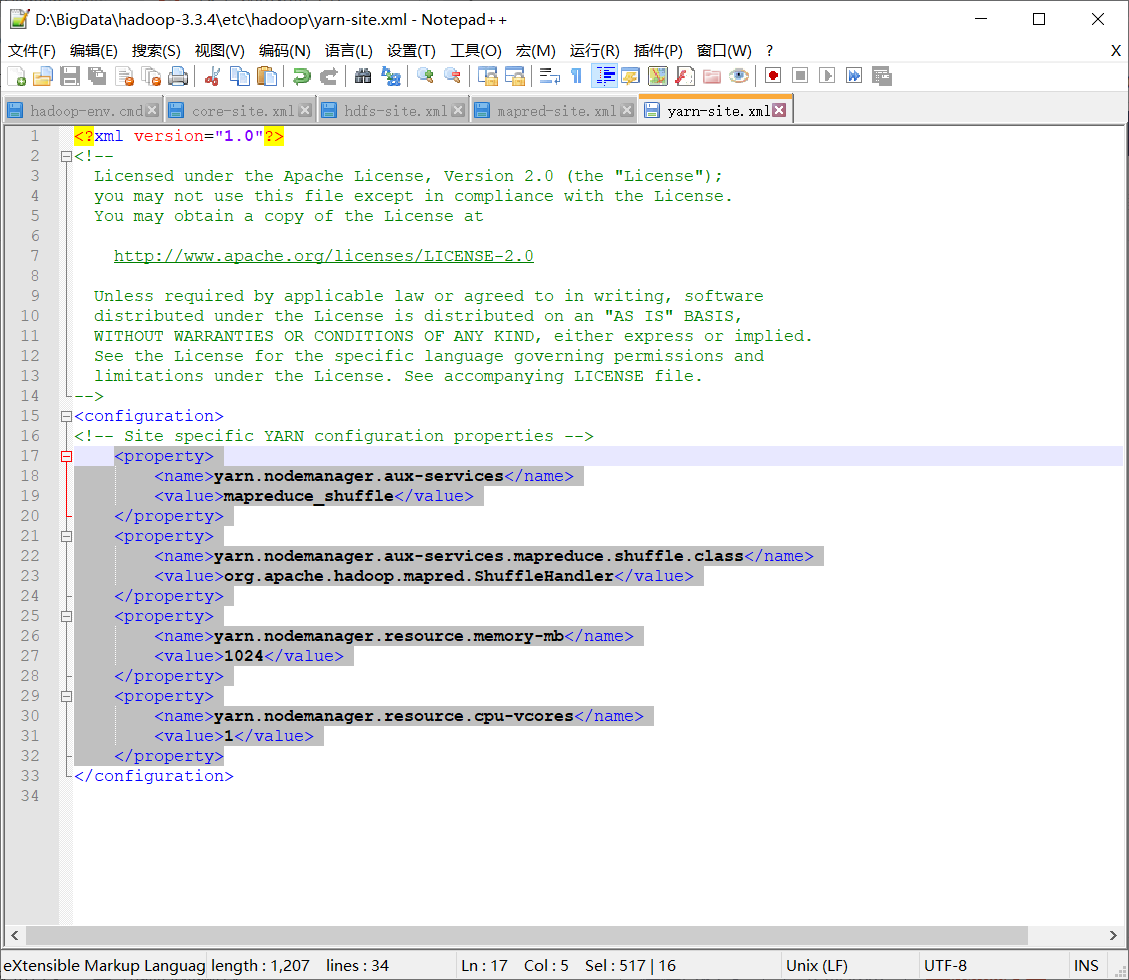
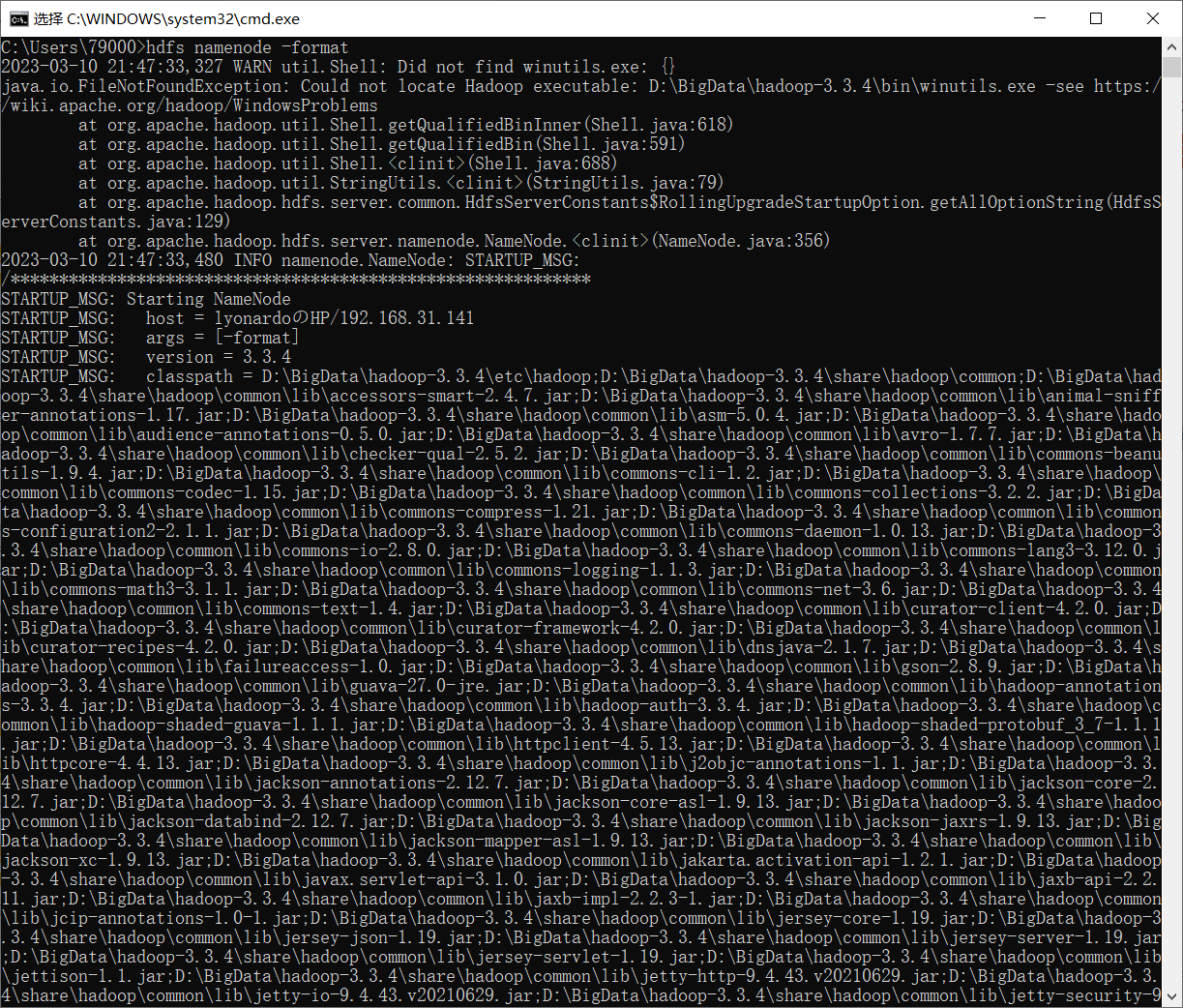
格式化 namenode 节点
组合键 “Win+R”->输入 “cmd”->“Enter” ,在弹出的窗口输入 “hdfs namenode -format” 对namenode节点进行格式化。
启动:sbin->start-all.cmd
