使用亮数据代理IP爬取PubMed文章链接和邮箱地址
- 💂 个人网站:【 摸鱼游戏】【神级代码资源网站】【工具大全】
- 🤟 一站式轻松构建小程序、Web网站、移动应用:👉注册地址
- 🤟 基于Web端打造的:👉轻量化工具创作平台
- 💅 想寻找共同学习交流,摸鱼划水的小伙伴,请点击【全栈技术交流群】
目录
- 背景
- 爬取文章链接
- 使用代理 IP 进行爬取
- 爬取邮箱地址
- 完整代码
- 总结
背景
最近有同事询问我是否能够帮忙从 PubMed 网站上批量爬取一些邮箱地址,因为其中可能包含我们的潜在客户。我开始尝试了一下,首先选择了一个关键词 h3k56 进行搜索,得到了 228 个结果(文章)。
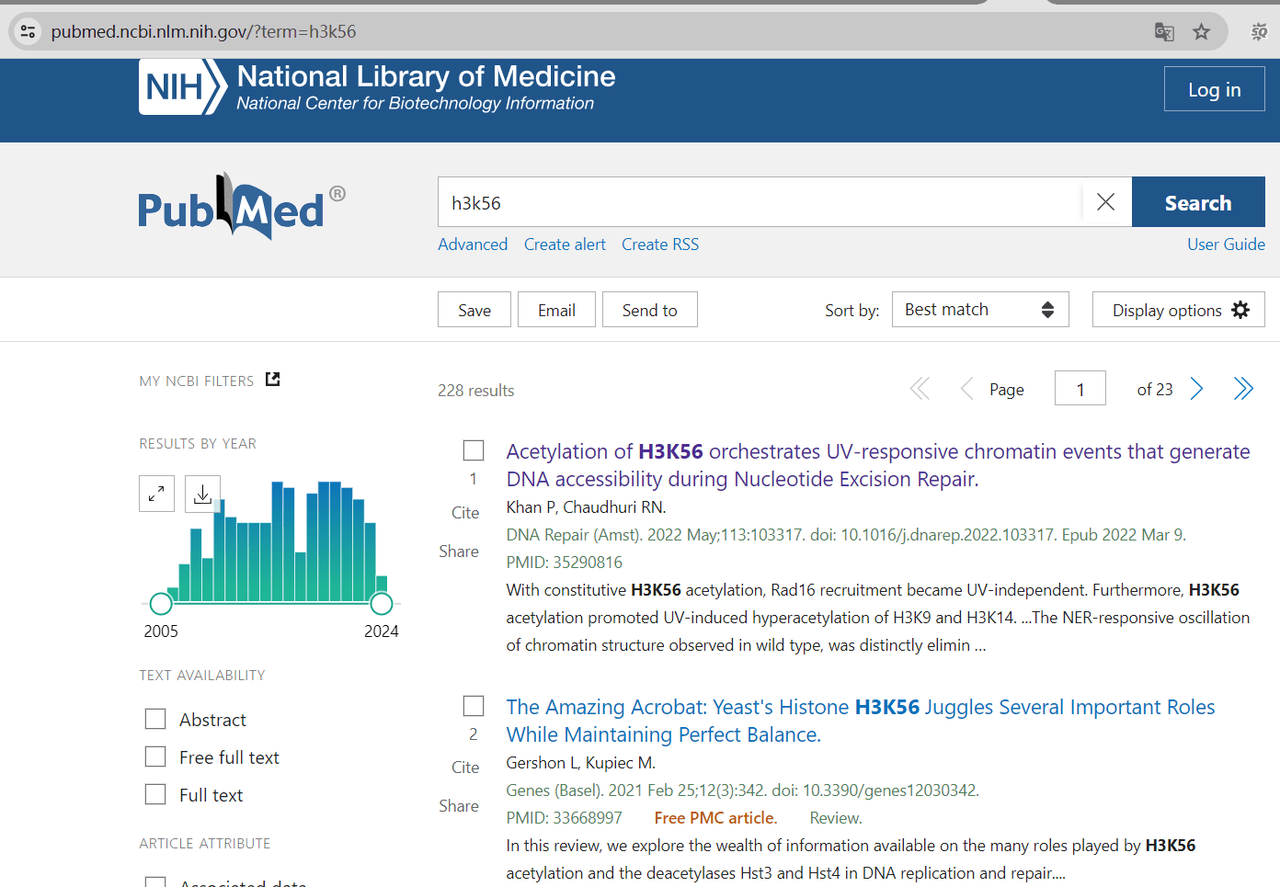
爬取文章链接
我们首先需要获取这些文章的链接。在 PubMed 网站上,每个页面只显示十篇文章,并且链接是按照一定规律排列的。
我们可以将搜索关键词 ‘h3k56’ 的 PubMed 搜索基础 URL 列出来:
base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page="
接下来,我们可以使用 requests 库发送 HTTP 请求,获取网页内容。我们先获取每个页面的文章链接,然后将这些链接存储在一个列表中。以下是具体步骤:
首先,我们导入了 requests 和 BeautifulSoup 库,它们用于发送 HTTP 请求和解析 HTML 页面。
import requests
from bs4 import BeautifulSoup
