Linux网络-HttpServer的实现
文章目录
- 前言
- 一、请求报文的解析
- URL的解析
- 二、响应报文的发送
- Content-Lenth
- Conten-Type
- Cookie和Set-Cookie
- Cookie的风险
- 三、尝试发送一个HTML网页
- 404网页
- Location 重定向
- 四、浏览器的多次请求行为
- 总结
前言
之前我们简单理解了一下Http协议,本章我们将在LInux下使用Socket编程自主完成一个HttpServer。 可以做到接收Http报文数据,加以解析再向远端发送Http报文数据。
之前写过很多遍的网络套接字编程代码就不再重复写了,这里直接写关于HttpServer的代码
一、请求报文的解析
上一章我们讲了,请求报文主要分为 请求行,请求报头,请求正文。
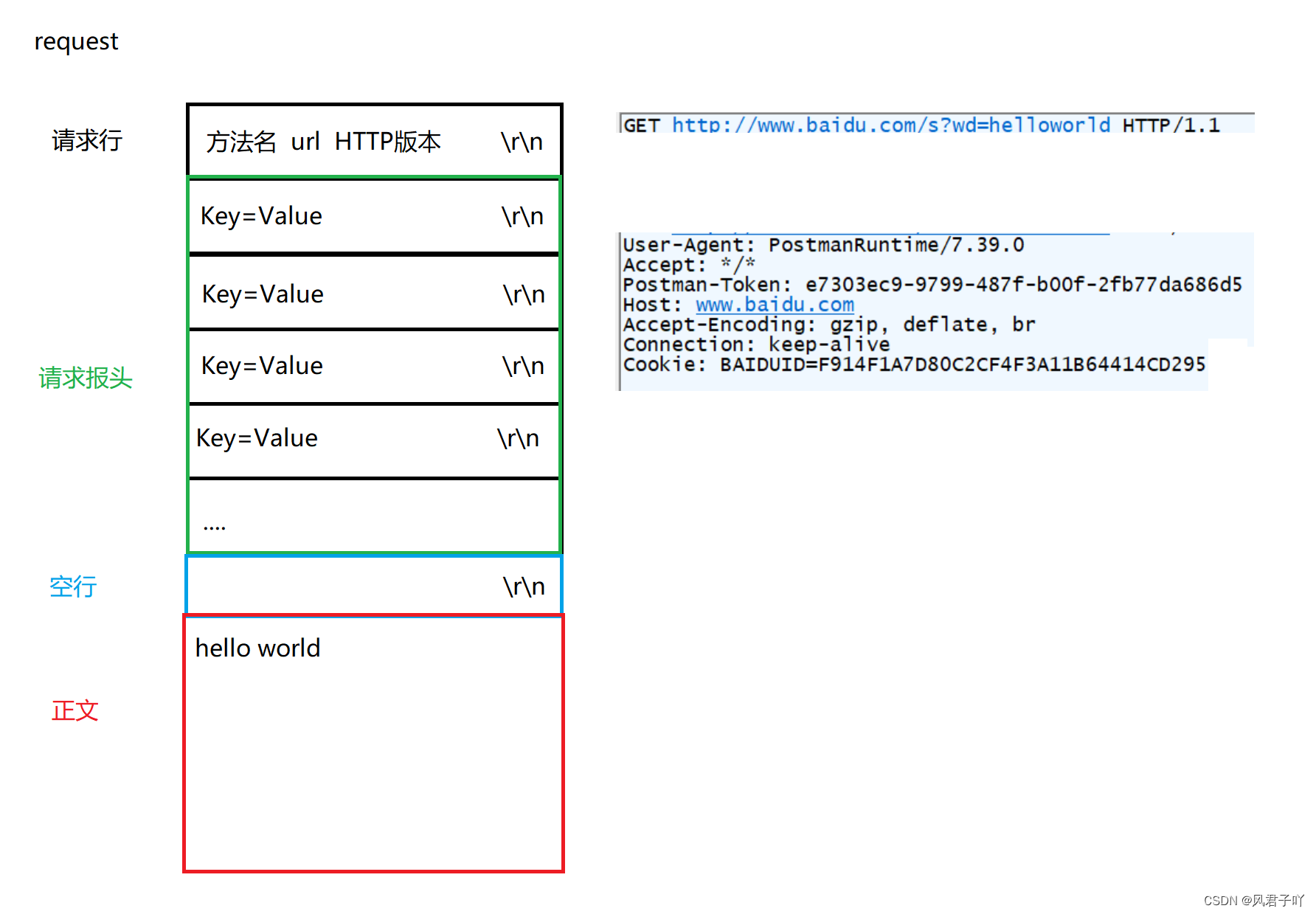
所以,我们就需要来解析我们收到的报文数据。
class HttpRequest
{
public:HttpRequest(){}bool Deserialize(std::string &request){size_t pos = request.find(sep);if (pos == std::string::npos){// 不完整报文lg(Warning, "Recv Incomplete Request...");return false;}_request_line = request.substr(0, pos);request.erase(0, pos + sep.size());std::string tmp;while (true){pos = request.find(sep);if (pos == std::string::npos){break;}tmp = request.substr(0, pos);if (tmp.empty()){// 说明已经截到空行break;}_request_header.push_back(tmp);request.erase(0, pos + sep.size());}request.erase(0, sep.size());_content = request;return true;}bool Parse(){std::string tmp = _request_line;int pos = tmp.find(blank);if (pos == std::string::npos){// 解析的请求行存在问题return false;}_function = tmp.substr(0, pos);tmp.erase(0, pos + blank.size());pos = tmp.find(blank);if (pos == std::string::npos){// 解析的请求行存在问题return false;}std::string url_tmp = tmp.substr(0, pos);if (url_tmp == "/"){_url = homepage;}else{_url = fileroot;_url += url_tmp;}tmp.erase(0, pos + blank.size());_http_version = tmp;return true;}public:std::string _request_line;std::vector<std::string> _request_header;std::string _content;std::string _function;std::string _url;std::string _http_version;bool _isFound = true; //判断是否存在访问资源
};
上面通过的request成员函数,可以讲一份完整的报文全部解析下来。
URL的解析
上章我们讲过,URL的作用是为了找到该服务器上唯一的资源,那么我们就需要对URL再进行解释,才能正确找到想要请求的文件。
一般来讲我们的,我们在网址上的URL其实是在服务器的工作目录中的查找的,当然,如果你想访问其他目录的文件,只需要自己稍作解析即可,我们仅谈论大多数情况。
所以,为了可以更好的控制访问资源,我们就可以在服务器工作目录创建一个web根目录,将所有需要用到的其他资源分类放进去。
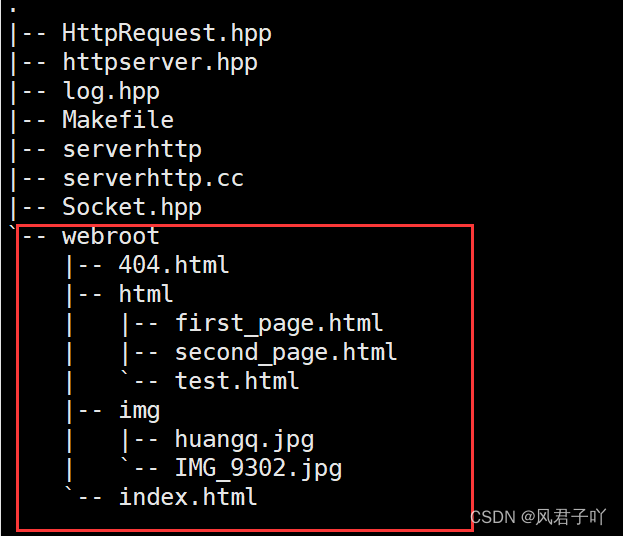
就比如说这里,我们创建了一个名为webroot的根目录。
