风控中的文本相似方法之余弦定理
一、余弦相似
一、 余弦相似概述
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。
从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
例如在信息检索中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。另外,它通常用于文本挖掘中的文件比较,在数据挖掘领域中,会用到它来度量集群内部的凝聚力。
二、 余弦相似应用场景
原创文章检测:通过文本相似,可以检测公众号文章、论文等是否存在抄袭
垃圾邮件识别:如“诚聘淘宝兼职”、“诚聘打字员”、“文章代写”、“增值税发票”等这样的小广告满天飞,作为网站或者APP的风控,不可能简单的加几个关键字就能进行屏蔽的,一般常用的方法就是标注一部分典型的广告文本,与它相似度高的就进行屏蔽。
内容推荐系统:在腾讯新闻、微博、头条、知乎等,每一篇文章、帖子的下面都有一个推荐阅读,那就是根据一定算法计算出来的相似文章。
冗余新闻过滤:我们每天接触过量的信息,信息之间存在大量的重复,相似度可以帮我们删除这些重复内容,比如,大量相似新闻的过滤筛选。
可用于文本相似的方法非常多,比如基于字符的杰卡德相似、编辑距离相似、最长公共子串等,基于距离的相似也很多,比如汉明距离、欧几里得距离等。本文介绍的是余弦距离相似,比较简单,可以作为风控领域文本相似的入门。
废话不多说,先看一个案例,我们用三句话作为例子,我从自己的邮箱里面扒出来的垃圾邮件,具体步骤如下。
三、 计算文本余弦相似
第一步,分词。
A句子:有/发票/加/薇/45357
B句子:有/发票/加/微/45357
C句子:正规/ 增值税/ 发票
第二步,列出所有的词(所有词的长度作为向量长度)
有,发票,加,薇,微,45357,正规,增值税
第三步,计算词频
A句子:有 1,发票 1,加 1,薇 1,微 0,45357 1,正规 0,增值税 0
B句子:有 1,发票 1,加 1,薇 0,微 1,45357 1,正规 0,增值税 0
C句子:有 0,发票 1,加 0,薇 0,微 0,45357 0,正规 1,增值税 1
第四步,写出词频向量。
A句子:[1, 1, 1, 1, 0, 1, 0 ,0]
B句子:[1, 1, 1, 0, 1, 1, 0 ,0]
C句子:[0, 1, 0, 0, 0, 0, 1 ,1]
到这里,问题就变成了如何计算这两个向量的相似程度。我们可以把它们想象成空间中的两条线段,都是从原点(0, 0, ...)出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。根据初中知识,余弦定理告诉我们,可以用下面的公式求得:
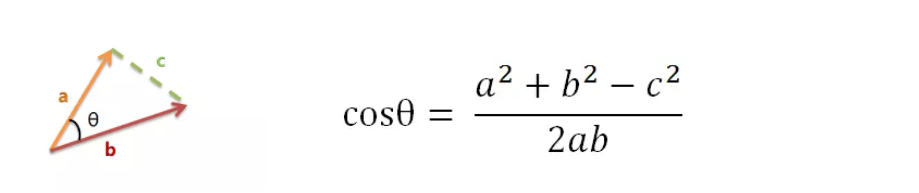
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
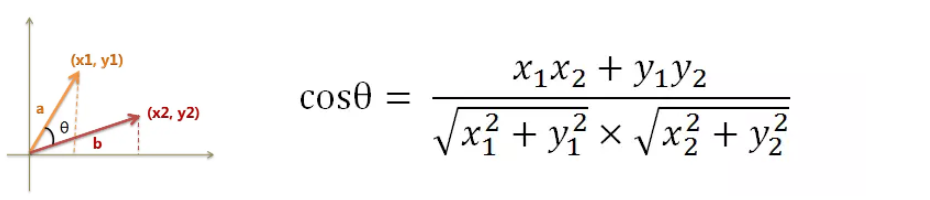
数学家已经证明,余弦的这种计算方法对n维向量也成立,假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:

使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。

下面我们用Python代码计算看看
import numpy as npA = np.array([1, 1, 1, 1, 0, 1, 0 ,0])B = np.array([1, 1, 1, 0, 1, 1, 0 ,0])C = np.array([0, 1, 0, 0, 0, 0, 1 ,1])#定义相似计算函数def cos_simi(x,y):num = x.dot(y.T)denom = np.linalg.norm(x) * np.linalg.norm(y)return num / denomcos_simi(A,B)0.7999999999999998cos_simi(A,C)0.2581988897471611cos_simi(B,C)0.2581988897471611
[有/发票/加/薇/45357] 和 [有/发票/加/微/45357] 只有一个字的差异,相似度0.80
[有/发票/加/薇/45357] 和 [正规/ 增值税/ 发票] 只有一个词相同,相似度0.2581,结果符合我们的感知。到此,我们就学会了计算两个句子的相似度
四、完整版代码