报错: java.lang.RuntimeException: java.io.FileNotFoundException:Could not locate Hadoop executable: D:\BigData\hadoop-3.3.4\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems(本地安装的Hadoop的bin目录,缺少winutils.exe的文件。)
解决方案:
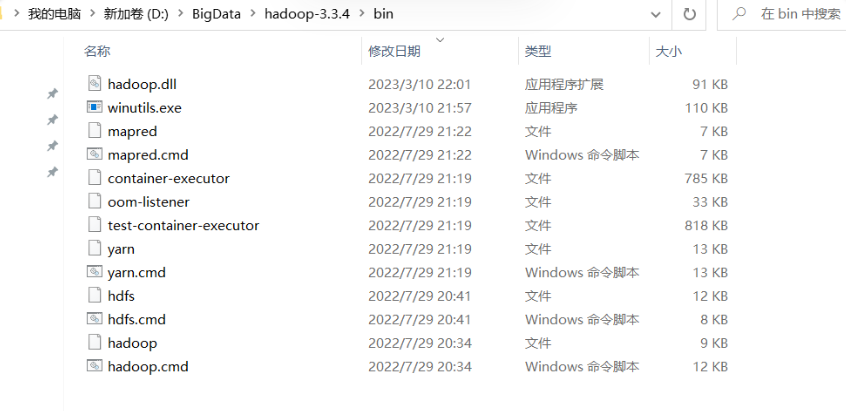
①下载winutils和hadoop.dll:https://github.com/steveloughran/winutils,
②复制到D:\BigData\hadoop-3.3.4\bin。