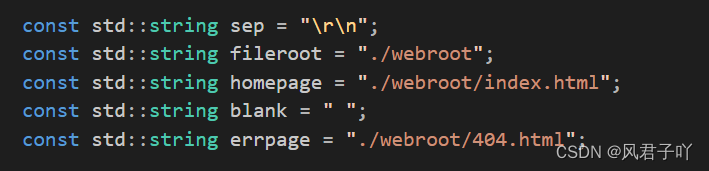
再在服务器内部代码定义根目录路径,后续只需要直接在后面添加我们解析后的URL字符串就可以实现精准访问唯一一份资源了。
std::string ReadFileData(const std::string &filepath)
{std::ifstream in(filepath, std::ios::binary);if (!in.is_open()){// 文件打开失败,返回一个空串lg(Warning, "File Open Failed...");return "";}// 将文件流指针移动到文件结尾in.seekg(0, std::ios_base::end);auto len = in.tellg();// 重新将文件流指针移动到文件开头in.seekg(0, std::ios_base::beg);std::string content;content.resize(len);in.read((char *)content.c_str(), content.size());return content;
}因为我们有时候会读取一个二进制文件,例如png,jpg格式的图片,所以我们这里采用二进制读取的方式打开文件。
最后返回的content就是文件的全部数据。
二、响应报文的发送
在上章我们也讲过相应报头是由 状态行,响应报头,正文组成。
