ctr/cvr预估之FM模型
ctr/cvr预估之FM模型
在数字化时代,广告和推荐系统的质量直接影响着企业的营销成效和用户体验。点击率(CTR)和转化率(CVR)预估作为这些系统的核心组件,其准确性至关重要。传统的机器学习方法,如逻辑回归,虽然在某些场景下表现良好,但在处理大规模稀疏数据时往往力不从心。在这样的背景下,因子分解机(Factorization Machines, FM)模型应运而生,以其卓越的性能和对稀疏数据的天然适应性,成为CTR/CVR预估领域的一颗新星。
文章目录
- ctr/cvr预估之FM模型
- 一、什么是FM模型
- 二、FM模型提出背景
- 三、FM模型原理
- 四、FM模型注意事项
- 五、FM模型的核心参数
- 六、FM模型的关键优势
- 七、FM模型实现代码
一、什么是FM模型
因子分解机(Factorization Machines, FM)是一种先进的机器学习模型,专为处理具有大量特征的稀疏数据集而设计。FM模型最初由Steffen Rendle在2010年提出,它结合了线性模型的可解释性和因子分解模型的泛化能力。
二、FM模型提出背景
FM模型的提出背景主要是为了解决稀疏数据场景下的特征组合问题。在许多实际应用中,如推荐系统、广告点击率预测等,经常会遇到高维稀疏数据,传统的机器学习算法如LR(Logistic Regression)在处理这类数据时会遇到一些挑战:
-
LR模型未考虑特征之间的关系:LR模型要求特征之间相互独立,但这在实际应用当中很难满足,并且LR模型无法有效捕捉特征之间的交互作用。
-
高维稀疏问题:高维稀疏矩阵是实际当中非常常见的问题,会导致计算量过大,计算成本高,模型收敛缓慢。
针对上述问题,FM模型采用了因子分解技术来减少模型参数,并能够捕捉特征间的交互作用,同时保持计算的高效性。FM模型的核心思想是将高维的特征向量映射到低维空间,通过隐向量的点积来表示特征间的交互,从而在稀疏数据上实现有效的特征组合和参数共享。FM模型的提出,为处理大规模稀疏数据提供了一种新的解决方案,并且在广告、推荐等领域得到了广泛的应用。它不仅能够处理线性关系,还能够通过特征交互捕捉非线性模式,这使得FM模型在许多场景下都能够取得良好的预测效果。
三、FM模型原理
FM模型假设特征之间两两相关,获取特征之间的交叉项参与建模(主要针对离散特征之间的交叉,尤其是对于那些在大规模数据集中常见的稀疏离散特征):
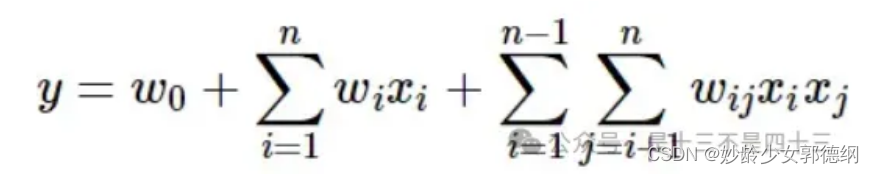
对w进行分解,得到:
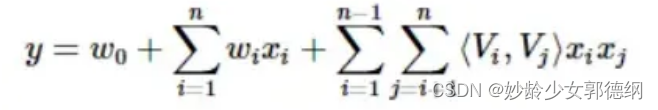
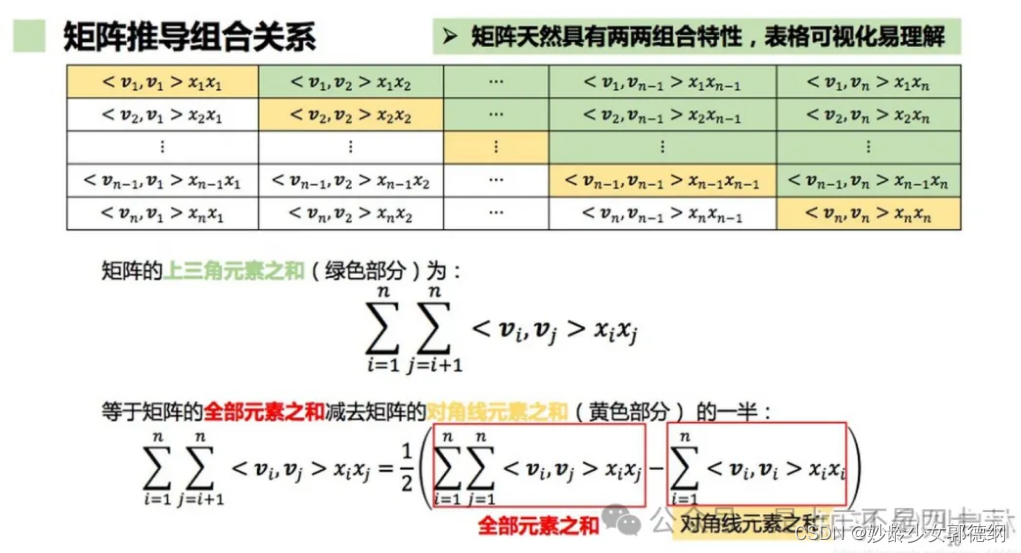
化简后面的二阶项:
最终模型表达式为:
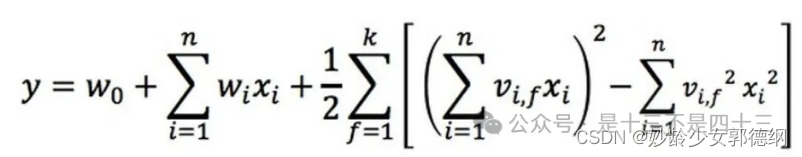
