关于FPGA对 DDR4 (MT40A256M16)的读写控制 I
关于FPGA对 DDR4 (MT40A256M16)的读写控制 I
语言 :Verilg HDL
EDA工具:ISE、Vivado
- 关于FPGA对 DDR4 (MT40A256M16)的读写控制 I
- 一、引言
- 二、DDR4的特性(MT40A256M16)
- (1) 电压和电源管理
- (2)内部参考电压生成
- (3) 命令/地址延迟(CAL)
- (4)写入均衡 (Write Leveling)
- (5)自刷新模式 (Self Refresh Mode)
- (6)命令/地址奇偶校验 (Command/Address Parity)
- (7)数据总线写入循环冗余校验 (Databus Write Cyclic Redundancy Check, CRC)
- (8)低功耗自刷新 (Low-Power Auto Self Refresh, LPASR)
- (9)温度控制刷新 (Temperature-Controlled Refresh, TCR):
- (9)数据总线反转 (Data Bus Inversion, DBI)
- 三、DDD4关键时序参数和地址
- 关键词: 调用,Verilog HDL,ifdef 和 endif ,generate语句
一、引言
博主将会写一个系列的文章 关于FPGA对DDR4(MT40A256M16)的有效读写控制,最大化FPGA对DDR4的读写控制。首先将对DDR4的技术文档进行研读,注重DDR4的读写操作、刷新时间等。
二、DDR4的特性(MT40A256M16)
DDR4 SDRAM即双倍数据速率第四代同步动态随机存取存储器,比DDR3强在速率上,可以跑到2000M到3000M MT/s(百万次每秒)的速度,具体因芯片型号为准。
(1) 电压和电源管理
VDD = VDDQ = 1.2V ±60mV
VPP = 2.5V, –125mV/+250mV
(2)内部参考电压生成
片上、内部、可调节的VREFDQ生成
(3) 命令/地址延迟(CAL)
CAL是DDR4内存中的一个特性,用于减少内存控制器在发送读或写命令到内存时的等待时间。通过使用CAL,内存控制器可以在内存接收到命令和地址信息之前,提前发送这些信息,从而减少内存操作的整体延迟。
CAL功能可以被配置为不同的延迟级别,这通常以时钟周期的数量来表示。例如,如果CAL被设置为1,则表示内存控制器可以在命令有效前一个时钟周期发送命令和地址信息。这种预加载机制有助于提高内存的效率和性能,尤其是在高频率操作时。
CAL功能可以被启用或禁用,并且其值(即延迟的时钟周期数)需要根据特定的内存操作和内存控制器的要求进行编程到模式寄存器中。
(4)写入均衡 (Write Leveling)
一个补偿信号完整性问题的特性,允许内存控制器调整数据存取时序,以确保数据在内存中正确写入。