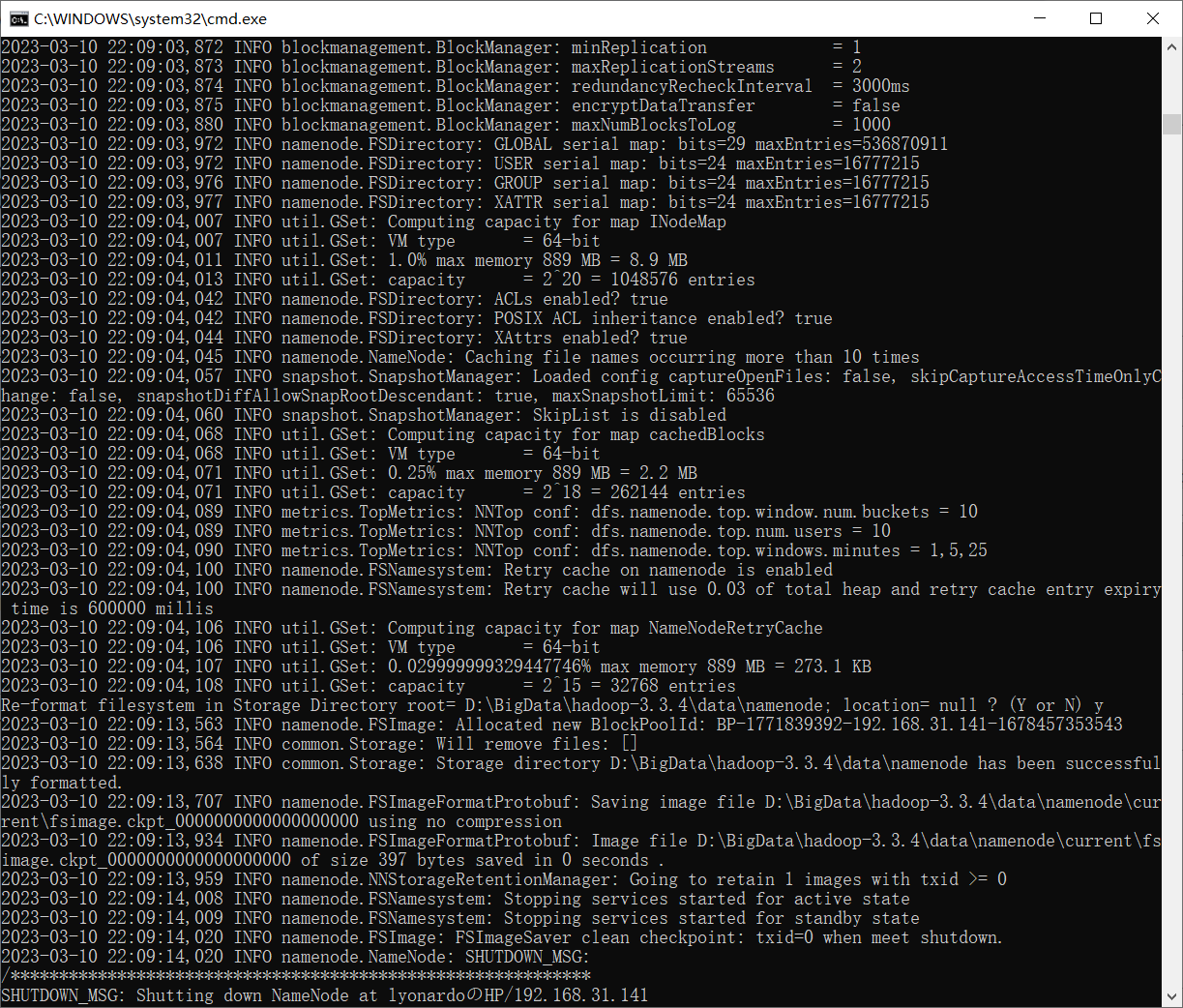
③重新执行hdfs namenode -format。
问题:Apache Hadoop Distribution yarn resourcemanager和hadoop namenode正常启动;Apache Hadoop Distribution datanode和nodemanager,报错如下:
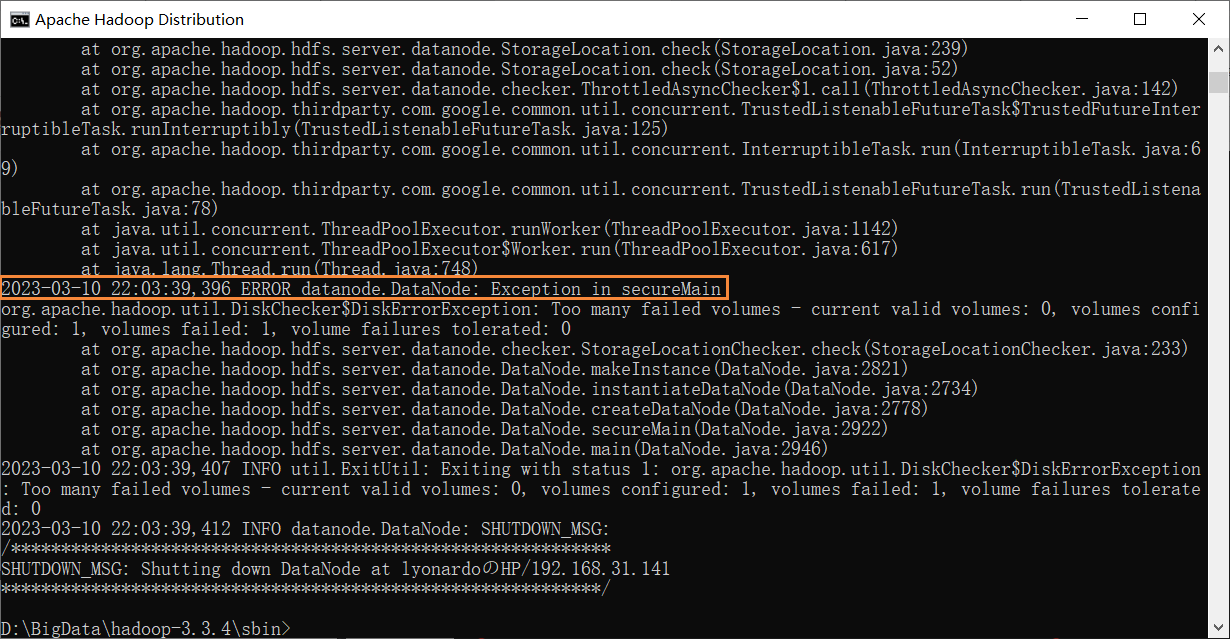
解决方案:
①datanode、tmp文件夹右键->属性->安全->编辑,完全控制;
②删除提前手动建立的datanode、tmp文件夹,由hadoop创建。
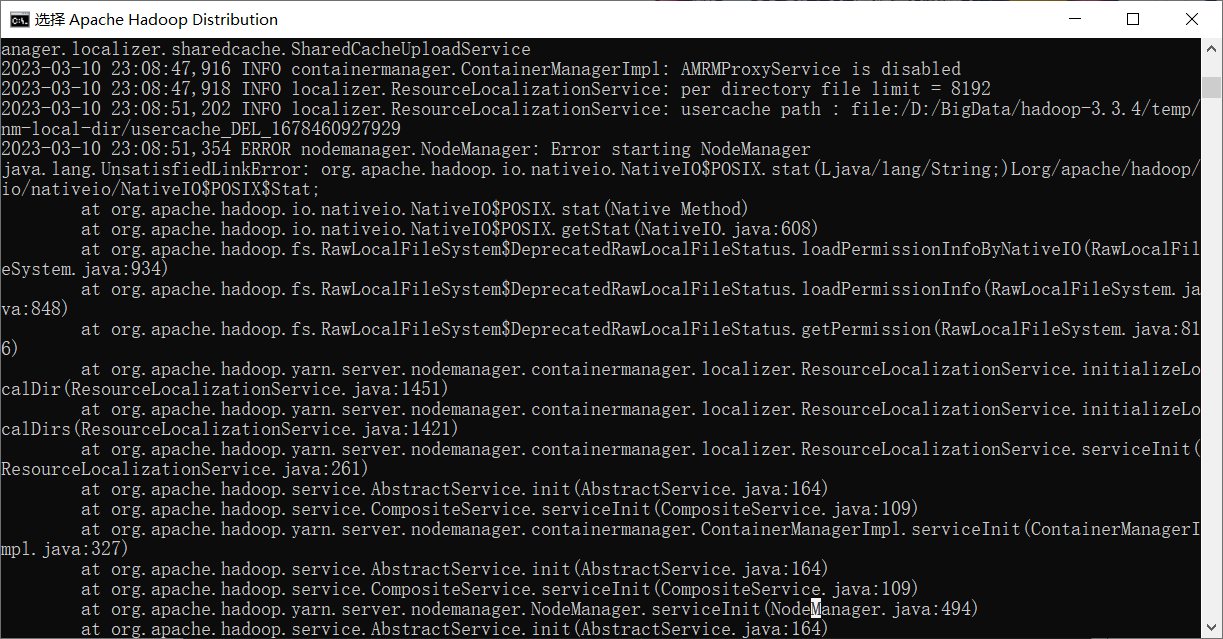
已issue,https://github.com/steveloughran/winutils/issues/25
