18、指数移动平均——EMA
简介
在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。
指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。
例子
假设有”温度-天数“的数据
θt\theta_tθt:在第 t 天的温度
vtv_tvt:在第 t 天的移动平均数
β\betaβ: 权重参数
v0=0v1=0.9v0+0.1θ1v2=0.9v1+0.1θ2⋯vt=0.9vt−1+0.1θt\begin{aligned} v_0 &= 0 \\ v_1 &=0.9v_0 + 0.1 \theta_1 \\ v_2 &=0.9v_1 + 0.1 \theta_2\\ &\cdots\\ v_t &=0.9v_{t-1} + 0.1\theta_t\\ \end{aligned} v0v1v2vt=0=0.9v0+0.1θ1=0.9v1+0.1θ2⋯=0.9vt−1+0.1θt
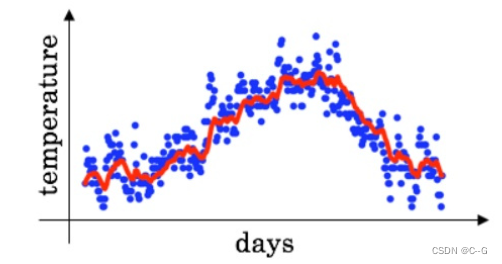
红线即是蓝色数据点的指数移动平均
VtV_tVt 和 β\betaβ 的关系
vtv_tvt 大概表示前 11−β\frac{1}{1-\beta}1−β1 天的平均数据(以第 t 天做参考)
| β=0.9\beta = 0.9β=0.9 | 11−β≈10\frac{1}{1-\beta}\approx101−β1≈10 | vtv_tvt 大概表示前10天的平均数据 | 红线 |
|---|---|---|---|
| β=0.98\beta = 0.98β=0.98 | 11−β≈50\frac{1}{1-\beta}\approx501−β1≈50 | vtv_tvt 大概表示前50天的平均数据 | 绿线 |
| β=0.5\beta = 0.5β=0.5 | 11−β≈2\frac{1}{1-\beta}\approx21−β1≈2 | vtv_tvt 大概表示前2天的平均数据 | 黄线 |
| 那么β\betaβ 越大,表示考虑的时间阔度越大 |
理解vtv_tvt
vt=β⋅vt−1+(1−β)⋅θt\begin{aligned} v_t = \beta \cdot v_{t-1} + (1-\beta) \cdot \theta_t \end{aligned} vt=β⋅vt−1+(1−β)⋅θt
当 β=0.9\beta = 0.9β=0.9,从v100v_{100}v100往回写
v100=0.9v99+0.1θ100v99=0.9v98+0.1θ99⋯v1=0.9v0+0.1θ1v0=0\begin{aligned} v_{100} &= 0.9v_{99} + 0.1\theta_{100}\\ v_{99} &= 0.9v_{98} + 0.1\theta_{99}\\ &\cdots \\ v_1 &=0.9v_0 + 0.1 \theta_1 \\ v_0 &= 0 \\ \end{aligned} v100v99v1v0=0.9v99+0.1θ100=0.9v98+0.1θ99⋯=0.9v0+0.1θ1=0
迭代该过程可知:
- $v_{100} 是 θ100θ99θ98⋯\theta_{100}\ \theta_{99}\ \theta_{98}\ \cdotsθ100 θ99 θ98 ⋯ 的加权求和
- θ\thetaθ 前的系数相加为 1 或逼近 1
当某项系数小于峰值系数 (𝟏−𝜷)的 1e\frac{1}{e}e1 时,可以忽略它的影响
(0.9)10≃0.34≃1e(0.9)^10 \simeq 0.34 \simeq \frac{1}{e}(0.9)10≃0.34≃e1 所以当β=0.9时,相当于前10天的加权平均。
(0.98)50≃0.36≃1e(0.98)^50 \simeq 0.36 \simeq \frac{1}{e}(0.98)50≃0.36≃e1 所以当β=0.98时,相当于前50天的加权平均。
(0.5)2≃0.25≃1e(0.5)^2 \simeq 0.25 \simeq \frac{1}{e}(0.5)2≃0.25≃e1 所以当β=0.5时,相当于前2天的加权平均。
带入深度学习模型
vt=β⋅vt−1+(1−β)⋅θtv_t = \beta \cdot v_{t-1} + (1-\beta) \cdot \theta_tvt=β⋅vt−1+(1−β)⋅θt
θt\theta_tθt:在第 t 次更新得到的所有参数权重
vtv_tvt:第 t 次更新的所有参数移动平均数
β\betaβ:权重参数
EMA内在
对于更新 t 次时普通的参数权重 θt\theta_tθt (gtg_tgt 是第 t 次传播得到的梯度):
θt=θt−1−gt−1=θt−2−gt−1−gt−2=⋯=θ1−∑i=1t−1gi\begin{aligned} \theta_t &= \theta_{t-1} - g_{t-1}\\ &=\theta_{t-2} - g_{t-1} - g_{t-2}\\ & = \cdots\\ &= \theta_1 - \sum^{t-1}_{i=1} g_i\\ \end{aligned} θt=θt−1−gt−1=θt−2−gt−1−gt−2=⋯=θ1−i=1∑t−1gi
对于更新 t 次时使用EMA的参数权重 vtv_tvt:
θt=θ1−∑i=1t−1givt=θ1−∑i=1t−1(1−βt−i)gi\begin{aligned} \theta_t &= \theta_1 - \sum^{t-1}_{i=1}g_i\\ v_t &= \theta_1 - \sum^{t-1}_{i=1}(1-\beta^{t-i})g_i \end{aligned} θtvt=θ1−i=1∑t−1gi=θ1−i=1∑t−1(1−βt−i)gi
推理如下:将 θn\theta_nθn 带入 vnv_nvn 表达式,并且令 v0=θ1v_0 = \theta_1v0=θ1:
vn=βtv0+(1−β)(θt+βθt−1+β2θt−2+⋯+βn−1θ1)=βtv0+(1−β)(θ1−∑i=1t−1gi+β(θ1−∑i=1t−2gi)+⋯+βt−2(θ1−∑i=11gi)+βt−1θ1)=βtv0+(1−βt)θ1−∑i=1n−1(1−βt−i)gi=θ1−∑i=1t−1(1−βt−i)gi\begin{aligned} v_n &= \beta^t v_0 +(1-\beta)(\theta_t + \beta\theta_{t-1}+\beta^2\theta_{t-2}+\cdots+\beta^{n-1}\theta_1) \\ &=\beta^tv_0 + (1-\beta)(\theta_1 - \sum^{t-1}_{i=1}g_i+\beta(\theta_1 - \sum^{t-2}_{i=1}g_i)+\cdots+\beta^{t-2}(\theta_1 - \sum^{1}_{i=1}g_i)+\beta^{t-1}\theta_1)\\ &=\beta^tv_0 + (1-\beta^t)\theta_1 - \sum^{n-1}_{i=1}(1-\beta^{t-i})g_i \\ &=\theta_1 - \sum^{t-1}_{i=1}(1-\beta^{t-i})g_i \end{aligned} vn=βtv0+(1−β)(θt+βθt−1+β2θt−2+⋯+βn−1θ1)=βtv0+(1−β)(θ1−i=1∑t−1gi+β(θ1−i=1∑t−2gi)+⋯+βt−2(θ1−i=1∑1gi)+βt−1θ1)=βtv0+(1−βt)θ1−i=1∑n−1(1−βt−i)gi=θ1−i=1∑t−1(1−βt−i)gi
