创建进程的常用方式
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501
在Python中有多个模块可以创建进程,比较常用的有os.fork()函数、multiprocessing模块和Pool进程池。由于os.fork()函数只适用于Unix/Linux/Mac系统上运行,在Windows操作系统中不可用,所以本章重点介绍multiprocessing模块和Pool进程池这2个跨平台模块。
1 使用multiprocessing模块创建进程
multiprocessing模块提供了一个Process类来代表一个进程对象,语法如下:
Process([group [, target [, name [, args [, kwargs]]]]])
Process类的参数说明如下:
l group:参数未使用,值始终为None。
l target:表示当前进程启动时执行的可调用对象。
l name:为当前进程实例的别名。
l args:表示传递给target函数的参数元组。
l kwargs:表示传递给target函数的参数字典。
例如,实例化Process类,执行子进程,代码如下:
from multiprocessing import Process # 导入模块
# 执行子进程代码
def test(interval):
print('我是子进程')
# 执行主程序
def main():
print('主进程开始')
p = Process(target=test,args=(1,)) # 实例化Process进程类
p.start() # 启动子进程
print('主进程结束')
if __name__ == '__main__':
main()
运行结果如下:
主进程开始
主进程结束
我是子进程
注意:由于IDLE自身的问题,运行上述代码时,不会输出子进程内容,所以使用命令行方式运行Python代码,即在文件目录下,用“python + 文件名”方式,如图3所示。
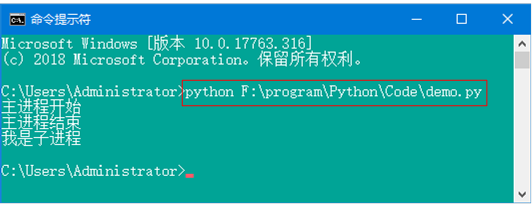
图3 使用命令行运行python文件
上述代码中,先实例化Process类,然后使用p.start()方法启动子进程,开始执行test()函数。
Process的实例p常用的方法除start()外,还有如下常用方法:
l is_alive():判断进程实例是否还在执行。
l join([timeout]):是否等待进程实例执行结束,或等待多少秒。
l start():启动进程实例(创建子进程)。
l run():如果没有给定target参数,对这个对象调用start()方法时,就将执行对象中的run()方法。
l terminate():不管任务是否完成,立即终止。
Process类还有如下常用属性:
l name:当前进程实例别名,默认为Process-N,N为从1开始递增的整数。
l pid:当前进程实例的PID值。
![]()
实例01 创建两个子进程,并记录子进程运行时间
下面通过一个简单示例演示Process类的方法和属性的使用,创建2个子进程,分别使用os模块和time模块输出父进程和子进程的ID以及子进程的时间,并调用Process类的name和pid属性,代码如下:
# -*- coding:utf-8 -*-
from multiprocessing import Process
import time
import os
# 两个子进程将会调用的两个方法
def child_1(interval):
print("子进程(%s)开始执行,父进程为(%s)" % (os.getpid(), os.getppid()))
t_start = time.time() # 计时开始
time.sleep(interval) # 程序将会被挂起interval秒
t_end = time.time() # 计时结束
print("子进程(%s)执行时间为'%0.2f'秒"%(os.getpid(),t_end - t_start))
def child_2(interval):
print("子进程(%s)开始执行,父进程为(%s)" % (os.getpid(), os.getppid()))
t_start = time.time() # 计时开始
time.sleep(interval) # 程序将会被挂起interval秒
t_end = time.time() # 计时结束
print("子进程(%s)执行时间为'%0.2f'秒"%(os.getpid(),t_end - t_start))
if __name__ == '__main__':
print("------父进程开始执行-------")