然后,我们定义了基础的 PubMed 搜索 URL base_url,用于搜索关键词 'h3k56',以及总共的页面数 total_pages 和用于存储文章链接的列表 article_links。
base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page=" # PubMed搜索基础URL,搜索关键词'h3k56'
total_pages = 23 # 总共的页面数
article_links = [] # 存储文章链接的列表
接下来,我们使用一个循环来遍历每一页的链接,并发送 HTTP 请求以获取页面内容。
for page_num in range(1, total_pages + 1):url = base_url + str(page_num) # 构建当前页面的完整URLresponse = requests.get(url) # 发起GET请求获取页面内容
在每次请求成功后,我们使用 BeautifulSoup 解析页面内容,查找具有 'docsum-title' 类的 <a> 标签,并提取其中的 href 属性,拼接成完整的文章链接,并将其添加到 article_links 列表中。
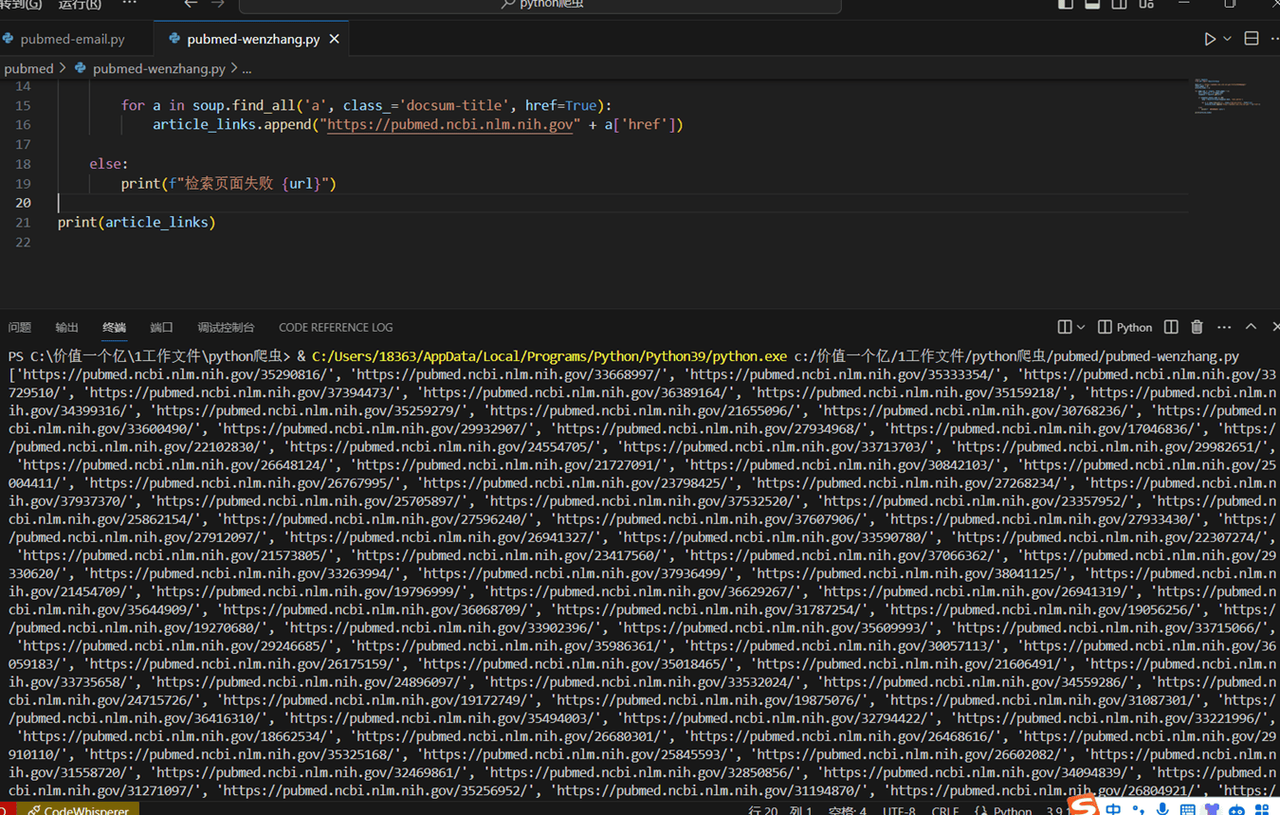