经过化简,模型的时间复杂度由O(kn^2)下降到O(kn),并且在高维稀疏数据场景下,很多特征为0,只需要计算非零特征,极大提高了计算效率。
四、FM模型注意事项
-
对于长度不一致的特征,FM模型通过将这些特征转换为固定长度的向量来处理它们之间的交叉项,通常通过特征的嵌入(Embedding)实现。
-
对于多特征的场景,一般会将各个特征嵌入到相同的维度,然后进行拼接,拼接后的总维度就是各个嵌入维度之和,在FM层处理时,关注的是处理后的嵌入特征,而非原始的输入维度。
-
FMLayer层的关键在于计算两个部分:一是所有嵌入向量的和的平方,二是所有嵌入向量的平方的和。然后,将前者减去后者,乘以0.5得到交叉项。
五、FM模型的核心参数
1、隐向量维度(Factorization Dimension):这是FM模型中最重要的参数之一,决定了特征交互的维度。较大的维度可以捕获更复杂的交互关系,但同时也会增加模型的复杂度和过拟合的风险。
2、正则化参数(Regularization):包括针对一阶线性项的正则化参数和针对隐向量的正则化参数。正则化有助于防止模型过拟合,提高模型的泛化能力。常见的正则化方法有L1正则化和L2正则化。
3、学习率(Learning Rate):在梯度下降或其他优化算法中使用的学习率决定了每次参数更新的步长。合适的学习率对于快速收敛和避免过度震荡非常重要。
4、迭代次数(Number of Epochs):训练过程中数据集遍历的次数。过多的迭代可能导致过拟合,而过少的迭代可能导致欠拟合。
5、批量大小(Batch Size):在基于批量的优化方法中,批量的大小决定了每次参数更新考虑的样本数量。批量的大小会影响训练的速度和稳定性。
6、初始化方法(Initialization Method):模型参数的初始值设置方法,合适的初始化可以提高模型的收敛速度和性能。
7、优化算法(Optimization Algorithm):用于训练模型的优化算法,如SGD(随机梯度下降)、Adam、RMSprop等,不同的优化算法可能会影响模型的收敛速度和最终性能。
除了这些核心参数外,还有一些其他可调节的参数,如早停法(Early Stopping)的阈值设置,用于防止过拟合的Dropout率等。调整这些参数需要依据具体的应用场景和数据集特性,通常通过交叉验证等技术来确定最优参数设置。
六、FM模型的关键优势
- 高维稀疏数据的处理能力:通过因子分解,FM可以在稀疏数据中学习到特征间的隐含关系,有效减少了模型参数的数量,使得模型可以在高维空间中有效运行。
- 特征交互的自动学习:FM能够自动学习不同特征之间的交互关系,而不需要手动创建交互特征,这在处理具有大量特征的数据集时尤其有用。
- 灵活性:FM模型不仅可以用于预测任务(如回归和分类),还可以适应各种类型的输入数据(如数值型、类别型等),并且可以轻松地扩展到更高阶的交互。
七、FM模型实现代码
详细实现代码见公众号文章(6月20号)~