print("父进程PID:%s" % os.getpid()) # 输出当前程序的PID
p1=Process(target=child_1,args=(1,)) # 实例化进程p1
p2=Process(target=child_2,name="mrsoft",args=(2,)) # 实例化进程p2
p1.start() # 启动进程p1
p2.start() # 启动进程p2
# 同时父进程仍然往下执行,如果p2进程还在执行,将会返回True
print("p1.is_alive=%s"%p1.is_alive())
print("p2.is_alive=%s"%p2.is_alive())
# 输出p1和p2进程的别名和PID
print("p1.name=%s"%p1.name)
print("p1.pid=%s"%p1.pid)
print("p2.name=%s"%p2.name)
print("p2.pid=%s"%p2.pid)
print("------等待子进程-------")
p1.join() # 等待p1进程结束
p2.join() # 等待p2进程结束
print("------父进程执行结束-------")
上述代码中,第一次实例化Process类时,会为name属性默认赋值为“Process-1”,第二次则默认为“Process-2”,但是由于在实例化进程p2时,设置了name属性为“mrsoft”,所以p2.name的值为“mrsoft”而不是“Process-2”。程序运行流程示意图如图4所示,运行结果如图5所示。
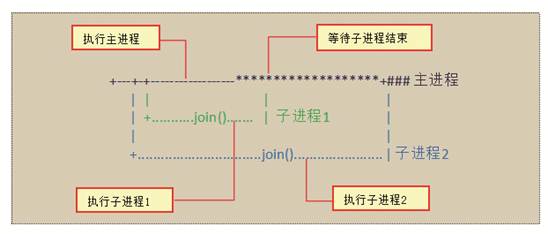
图4 运行流程示意图

图5 创建2个子进程
注意:读者运行时,进程的PID值会与图5不同,这与电脑有关,读者不必在意。
2 使用Process子类创建进程
对于一些简单的小任务,通常使用Process(target=test)方式实现多进程。但是如果要处理复杂任务的进程,通常定义一个类,使其继承Process类,每次实例化这个类的时候,就等同于实例化一个进程对象。下面,通过一个示例来学习一下如何通过使用Process子类创建多个进程。
![]()
实例02 使用Process子类创建两个子进程,并记录子进程运行时间
使用Process子类方式创建2个子进程,分别输出父、子进程的PID,以及每个子进程的状态和运行时间,代码如下:
# -*- coding:utf-8 -*-
from multiprocessing import Process
import time
import os
# 继承Process类
class SubProcess(Process):
# 由于Process类本身也有__init__初始化方法,这个子类相当于重写了父类的这个方法
def __init__(self,interval,name=''):
Process.__init__(self) # 调用Process父类的初始化方法
self.interval = interval # 接收参数interval
if name: # 判断传递的参数name是否存在
self.name = name # 如果传递参数name,则为子进程创建name属性,否则使用默认属性
# 重写了Process类的run()方法
def run(self):
print("子进程(%s) 开始执行,父进程为(%s)"%(os.getpid(),os.getppid()))
t_start = time.time()
time.sleep(self.interval)
t_stop = time.time()
print("子进程(%s)执行结束,耗时%0.2f秒"%(os.getpid(),t_stop-t_start))
if __name__=="__main__":
print("------父进程开始执行-------")
print("父进程PID:%s" % os.getpid()) # 输出当前程序的ID
p1 = SubProcess(interval=1,name='mrsoft')
p2 = SubProcess(interval=2)
# 对一个不包含target属性的Process类执行start()方法,就会运行这个类中的run()方法
# 所以这里会执行p1.run()
p1.start() # 启动进程p1
p2.start() # 启动进程p2
# 输出p1和p2进程的执行状态,如果真正进行,返回True;否则返回False
print("p1.is_alive=%s"%p1.is_alive())
print("p2.is_alive=%s"%p2.is_alive())
# 输出p1和p2进程的别名和PID
print("p1.name=%s"%p1.name)
