【代码发布】Quantlab4.3:lightGBM应用于全球大类资产的多因子智能策略(代码+数据)
原创文章第566篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由"。
昨天,Quantlab整合Alpha158因子集,为机器学习大类资产配置策略做准备(代码+数据),我们完成了因子集构建,并尝试给数据做了预处理。
今天我们开始引入机器学习——树模型,以lightGBM为主。

代码已经发布。
今天,需要先 pip install lightgbm。
之前我们有分享过类似的文章:
Quantlab3.3代码发布:全新引擎 | 静态花开:年化13.9%,回撤小于15% | lightGBM实现排序学习
今天我们要把lightgbm应用于全球大类资产配置的排序上。
LightGBM 是由微软开发的一个开源机器学习库,它基于决策树算法,特别适用于处理大规模数据集。LightGBM 的核心优势在于其高性能、低内存消耗和高准确率,这些特点使得它在多个领域,包括量化投资,都非常受欢迎。
-
处理大规模数据:量化投资经常涉及到处理大量的历史交易数据和其他市场数据。LightGBM 能够有效地处理这些数据,并从中学习。
-
快速模型训练:量化策略需要快速迭代和测试。LightGBM 的训练速度使得研究人员能够快速评估不同策略的效果。
-
模型解释性:虽然不是 LightGBM 的主要优势,但决策树模型的可解释性可以帮助量化分析师理解模型的决策过程,这对于合规性和策略调整非常重要。
lightGBM有sklearn的接口:
加载内置的房价数据,做回归分析:
"""第三方库导入"""
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import r2_score, mean_squared_errorfrom sklearn.datasets import fetch_california_housing
data = fetch_california_housing()
"""训练集 验证集构建"""
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2,random_state=42)
"""模型训练"""
model = LGBMRegressor()
model.fit(X_train, y_train)def calc_metrics(model, X, y):y_pred = model.predict(X)mse = mean_squared_error(y, y_pred)r2 = r2_score(y, y_pred)print('r2:',r2,'mse:',mse)print('训练集:')
calc_metrics(model, X_train, y_train)
print("测试集")
calc_metrics(model, X_test, y_test)
训练集和测试集,在默认参数下,均获得不错的拟合:
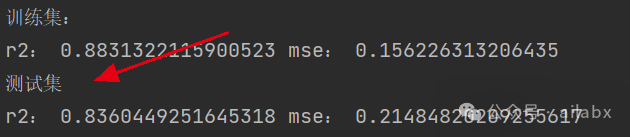
模型调参,调参后训练集r2达到0.94, 测试集也提升至0.85

调参代码如下:
def adj_params():"""模型调参"""params = {'n_estimators': [100, 200, 300, 400],# 'learning_rate': [0.01, 0.03, 0.05, 0.1],'max_depth': [5, 8, 10, 12]}other_params = {'learning_rate': 0.1, 'seed': 42}model_adj = LGBMRegressor(**other_params)# sklearn提供的调参工具,训练集k折交叉验证(消除数据切分产生数据分布不均匀的影响)optimized_param = GridSearchCV(estimator=model_adj, param_grid=params, scoring='r2', cv=5, verbose=1)# 模型训练optimized_param.fit(X_train, y_train)# 对应参数的k折交叉验证平均得分means = optimized_param.cv_results_['mean_test_score']params = optimized_param.cv_results_['params']for mean, param in zip(means, params):print("mean_score: %f, params: %r" % (mean, param))# 最佳模型参数print('参数的最佳取值:{0}'.format(optimized_param.best_params_))# 最佳参数模型得分print('最佳模型得分:{0}'.format(optimized_param.best_score_))
代码在如下位置:
我们来代入大类资产的因子数据,由于量化投资,使用的价量数据是时序数据,因些不能按照train_test_split这样随机划分,我们需要按时间分成两段。
def train(self, train_func):df = self.dfsplit_date = self.split_datedf_train = df.loc[:split_date]df_val = df.loc[split_date:]fields, names = self.alpha.get_fields_names()train_func(df_train, df_val, feature_cols=names)
总体训练代码如下:
symbols = ['CL', # 原油'^TNX', # 美十年期国债'GOLD', # 黄金'^NDX', # 纳指100'000300.SH', # 沪深300'000905.SH', # 中证500'399006.SZ', # 创业板指数'000012.SH', # 国债指数'000832.SH', # 中证转债指数'HSI', # 香港恒生'N225', # 日经225'GDAXI' # 德国DAX指数 ] m = ModelTrainer(symbols=symbols, alpha=Alpha158()) from models.lightgbm_models import trainm.train(train_func=train)
在未进行数据预处理时,容易出现过拟合的情况:

代码在如下位置:
历史文章:

Quantlab整合Alpha158因子集,为机器学习大类资产配置策略做准备(代码+数据)
【研报复现】年化27.1%,人工智能多因子大类资产配置策略之benchmark
AI量化实验室——2024量化投资的星辰大海