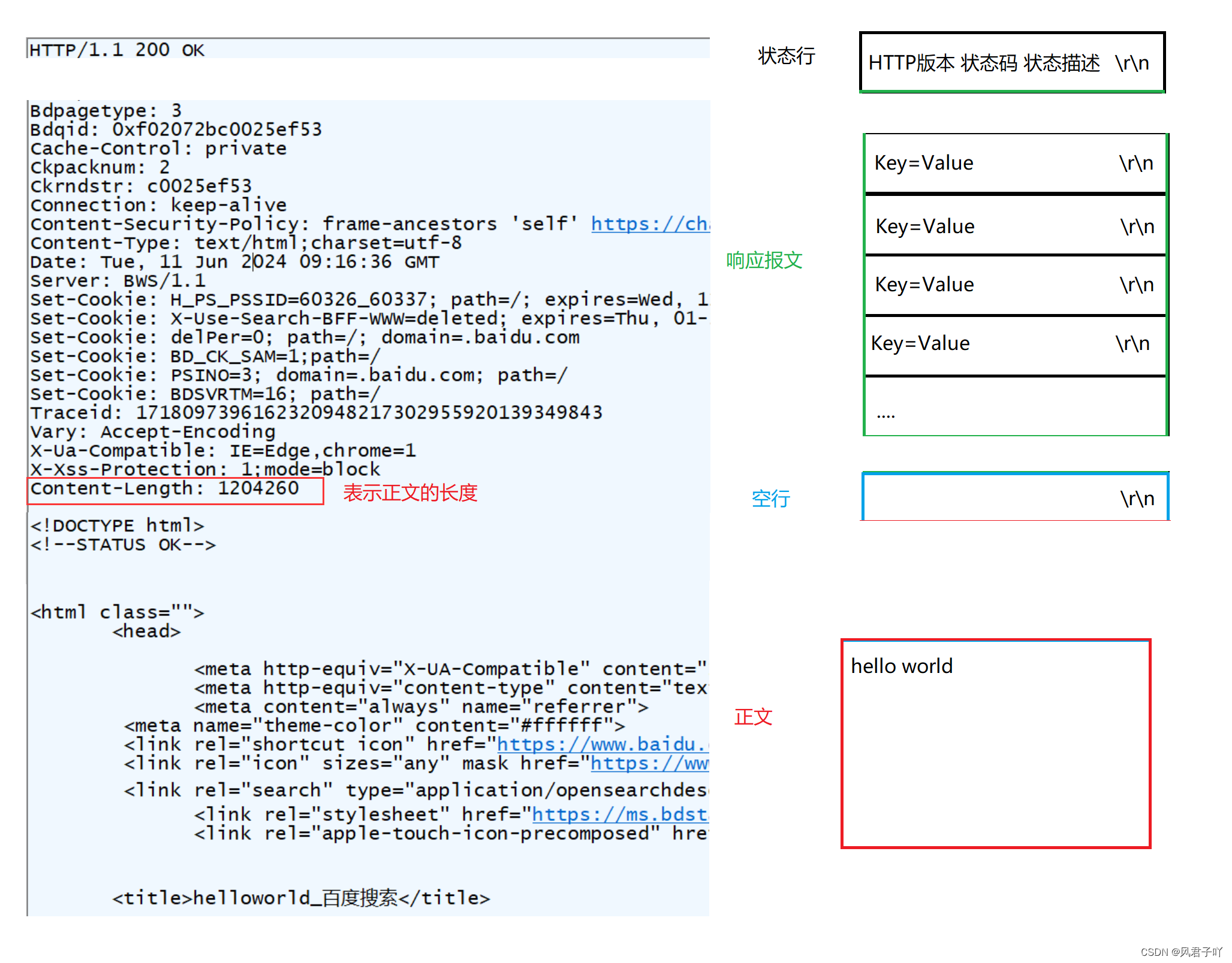
所以,我们要遵循http协议,就必须要遵守http协议的响应报头发送格式来发送数据。
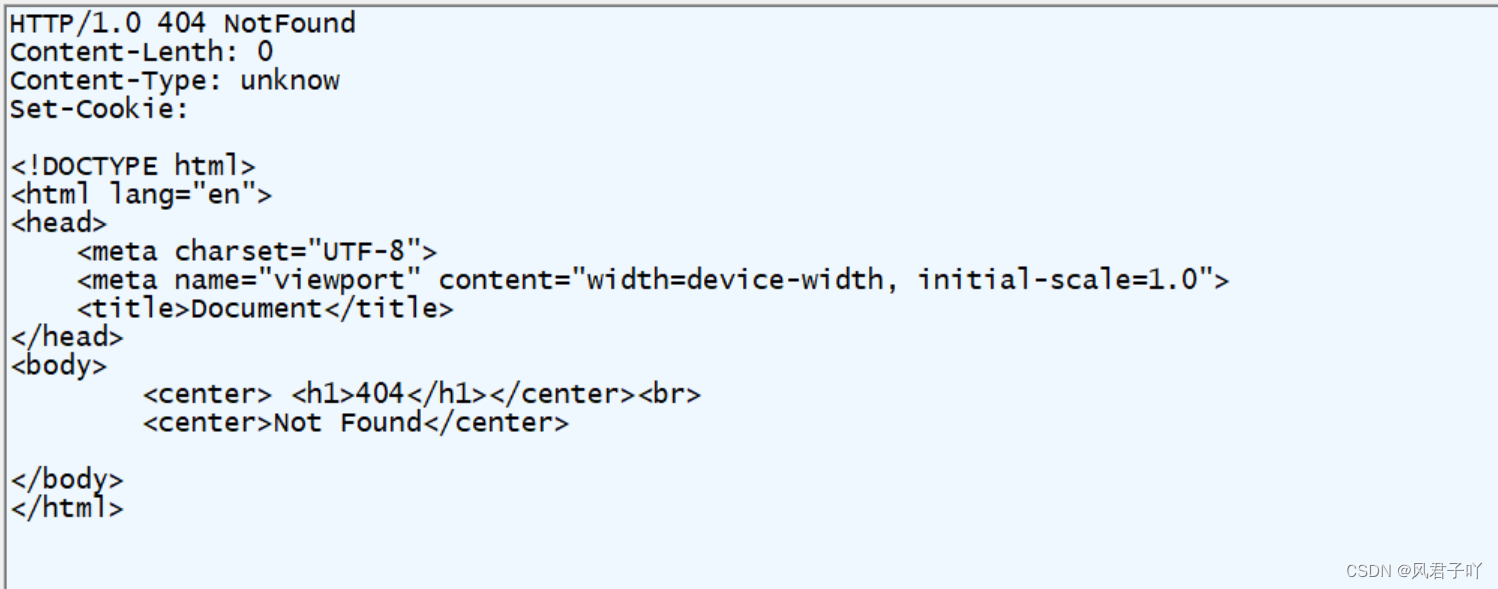
std::string Encode(const std::string &content, const HttpRequest &hr){std::string mes;if (hr._isFound){mes += "HTTP/1.0 200 OK\r\n";}else{mes += "HTTP/1.0 404 NotFound\r\n";}mes += "Content-Lenth: ";mes += std::to_string(hr._content.size());mes += sep;mes += "Content-Type: ";mes += SuffixtoType(hr._suffix);mes += sep;mes += "Set-Cookie: ";mes += hr._content;mes += sep;mes += sep; // 空行mes += content;return mes;}
该Encode函数就帮我们格式化了一个还算完整的响应报文。
Content-Lenth
Content-Lenth 作为响应报头很重要的一部分,它标识了响应报文中正文的字符长度,浏览器也会去解析Content-Lenth来读取正文部分。