if response.status_code == 200: # 如果响应码为200,表示请求成功soup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析页面内容for a in soup.find_all('a', class_='docsum-title', href=True): # 查找具有'docsum-title'类的<a>标签article_links.append("https://pubmed.ncbi.nlm.nih.gov" + a['href']) # 将找到的文章链接添加到列表中
最后,我们打印出所有爬取到的文章链接列表。
print(article_links) # 打印所有文章链接列表
运行程序,大概等待了半分钟,完整输出了 228 篇文章的链接。
这样,我们就完成了获取 PubMed 文章链接的过程。接下来,我们将介绍如何使用代理 IP 进行爬取,并爬取文章中的邮箱地址。
好的,现在我们来继续介绍如何使用代理 IP 进行爬取,并爬取文章中的邮箱地址。
使用代理 IP 进行爬取
考虑到一些网站对频繁访问或大量请求会有限制,可能采取封禁IP或者设立验证码等措施。使用IP代理服务可以使爬虫在请求目标网站时轮换IP,从而规避了被网站封禁的风险。这里我采用的是亮数据IP代理服务。
首先,我们需要导入 requests 库,并定义一个代理 IP 的地址。假设代理 IP 的地址是 http://127.0.0.1:8000。
import requestsproxy = "http://127.0.0.1:8000"
接着,我们修改发送请求的方式,使用 requests.get 方法的 proxies 参数来设置代理 IP。
response = requests.get(url, proxies={"http": proxy, "https": proxy})