普通的参数权重相当于一直累积更新整个训练过程的梯度,使用EMA的参数权重相当于使用训练过程梯度的加权平均(刚开始的梯度权值很小)。由于刚开始训练不稳定,得到的梯度给更小的权值更为合理,所以EMA会有效。
代码实现
class EMA(nn.Module):def __init__(self, model, decay=0.9999, device=None):super(EMA, self).__init__()# make a copy of the model for accumulating moving average of weightsself.module = deepcopy(model)self.module.eval()self.decay = decay# perform ema on different device from model if setself.device = deviceif self.device is not None:self.module.to(device=device)def _update(self, model, update_fn):with torch.no_grad():for ema_v, model_v in zip(self.module.state_dict().values(), model.state_dict().values):if self.device is not None:model_v = model_v.to(device=self.device)ema_v.copy_(update_fn(ema_v, model_v))def update(self, model):self._update(model, update_fn=lambda e, m: self.decay * e + (1. - self.decay) * m)def set(self, model):self._update(model, update_fn=lambda e, m: m)
class LitEma(nn.Module):def __init__(self, model, decay=0.9999, use_num_upates=True):super().__init__()if decay < 0.0 or decay > 1.0:raise ValueError('Decay must be between 0 and 1')self.m_name2s_name = {}self.register_buffer('decay', torch.tensor(decay, dtype=torch.float32))self.register_buffer('num_updates', torch.tensor(0, dtype=torch.int) if use_num_upateselse torch.tensor(-1, dtype=torch.int))for name, p in model.named_parameters():if p.requires_grad:# remove as '.'-character is not allowed in bufferss_name = name.replace('.', '')self.m_name2s_name.update({name: s_name})self.register_buffer(s_name, p.clone().detach().data)self.collected_params = []def forward(self, model):decay = self.decayif self.num_updates >= 0:self.num_updates += 1decay = min(self.decay, (1 + self.num_updates) / (10 + self.num_updates))one_minus_decay = 1.0 - decaywith torch.no_grad():m_param = dict(model.named_parameters())shadow_params = dict(self.named_buffers())for key in m_param:if m_param[key].requires_grad:sname = self.m_name2s_name[key]shadow_params[sname] = shadow_params[sname].type_as(m_param[key])shadow_params[sname].sub_(one_minus_decay * (shadow_params[sname] - m_param[key]))else:assert not key in self.m_name2s_namedef copy_to(self, model):m_param = dict(model.named_parameters())shadow_params = dict(self.named_buffers())for key in m_param:if m_param[key].requires_grad:m_param[key].data.copy_(shadow_params[self.m_name2s_name[key]].data)else:assert not key in self.m_name2s_namedef store(self, parameters):"""Save the current parameters for restoring later.Args:parameters: Iterable of `torch.nn.Parameter`; the parameters to betemporarily stored."""self.collected_params = [param.clone() for param in parameters]def restore(self, parameters):"""Restore the parameters stored with the `store` method.Useful to validate the model with EMA parameters without affecting theoriginal optimization process. Store the parameters before the`copy_to` method. After validation (or model saving), use this torestore the former parameters.Args:parameters: Iterable of `torch.nn.Parameter`; the parameters to beupdated with the stored parameters."""for c_param, param in zip(self.collected_params, parameters):param.data.copy_(c_param.data)