Conten-Type
Conten-Type 作为相应报头很重要的一部分,它标识了响应报文中正文数据是一个怎样的类型,是一个html格式的网页?是一个png格式的图片…
并且http协议对于不同后缀的文件都有一个标识字符串,如下例
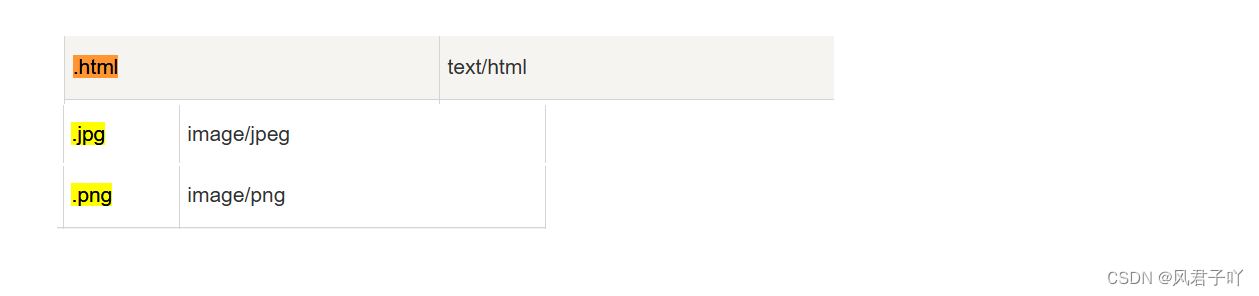
Cookie和Set-Cookie
当我们的响应报头携带了Set-Cookie: xxxxxxxxxx 数据后,并被浏览器读取到了,浏览器就会生成一个Cookie文件,里面存放你的Cookie信息。以后你再去访问该域的网页,浏览器就会自动在请求报头携带上你的Cooke: xxxxxxxxxx。
这就是为什么我们在登录一些视频网站之后,只需要登陆一次,下次登录就不需要我再输入账号密码了。这就是因为浏览器保存了你的Cookie登录信息。
Cookie的风险
这种便利的功能也一般会带来风险,如果有黑客入侵你的计算机,获取了你的Cookie信息,将你的Cookie信息粘贴到黑客他自己的浏览器中,他就能以你的身份浏览网站。
为了降低风险,许多互联网公司采用的都是session ID的方式来作为Cookie内容保存,将你的私人信息保存到远端,这样即使黑客获取你的Cookie信息,也没办法获取到你的隐私信息。
虽然如今的互联网已经十分成熟,已经有了很多的安全策略,但是还是有可能通过非法获取你的Cookie信息来冒用你的身份。