# 输入A,B两段语句,判断相似度import jieba
from collections import Counterdef preprocess_data(text):"""数据预处理函数,分词并去除停用词"""# 使用结巴分词对文本进行分词words = jieba.cut(text)# 去除停用词,这里只列举了几个示例停用词,实际应用中需要根据具体需求添加更多停用词stopwords = ['的', '了', '和', '是', '就', '而', '及', '与', '或']filtered_words = [word for word in words if word not in stopwords]return filtered_wordsdef extract_features(words):"""特征提取函数,使用词袋模型"""features = Counter(words)return str(features)def cosine_similarity(features1, features2):"""余弦相似度计算函数"""numerator = sum(features1[word] * features2[word] for word in set(features1) & set(features2))denominator = ((sum(features1[word] ** 2 for word in features1) ** 0.5) * (sum(features2[word] ** 2 for word in features2) ** 0.5))if not denominator:return 0.0else:return round(numerator / float(denominator), 3)def check_duplicate(content, input_text, threshold=0.7):"""查重函数,判断当前文本是否与已有文本重复"""# 对当前文本进行预处理和特征提取words = preprocess_data(content)features = extract_features(words)# 在此模拟已有文本的特征existing_features = extract_features(preprocess_data(input_text))similarity = cosine_similarity(eval(features), eval(existing_features))# 根据设定的相似度阈值来判断是否重复if similarity >= threshold:return similarityelse:return similaritysimilarity = check_duplicate("我是你的人","我是你的情人")
print('similarity',similarity)
二、杰卡德相似
杰卡德相似是比较常见的文本相似计算方法,文本分词后的交集比上并集,公式如下:
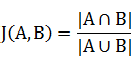
但在风控的实际业务中,有很多场景存在大规模的重复文本片段,比如:
S1 = '模具硅胶 翻模硅胶 指纹签到手指摸 指纹假膜 模具硅胶 液态硅胶 半透明硅胶 指模自制 指纹识别硅胶 打卡指纹透明膜 指纹膜 指纹 胶膜 手机指纹打卡假膜 指纹打卡机指纹胶膜 指纹识别贴打卡 diy硅胶模具材料 指纹打卡 指纹打卡道具 指纹打卡假膜人脸 指纹识别膜 硅胶 硅胶模具diy 模型制作材料 指模 液体硅胶 考勤指纹胶 指纹打卡假膜科密 指纹打卡假膜 硅橡胶 指纹胶膜制作 打卡 翻模硅胶材料 食品级硅胶 打卡考勤指纹 指模具考勤 翻模硅胶 diy 指纹打卡膜 指纹打卡假膜 打卡机指纹识别膜 指纹制作 diy液体材料 指纹制作工具 指模具 手指打卡 手办工具 签到指纹胶膜制作 模具硅胶翻模 翻模硅胶 指纹识别胶打卡 硅胶 硅胶打卡 打卡指纹胶膜 指纹识别膜套'
S2 = '指纹打卡假膜科密 指纹签到手指摸 指纹识别膜 硅胶 指模具 手指打卡 指纹打卡膜 指纹打卡假膜人脸 打卡考勤指纹 指模具考勤 指纹打卡机指纹胶膜 指纹制作工具 指纹打卡 指纹识别套 硅胶 硅橡胶 指模 diy硅胶模具材料 指纹制作 指纹识别硅胶 指模自制 打卡指纹胶膜 指纹打卡假膜 指纹打卡道具 手机指纹打卡假膜 指纹假膜 指纹膜 指纹打卡假膜 硅橡胶 打卡机指纹识别膜 指纹识别模具 硅胶 指纹识别膜套 硅胶模具diy 打卡指纹透明膜 上班 打卡指纹透明膜 指纹识别胶打卡 硅胶 指纹识别打卡膜假手指 硅胶 考勤指纹胶 硅胶打卡 指纹胶膜制作 打卡 签到指纹胶膜制作 指纹 胶膜 指纹识别贴打卡abcdedf'
使用杰卡德相似计算相似度:0.7647,在S2中加入'abcdedf'干扰字符串后,相似度 0.6964
使用新加权算法计算相似度:0.7305 在S2中加入'abcdedf'干扰字符串后,相似度 0.7252
可见第二种算法,针对这种无序的词组计算相似度,抗干扰能力要比传统的方法强很多,能够更稳点的计算类似的多来源文本的相似性。
具体的计算逻辑如下(只计算了top20):

除了上面的案例,还有下面的各种场景,都存在大量重复的文本集合,我们需要有一种专门的方法来进行计算。
两个商家店铺所有商品名称集合,一般一个店铺商品都有差不多
百度推广者的竞价词集合,基本会穷举所有相关的搜索词
... ...