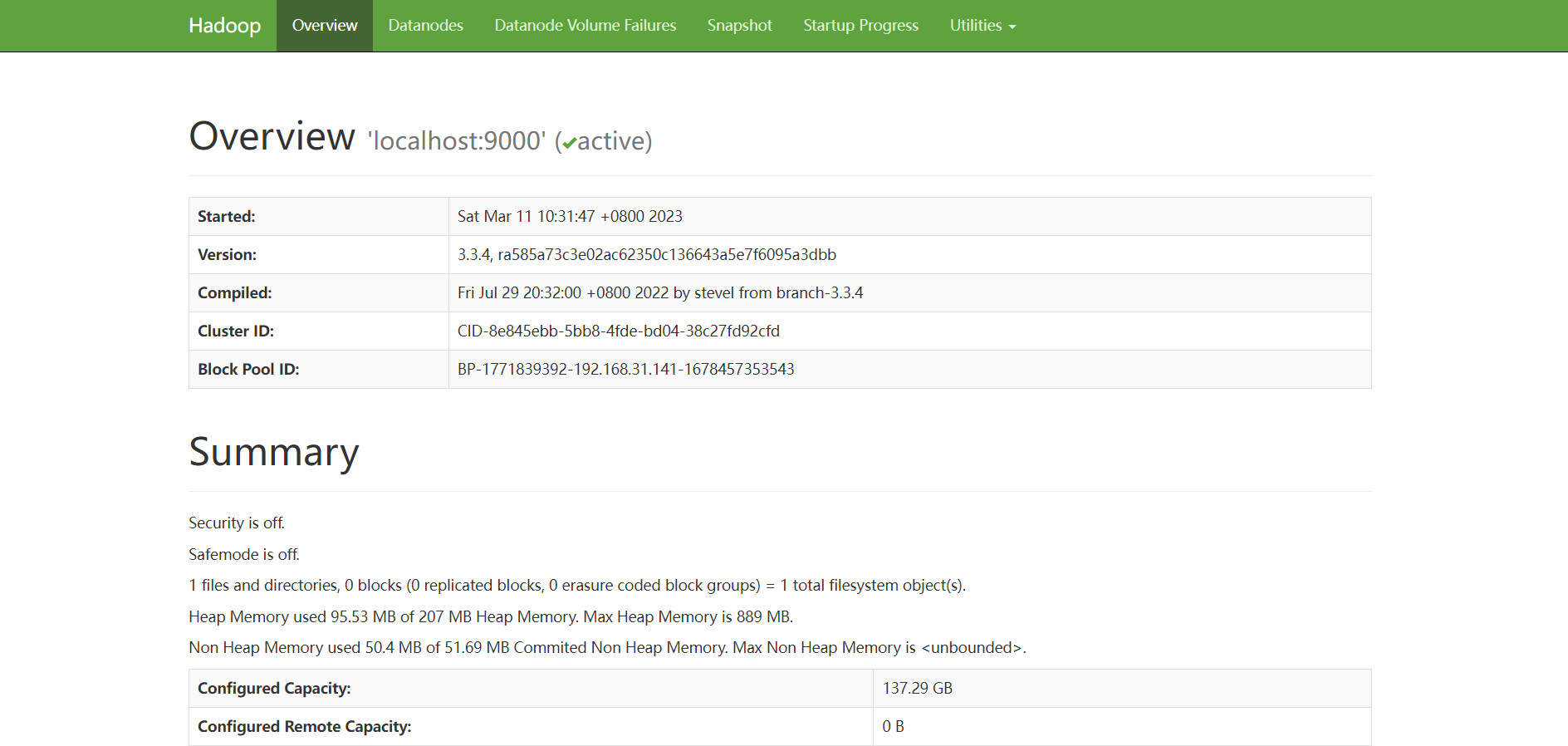
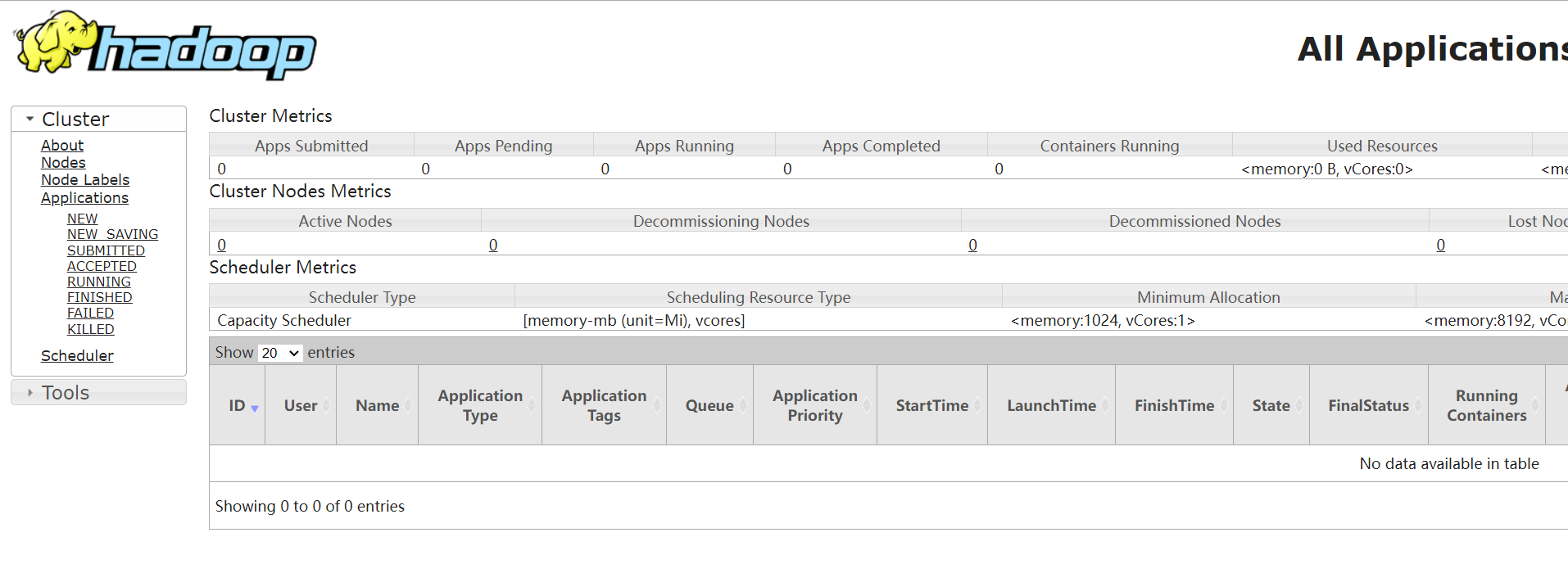
测试Hadoop
打开浏览器,
在地址栏输入http://localhost:50070查看Hadoop状态
在地址栏输入http://localhost:8088/查看cluster状态