(5)自刷新模式 (Self Refresh Mode)
允许内存在不活跃时自动进入低功耗状态,同时保持数据的完整性。
(6)命令/地址奇偶校验 (Command/Address Parity)
提供了一种错误检测机制,确保命令和地址信息的准确性
(7)数据总线写入循环冗余校验 (Databus Write Cyclic Redundancy Check, CRC)
增加了数据写入时的错误检测和校正能力,提高了数据的完整性
(8)低功耗自刷新 (Low-Power Auto Self Refresh, LPASR)
根据系统需求和温度条件,自动调整自刷新频率以降低功耗。
(9)温度控制刷新 (Temperature-Controlled Refresh, TCR):
根据环境温度调整刷新周期,以优化性能和可靠性。。
(9)数据总线反转 (Data Bus Inversion, DBI)
一种提高信号完整性的特性,允许内存控制器反转数据总线的极性。
三、DDD4关键时序参数和地址
(1)不同DDR4速度等级 代表不同的速率, 关键时序参数如下所示
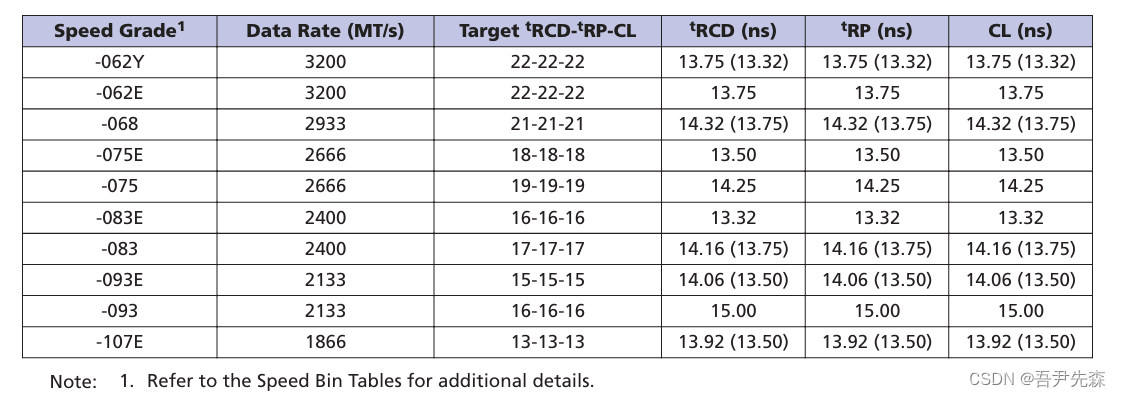
tRCD (ns): 行地址到列地址的延迟时间,即从发出行选择命令到列地址稳定的延迟,以纳秒为单位。
tRP (ns): 行预充电时间,即从发出预充电命令到行可以再次被激活的时间。
CL (ns): CAS延迟,这是从发出读或写命令到数据可以被访问的时间
DDR4-2666速度等级的内存,其tRCD、tRP和CL的值为13.50纳秒。
这些参数对于内存控制器的设计和内存系统的性能至关重要。内存控制器必须根据这些参数来设计其操作时序,以确保数据可以正确地在内存和处理器之间传输,同时避免数据损坏或系统不稳定。
(2) 地址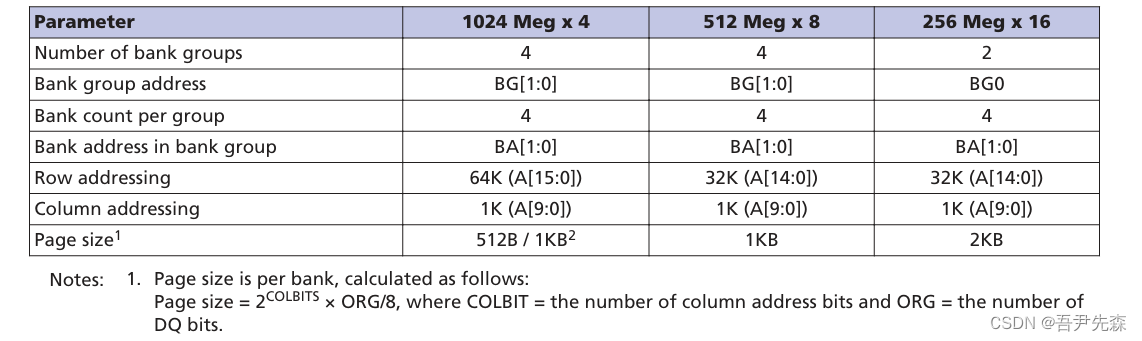
Bank Groups: DDR4 SDRAM被组织成多个“bank groups” 。每个bank group包含一定数量的“banks”
Bank Addressing: 每个bank group内部的banks通过“bank address”( BA[1:0])来寻址
Row and Column Addressing: 内存阵列中的行和列通过行地址和列地址来选择。行地址由A[15:0](或更少,取决于配置)提供,而列地址由A[9:0]提供。
Page Size: 每个bank的页面大小是固定的,并且根据组织方式(ORG)和列地址位(COLBITS)计算得出。页面大小影响着内存的突发传输能力
例如:512 Meg x 8配置:4个bank groups,每组4个banks,行地址为32K(A[14:0]),列地址为1K(A[9:0]),页面大小为1KB。