降低此类情况的发生我们就需要做到:不随便点陌生网址并输入你的账号密码; 在不常用的计算机记得删除你的Cookie信息; 收到异常登录的邮件即使修改账号密码。
三、尝试发送一个HTML网页
通过URL,我们已经可以准确访问到服务器的一个资源,现在我们在这份资源上随便写一份简单的HTML代码
在这里,我们先打开我们的服务器,绑定好自己的端口号。

我上面那朵花的文件位于服务器的web根目录下的/html/first_page.html位置。
我们的浏览器是成功的获取到了/html/first_page.html的内容,也识别解析了html。
再从我们的抓包软件来看
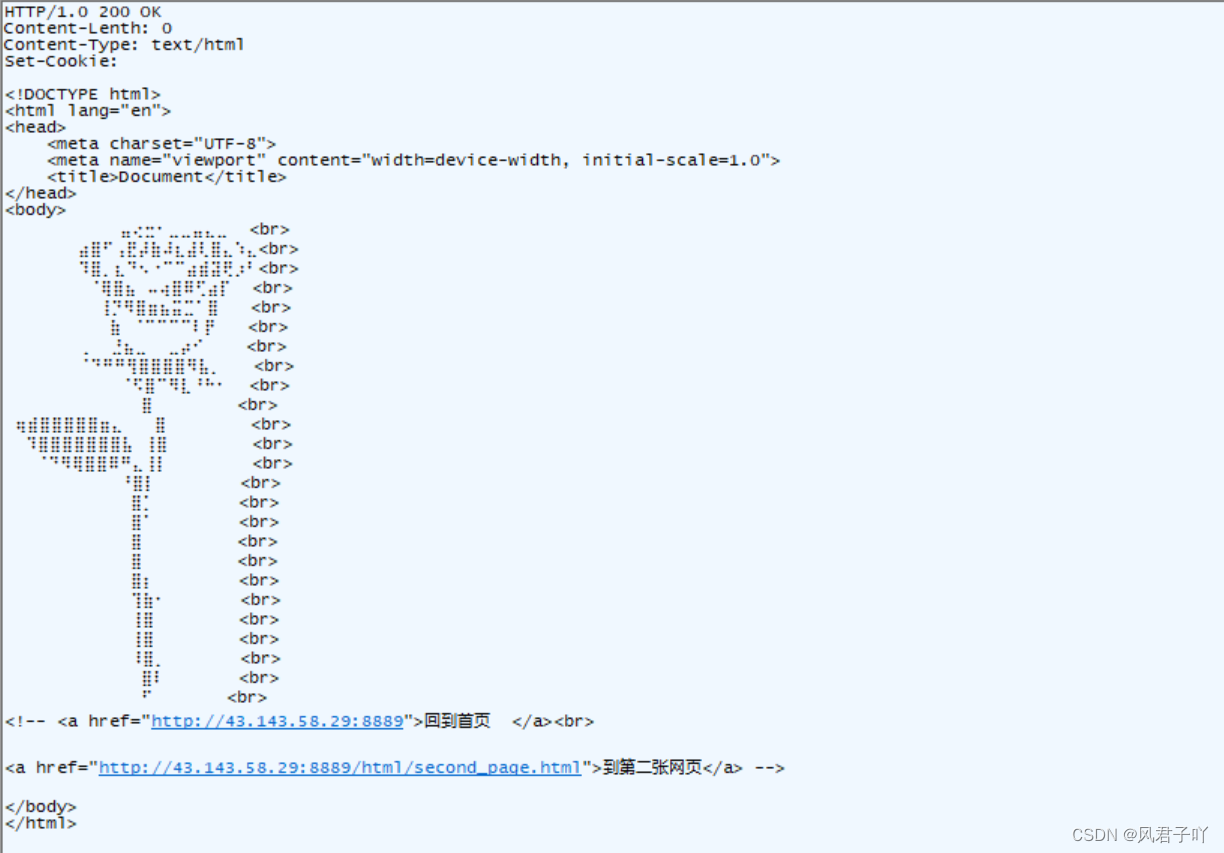
我们可以看到浏览器收到的响应报文的正文正是我们的first_page.html原封不动的内容。
404网页
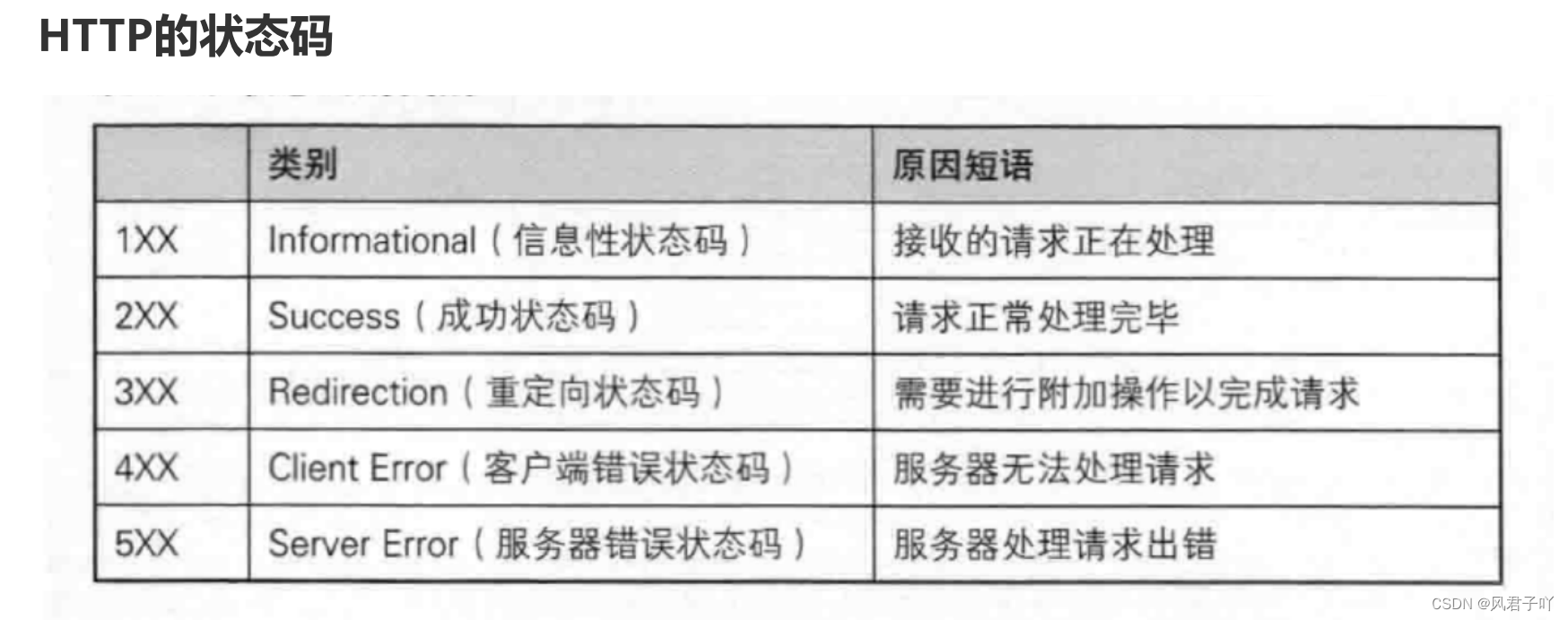
http的响应报文中的状态码是有规定的,像我们刚刚成功发送了一个完整的响应报文,我这里设置的状态码就是200 ,描述就是OK。
而对于我们经常看到的404,其实代表的就是没有找到你想要访问的那份资源,即你所访问的资源不存在。
这里我也是自己写一一个简单的404网页,大家可以来看看效果。
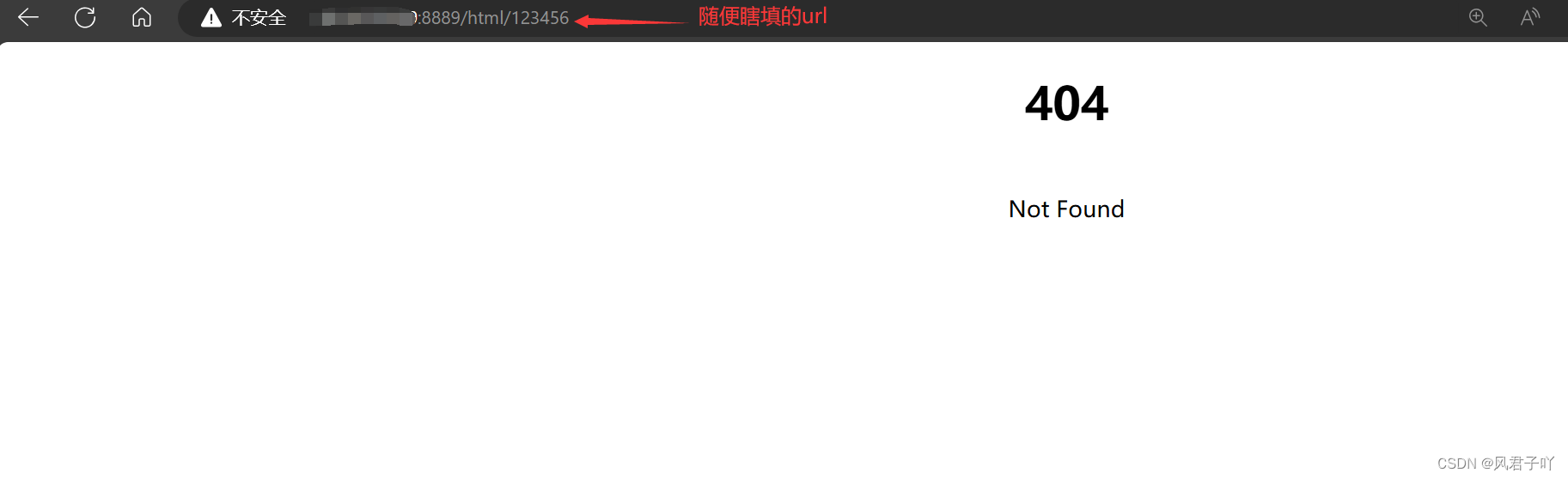
抓包到的响应报文
Location 重定向
Location在http协议当中是作为一个重定向的报头数据,后面携带上一个网址,即可直接重定向到另一个网址去。
