神经网络 #数据挖掘 #Python
神经网络是一种受生物神经元系统启发的人工计算模型,用于模仿人脑的学习和决策过程。它由大量互相连接的节点(称为神经元)组成,这些节点处理和传递信息。神经网络通常包含输入层、隐藏层(可有多个)和输出层,每个层中的神经元之间通过权重相连。
- 输入层:接收数据并将其转换为可供处理的形式。
- 隐藏层:进行复杂的特征学习和抽象,通过非线性变换捕捉数据之间的复杂关系。
- 输出层:根据隐藏层的输出生成最终预测或分类结果。
训练神经网络的过程涉及到调整这些权重,以最小化预测结果与实际标签之间的误差。这个过程通常使用反向传播算法,并且在深度学习中,可以使用梯度下降等优化方法。
神经网络主要由:输入层,隐藏层,输出层构成。当隐藏层只有一层时,该网络为两层神经网络,由于输入层未做任何变换,可以不看做单独的一层。实际中,网络输入层的每个神经元代表了一个特征,输出层个数代表了分类标签的个数(在做二分类时,如果采用sigmoid分类器,输出层的神经元个数为1个;如果采用softmax分类器,输出层神经元个数为2个;如果是多分类问题,即输出类别>=3时,输出层神经元为类别个数),而隐藏层层数以及隐藏层神经元是由人工设定。
1、对数据 mouse_viral_study.csv 的建立 MLPClassifier 模型,训练和 测试数据划分比例是 8:2。
2、对比将决策树和 MLPClassifier 作为基分类器时,建立 bagging, AdaBoost 集成模型,并比较不同基分类下集成模型的分类精度。
导入数据
#载入数据
import pandas as pd
data = pd.read_csv('mouse_viral_study(1).csv')
#划分特征集和类别集
x = data.iloc[:,:-1]
y = data.iloc[:,-1]
#划分训练集和测试集
from sklearn import model_selection
x_train,x_test,y_train,y_test = model_selection.train_test_split(x,y,test_size=0.2,random_state=1)Bagging模型:
#bagging
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import BaggingClassifier
bagging = BaggingClassifier(KNeighborsClassifier(),max_samples=0.5,max_features=0.5)
bagging.fit(x_train,y_train)
pred1 = bagging.predict(x_test)
from sklearn.metrics import classification_report
#输出:Accuracy、Precisio、Recall、F1分数等信息
print('bagging模型评估报告:\n',classification_report(y_test,pred1))
print('bagging模型的准确率为:',bagging.score(x_test,y_test))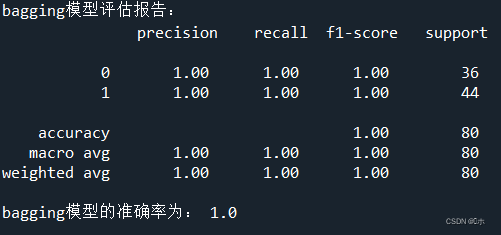
AdaBoost模型:
#adaboost
from sklearn.ensemble import AdaBoostClassifier
AB = AdaBoostClassifier(n_estimators = 10)
AB.fit(x_train,y_train)
pred3 = AB.predict(x_test)
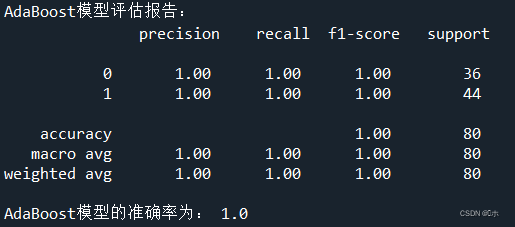
print('AdaBoost模型评估报告:\n',classification_report(y_test,pred3))
print('AdaBoost模型的准确率为:',AB.score(x_test,y_test))
MLPClassifier模型:
from sklearn.neural_network import MLPClassifier
mp = MLPClassifier(solver='lbfgs',alpha=0.5,hidden_layer_sizes=(5,2),random_state=1)
mp.fit(x_train,y_train)
MLPClassifier(activation='telu',alpha=1e-05,batch_size='auto',beta_1=0.9,beta_2=0.999,early_stopping=False,epsilon=1e-08,hidden_layer_sizes=(5,2),learning_rate='constant',learning_rate_init=0.001,max_iter=200,momentum=0.9,nesterovs_momentum=True,power_t=0.5,random_state=1,shuffle=True,solver='lbfgs',tol=0.0001,validation_fraction=0.1,verbose=False,warm_start=False)
predict3 = mp.predict(x_test)
from sklearn.metrics import accuracy_score
mp_score = accuracy_score(y_test,predict3)
mp_score
print('MLPClassifier模型评估报告:\n',classification_report(y_test,predict3))
print('MLPClassifier模型的准确率为:',mp.score(x_test,y_test))