PyMuPDF 操作手册 - 01 从PDF中提取文本
文章目录
- 一、打开文件
- 二、从 PDF 中提取文本
- 2.1 文本基础操作
- 2.2 文本进阶操作
- 2.2.1 从任何文档中提取文本
- 2.2.2 如何将文本提取为 Markdown
- 2.2.3 如何从页面中提取键值对
- 2.2.4 如何从矩形中提取文本
- 2.2.5 如何以自然阅读顺序提取文本
- 2.2.6 如何从文档中提取表格内容
- 2.2.6.1 提取 1 页的 PDF,其中包含中文文本和两个表格
- 2.2.6.2 读取多页 PDF,并联接已在这些页面中分段的表的各个部分
- 2.2.6.3 确认支持 PyMuPDF 的表格功能用于常规文档(比较 XPS vs. PDF)
- 2.2.6.4 使用PyMuPDF进行表分析1
- 2.2.6.5 使用PyMuPDF进行表分析2
- 2.2.7 如何标记提取的文本
- 2.2.8 如何标记搜索到的文本
- 2.2.9 如何标记非水平文本
- 2.2.10 如何分析字体特征
- 2.2.11 如何插入文本
- 2.2.11.1 如何编写文本行
- 2.2.11.2 如何填充文本框
- 2.2.11.3 如何用 HTML 文本填充框
- 2.2.11.3.1 如何输出 HTML 表格和图像
- 2.2.11.3.2 如何输出世界语言
- 2.2.11.3.3 如何指定自己的字体
- 2.2.11.3.4 如何请求文本对齐
- 2.2.11.4 如何提取带有颜色的文本
- 2.2.12 获取页面链接
一、打开文件
https://pymupdf.readthedocs.io/en/latest/the-basics.html#extract-images-from-a-pdf
import pymupdfdoc = pymupdf.open("a.pdf") # open a document
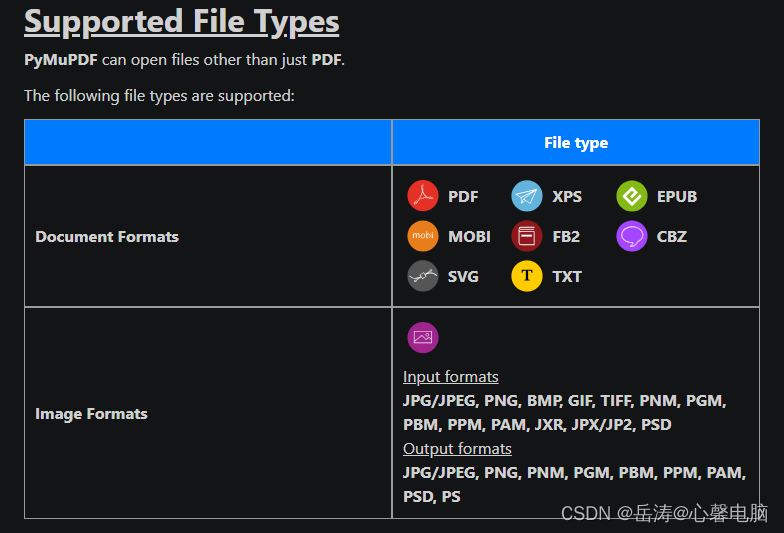
二、从 PDF 中提取文本
https://pymupdf.readthedocs.io/en/latest/the-basics.html#