【LLM之RAG】Adaptive-RAG论文阅读笔记
研究背景
文章介绍了大型语言模型(LLMs)在处理各种复杂查询时的挑战,特别是在不同复杂性的查询处理上可能导致不必要的计算开销或处理不足的问题。为了解决这一问题,文章提出了一种自适应的查询处理框架,动态选择最合适的策略,从而提高整体效率和准确性 。
研究目标
目标是开发一种自适应框架,该框架能够根据查询的复杂性动态选择最适合的检索增强语言模型策略,从简单到复杂的策略不等。
相关工作
开放域问答:这类任务通常涉及两个模块:检索器和阅读器。随着具有千亿参数的超强推理能力的LLM的出现,LLM和检索器之间的协同作用已经取得了显著进展。然而,尽管在单跳检索增强LLM方面取得了进展,但某些查询的复杂性需要更复杂的策略。
多跳问答:多跳问答(Multi-hop QA)是常规开放域问答(Open-domain QA)的扩展,需要系统全面收集和将多个文档的信息作为上下文回答更复杂的查询。首先将多跳查询分解为更简单的单跳查询,重复访问LLM和检索器来解决这些子查询,并合并它们的答案以形成完整答案。这种查询的缺点是:每个查询迭代访问LLM和检索器可能效率极低,因为有些查询可能足够简单,可以通过单一检索步骤甚至仅通过LLM本身来回答。
自适应检索:为了处理不同复杂性的查询,自适应检索策略根据每个查询的复杂性动态决定是否检索文档。根据实体的频率来确定查询的复杂性级别,并建议仅当频率低于一定阈值时才使用检索模块。然而,这种方法仅关注于检索与否的二元决策,可能不足以解决需要多个推理步骤的更复杂的查询。
方法论
数据处理
定义复杂性标签:首先,需要定义问题的复杂性等级。在Adaptive-RAG中,通常有三个类别:简单(A)、中等(B)和复杂(C)。简单问题可以直接由LLM回答,中等复杂度问题需要单步检索,而复杂问题则需要多步检索和推理。
自动收集训练数据:由于没有现成的带有复杂性标签的查询数据集,Adaptive-RAG通过两种策略自动构建训练数据集:
- 从不同Retrieval-Augmented LLM策略的预测结果中标注查询的复杂性。
如果非检索方法能够正确生成答案,则对应问题的标签为简单(A);
如果单步检索方法和多步检索方法都能正确回答,而非检索方法失败,则对应问题的标签为中等(B);
如果只有多步检索方法能够正确回答,则对应问题的标签为复杂(C)。 - 利用基准数据集中的固有偏差来标注未标记的查询。
例如,如果一个查询在单步数据集中未被标记,则自动分配标签为中等(B);
如果在多步数据集中未被标记,则自动分配标签为复杂(C)。
解决方案
Adaptive Retrieval-Augmented Generation (Adaptive-RAG) 是一种新颖的问答框架,它能够根据问题的复杂性动态选择最适合的策略来处理Retrieval-Augmented LLM。这三种策略包括:
- 非检索方法(No Retrieval):这是最简单的策略,直接使用LLM本身的知识库来生成答案。这种方法适用于那些模型已经知道答案的简单问题,不需要额外的外部信息。
- 单步检索方法(Single-step Approach):当问题需要额外的信息时,这种方法会先从外部知识源检索相关信息,然后将检索到的文档作为上下文信息输入到LLM中,帮助模型生成更准确的答案。这种方法适用于需要一次额外信息检索的中等复杂度问题。
- 多步检索方法(Multi-step Approach):对于最复杂的问题,需要从多个文档中综合信息并进行多步推理。这种方法通过迭代地访问检索器和LLM,逐步构建起解决问题所需的信息链。这种方法适用于需要多步逻辑推理的复杂问题。
Adaptive-RAG的核心在于它能够通过分类器来评估问题的复杂性,然后根据评估结果选择最合适的处理策略。分类器是一个较小的语言模型,它被训练用来预测query的复杂度。通过这种方式,Adaptive-RAG能够灵活地在不同的Retrieval-Augmented LLM策略之间进行切换,从而在处理各种复杂性的问题时,实现更高的效率和准确性。
实验
实验设计
研究中使用的数据集包括单跳和多跳问题,涵盖了从简单到复杂的查询。数据来源于开放域问答数据集,这些数据集经常用于评估问答系统的性能。
- SQuAD v1.1 (Rajpurkar et al., 2016):通过阅读文档撰写问题的方式创建。
- Natural Questions (Kwiatkowski et al., 2019):基于Google搜索的真实用户查询构建。
- TriviaQA (Joshi et al., 2017):由各种小测验网站提供的琐碎问题组成。
- MuSiQue (Trivedi et al., 2022a):通过组合多个单跳问题形成涉及2-4个跳转的查询。
- HotpotQA (Yang et al., 2018):通过链接多个维基百科文章由注释者创建的问题。
- 2WikiMultiHopQA (Ho et al., 2020):源自维基百科及其相关知识图谱路径,需要2跳处理。
评估指标包括有效性和效率两大类:
- 有效性:使用F1得分、EM(精确匹配)和准确率(Accuracy, Acc)来评估模型预测的答案与真实答案之间的匹配程度。
- 效率:测量回答每个查询所需的检索和生成步骤数以及与单步策略相比的平均响应时间。
实验结论
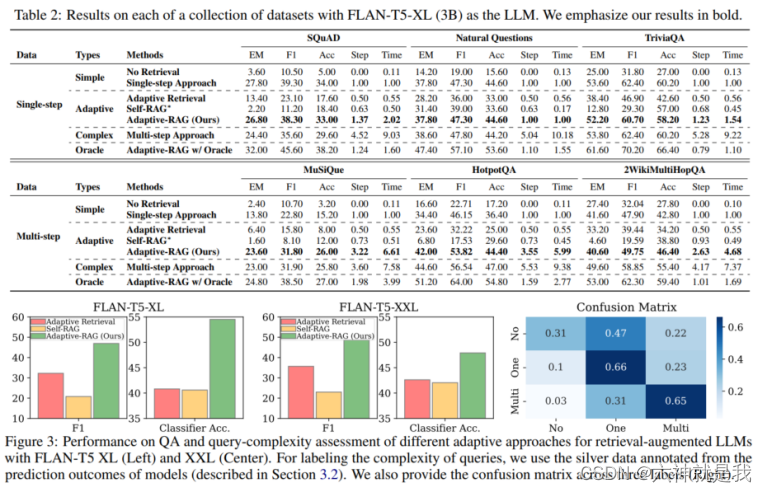
实验结果显示,Adaptive-RAG在处理复杂查询时,比传统的检索增强方法更有效,尤其是在资源利用效率上。例如,在使用不同大小模型(如GPT-3.5和FLAN-T5系列)进行测试时,Adaptive-RAG在处理多步查询的场景中,表现出更高的准确率和效率 。
参考资料
- 论文
- 代码