不过需要注意的是,Location还必须配合状态码,需要状态码为3xx,我们这里采用临时重定向,所以就使用的302状态码。
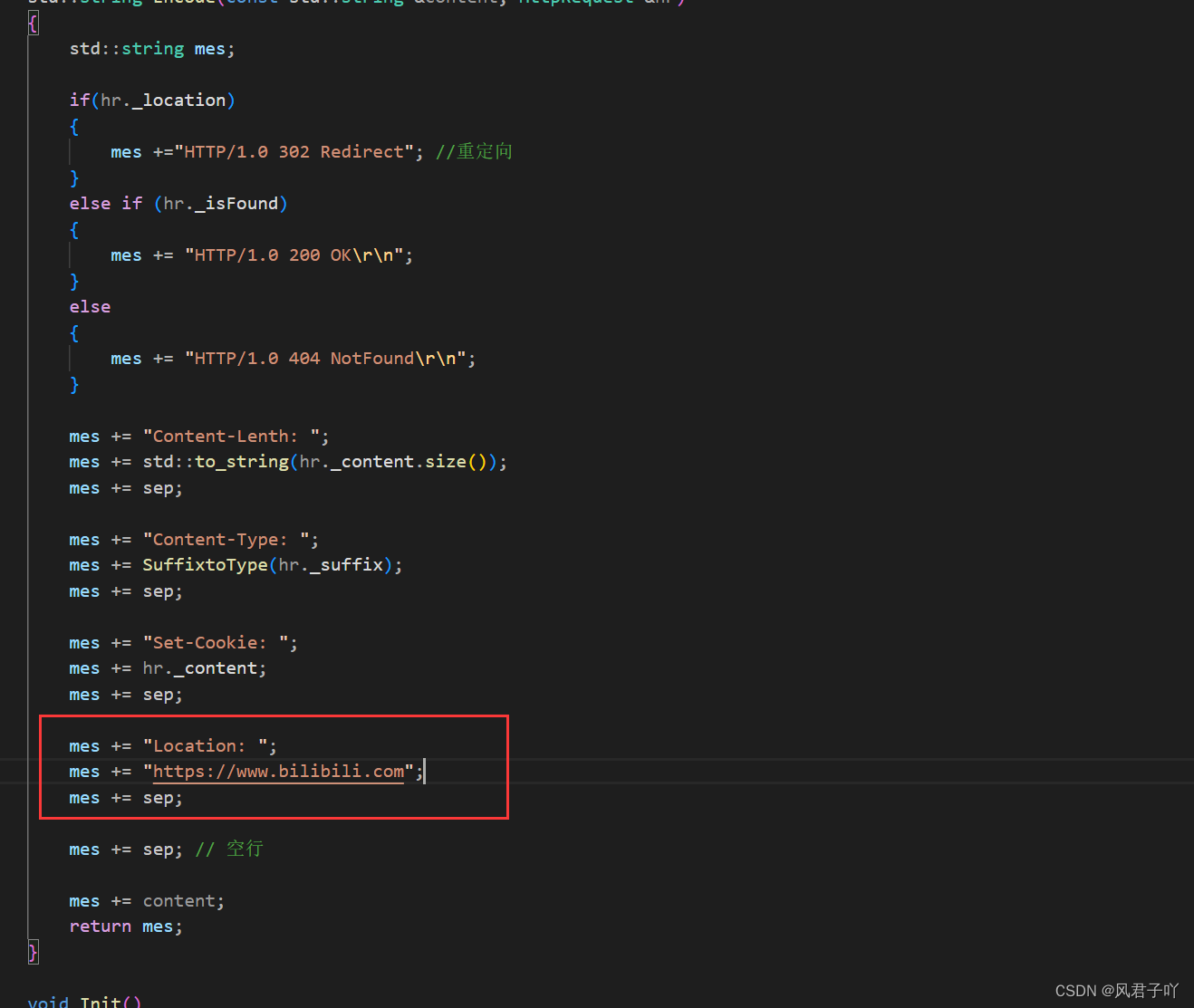
那么我们是否会直接跳转到bilibili的主页去呢?
从结果来看我们是直接跳转到了b站的。
四、浏览器的多次请求行为
一般我们访问像百度,淘宝这些大网页,里面的内容是形形色色的,包含各种图片视频。 而对于现在的我们来看来,这些无非都是文件,是保存在服务器的web根目录下的文件。
那么,像这种大网站内容极其丰富,我们仅仅通过一次请求和响应可以将所有的资源全部获取吗?
答案肯定是不能的,因为图片是文件,视频是文件,html网页也是文件,而html语言作为前端网页开发语言,就可以与浏览器进行“联动”。
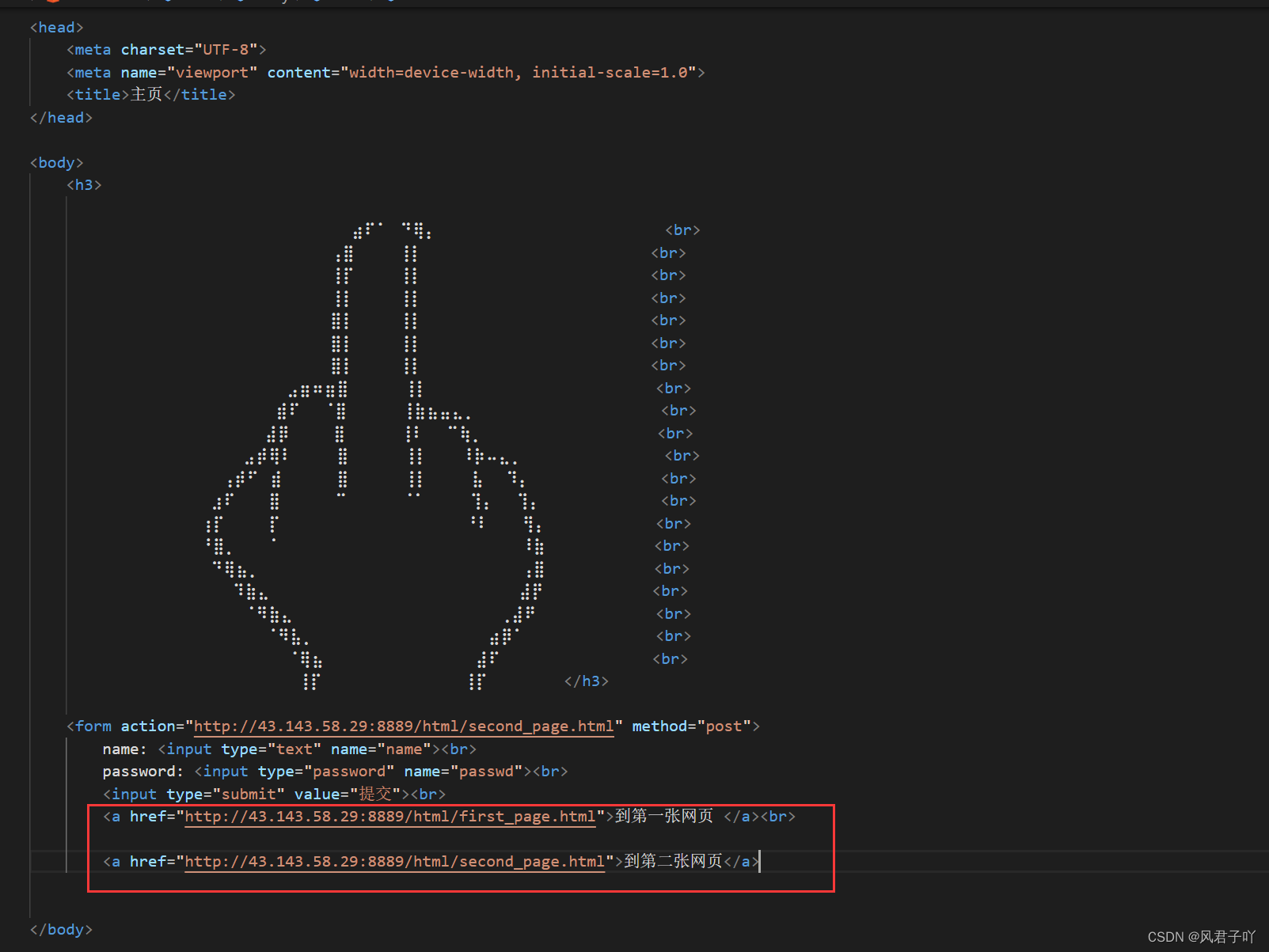
例如href标签可以让我们的网页进行跳转,跳转就需要再次对我们的服务器发起二次请求。

img标签可以添加图片,而浏览器识别到 src,也需要再次发起请求来获取图片。
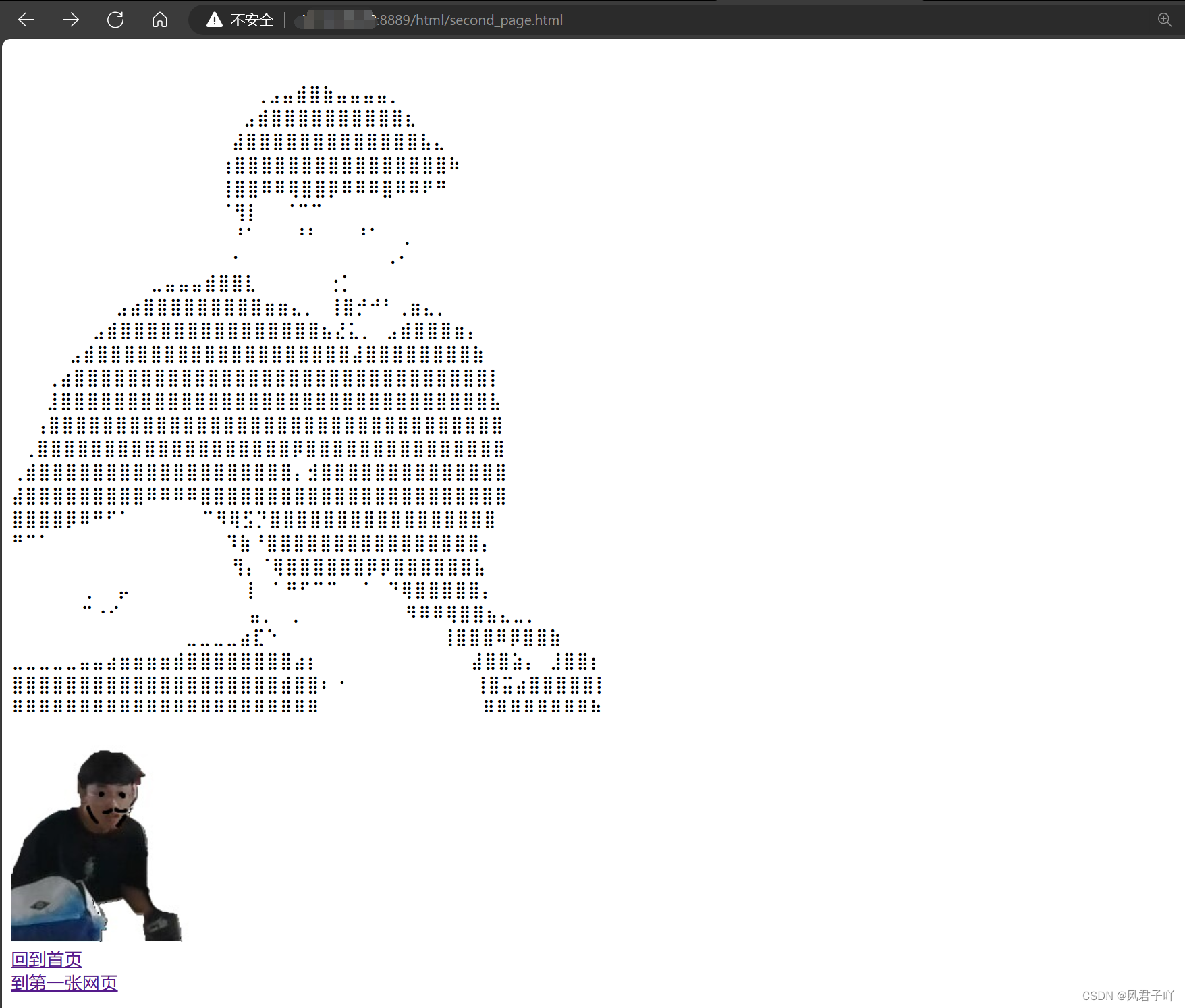

最后对于favicon.ico的请求是网站图标的获取。
这里就可以看出,我访问一次带有图片的网页,它是给我们提交了不仅仅一次的请求的。
总结
本章学习了如何搭建一个建议的httpServer,并通过浏览器进行访问。
下一章我们将学习https协议。