print("p1.pid=%s"%p1.pid)
print("p2.name=%s"%p2.name)
print("p2.pid=%s"%p2.pid)
print("------等待子进程-------")
p1.join() # 等待p1进程结束
p2.join() # 等待p2进程结束
print("------父进程执行结束-------")
上述代码中,定义了一个SubProcess子类,继承multiprocess.Process父类。SubProcess子类中定义了2个方法:__init__()初始化方法和run()方法。在__init()__初识化方法中,调用multiprocess.Process父类的__init__()初始化方法,否则父类初始化方法会被覆盖,无法开启进程。此外,在SubProcess子类中并没有定义start()方法,但在主进程中却调用了start()方法,此时就会自动执行SubPorcess类的run()方法。运行结果如图6所示。
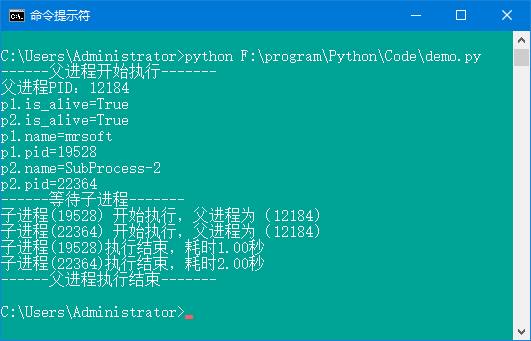
图6 使用Porcess子类创建进程
3 使用进程池Pool创建进程
在16.2.1小节和16.2.2小节中,我们使用Process类创建了2个进程。如果要创建几十个或者上百个进程,则需要实例化更多个Process类。有没有更好的创建进程的方式解决这类问题呢?答案就是使用multiprocessing模块提供的Pool类,即Pool进程池。
为了更好的理解进程池,可以将进程池比作水池,如图7所示。我们需要完成放满10个水盆的水的任务,而在这个水池中,最多可以安放3个水盆接水,也就是同时可以执行3个任务,即开启3个进程。为更快完成任务,现在打开3个水龙头开始放水,当有一个水盆的水接满时,即该进程完成1个任务,我们就将这个水盆的水倒入水桶中,然后继续接水,即执行下一个任务。如果3个水盆每次同时装满水,那么在放满第9盆水后,系统会随机分配1个水盆接水,另外2个水盆空闲。

图7 进程池示意图
接下来,先来了解一下Pool类的常用方法。常用方法及说明如下:
l apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func()函数(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func()函数的参数列表,kwds为传递给func()函数的关键字参数列表。
l apply(func[, args[, kwds]]):使用阻塞方式调用func()函数。
l close():关闭Pool,使其不再接受新的任务。
l terminate():不管任务是否完成,立即终止。
l join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用。
在上面的方法提到apply_async()使用非阻塞方式调用函数,而apply()使用阻塞方式调用函数。那么什么又是阻塞和非阻塞呢?在图8中,分别使用阻塞方式和非阻塞方式执行3个任务。如果使用阻塞方式,必须等待上一个进程退出才能执行下一个进程,而使用非阻塞方式,则可以并行执行3个进程。

图8 阻塞与非阻塞示意图
![]()
实例03 使用进程池创建多进程
下面通过一个示例演示一下如何使用进程池创建多进程。这里模拟水池放水的场景,定义一个进程池,设置最大进程数为3。然后使用非阻塞方式执行10个任务,查看每个进程执行的任务。具体代码如下:
# -*- coding=utf-8 -*-
from multiprocessing import Pool
import os, time
def task(name):
print('子进程(%s)执行task %s ...' % ( os.getpid() ,name))
time.sleep(1) # 休眠1秒
if __name__=='__main__':
print('父进程(%s).' % os.getpid())
p = Pool(3) # 定义一个进程池,最大进程数3
for i in range(10): # 从0开始循环10次
p.apply_async(task, args=(i,)) # 使用非阻塞方式调用task()函数
print('等待所有子进程结束...')
p.close() # 关闭进程池,关闭后p不再接收新的请求
p.join() # 等待子进程结束
print('所有子进程结束.')
运行结果如图9所示,从图9可以看出PID为11488的子进程执行了4个任务,而其余2个子进程分别执行了3个任务。
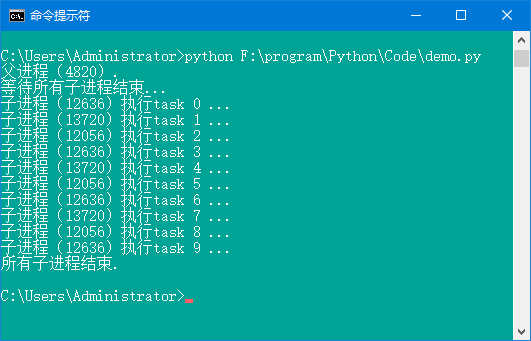
图9 使用进程池创建进程