淘宝商家的推广词集合
我写了个函数实现,也不知道叫啥,就是一种加权的杰卡德相似。
S1 = '模具硅胶 翻模硅胶 指纹签到手指摸 指纹假膜 模具硅胶 液态硅胶 半透明硅胶 指模自制 指纹识别硅胶 打卡指纹透明膜 指纹膜 指纹 胶膜 手机指纹打卡假膜 指纹打卡机指纹胶膜 指纹识别贴打卡 diy硅胶模具材料 指纹打卡 指纹打卡道具 指纹打卡假膜人脸 指纹识别膜 硅胶 硅胶模具diy 模型制作材料 指模 液体硅胶 考勤指纹胶 指纹打卡假膜科密 指纹打卡假膜 硅橡胶 指纹胶膜制作 打卡 翻模硅胶材料 食品级硅胶 打卡考勤指纹 指模具考勤 翻模硅胶 diy 指纹打卡膜 指纹打卡假膜 打卡机指纹识别膜 指纹制作 diy液体材料 指纹制作工具 指模具 手指打卡 手办工具 签到指纹胶膜制作 模具硅胶翻模 翻模硅胶 指纹识别胶打卡 硅胶 硅胶打卡 打卡指纹胶膜 指纹识别膜套'S2 = '指纹打卡假膜科密 指纹签到手指摸 指纹识别膜 硅胶 指模具 手指打卡 指纹打卡膜 指纹打卡假膜人脸 打卡考勤指纹 指模具考勤 指纹打卡机指纹胶膜 指纹制作工具 指纹打卡 指纹识别套 硅胶 硅橡胶 指模 diy硅胶模具材料 指纹制作 指纹识别硅胶 指模自制 打卡指纹胶膜 指纹打卡假膜 指纹打卡道具 手机指纹打卡假膜 指纹假膜 指纹膜 指纹打卡假膜 硅橡胶 打卡机指纹识别膜 指纹识别模具 硅胶 指纹识别膜套 硅胶模具diy 打卡指纹透明膜 上班 打卡指纹透明膜 指纹识别胶打卡 硅胶 指纹识别打卡膜假手指 硅胶 考勤指纹胶 硅胶打卡 指纹胶膜制作 打卡 签到指纹胶膜制作 指纹 胶膜 指纹识别贴打卡 abcdedf'
from collections import Counter
class Similarty(): def __init__(self,S1,S2,topn):self.S1 = S1self.S2 = S2self.topn = topn''' 标准杰卡德''' def normal_jaccard(self):return len(set(self.S1)&set(self.S2))/len(set(self.S1) | set(self.S2))''' 加权杰卡德''' def weight_jaccard(self): if self.S1 is not None and self.S2 is not None:sim_0 = self.S1.replace(' ','')sim_1 = self.S2.replace(' ','')collect0 = Counter(dict(Counter(sim_0).most_common(self.topn)))collect1 = Counter(dict(Counter(sim_1).most_common(self.topn))) jiao = collect0 & collect1bing = collect0 | collect1 sim = float(sum(jiao.values()))/float(sum(bing.values())) return(sim) else:return 0.0sim = Similarty(S1,S2,50)#初始化
sim.normal_jaccard()
0.6964285714285714
sim.weight_jaccard()
0.7252396166134185我这里为了简单,仅仅分字进行的相似计算,大家也可以自然语言分词计算,也可以N-gram后计算,稳定性会进一步加强。
好了,本期内容分享到此了,希望对你有启发。
有什么需求,可以联系我。
下面是一些计算的案例



原文链接:在此鸣谢小伍哥!!!https://mp.weixin.qq.com/s?__biz=MzA4OTAwMjY2Nw==&mid=2650188043&idx=2&sn=2fd5d3e143050092ebbee5969a153852&chksm=88238ecfbf5407d9a0a31ba2d892f87214e7225becf25ec4c209a66e4283aa2c08b990bfb73c&scene=21#wechat_redirect