这样,我们就可以通过代理 IP 发送请求了。接下来我们获取文章中的邮箱地址。
爬取邮箱地址
为了使用Selenium库获取文章中的邮箱地址,我们首先需要导入相关的库。Selenium是一个自动化测试工具,可以模拟用户在浏览器中的操作,比如点击、输入、提交表单等。
from selenium import webdriver
import re
import time
然后,我们需要设置Chrome浏览器的选项,以及要爬取的文章链接列表和存储提取到的邮箱地址的列表。
# 设置ChromeOptions以指定Chrome二进制文件位置和其他选项
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe" # 请根据你的Chrome安装路径进行修改# 加载ChromeDriver并应用Chrome选项
driver = webdriver.Chrome(options=chrome_options)# 要爬取的文章链接列表
article_links = ['https://pubmed.ncbi.nlm.nih.gov/35290816/', 'https://pubmed.ncbi.nlm.nih.gov/33668997/', ...] # 这里省略了大部分链接# 存储提取到的邮箱地址
email_addresses = []
然后我们可以使用Selenium模拟浏览器打开每个文章链接,并从页面中提取邮箱地址。
# 遍历文章链接列表
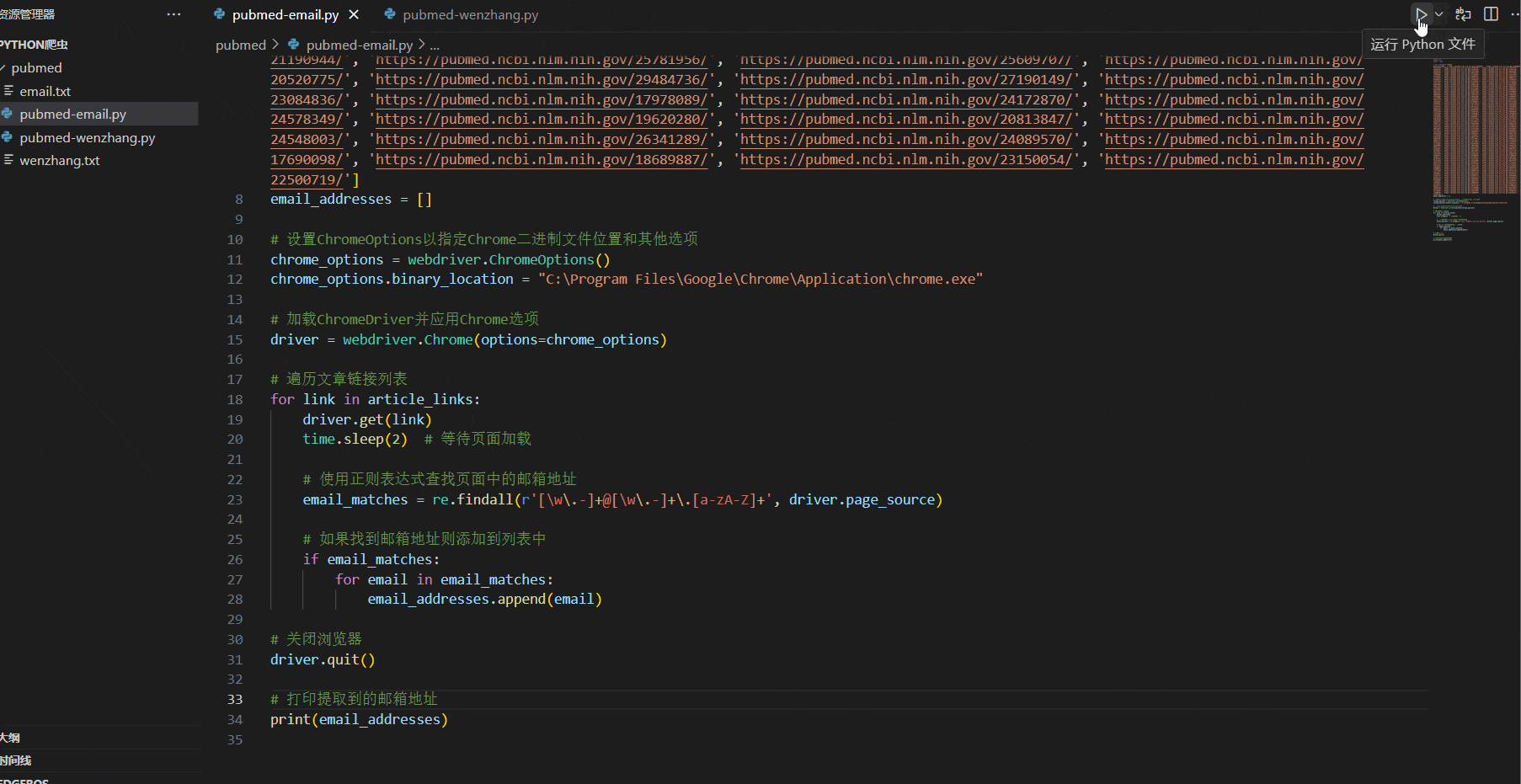
for link in article_links:driver.get(link)time.sleep(2) # 等待页面加载# 使用正则表达式查找页面中的邮箱地址email_matches = re.findall(r'[\w\.-]+@[\w\.-]+\.[a-zA-Z]+', driver.page_source)# 如果找到邮箱地址则添加到列表中if email_matches:for email in email_matches:email_addresses.append(email)
最后,关闭浏览器并打印提取到的邮箱地址。
# 关闭浏览器
driver.quit()# 打印提取到的邮箱地址
print(email_addresses)
这样,我们就可以使用Selenium库在每个文章链接中提取到邮箱地址了。
运行效果如下,selenium 会自动打开浏览器,访问这两百多个页面
待页面访问完成即可输出邮箱地址
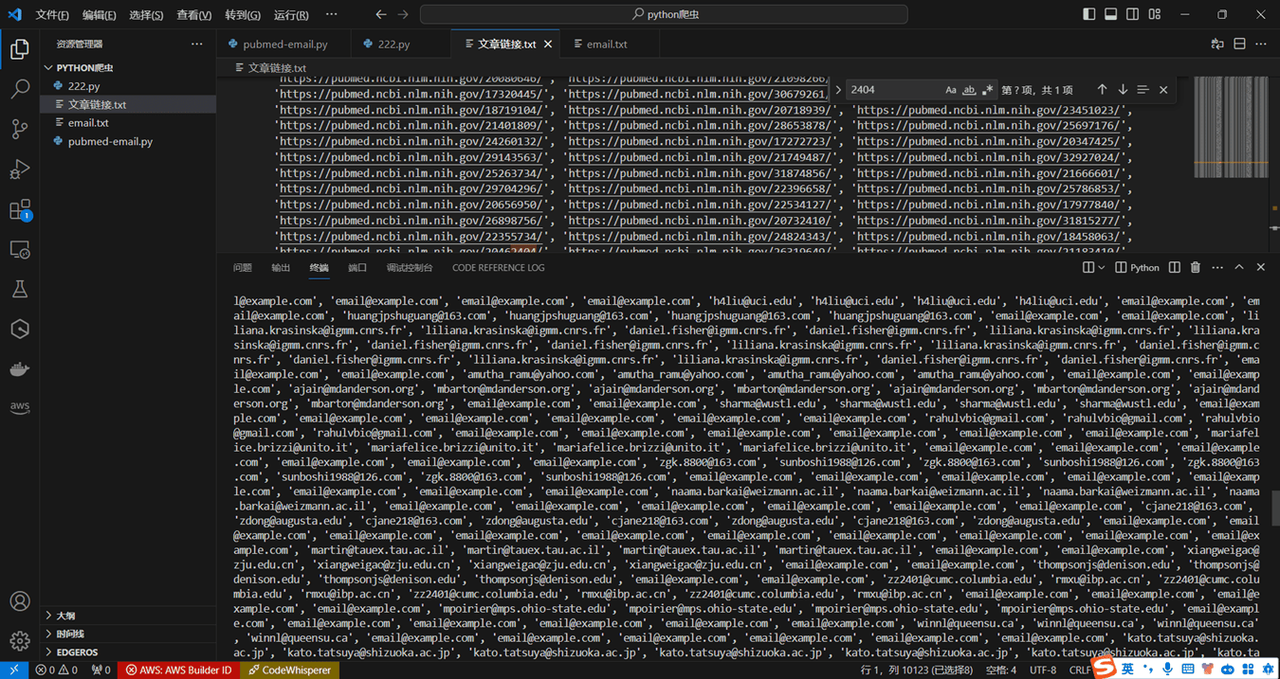
到这里我们就大功告成了。
完整代码
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import re
import time# 定义代理IP地址
proxy = {'http': 'http://your_proxy_ip:your_proxy_port','https': 'https://your_proxy_ip:your_proxy_port'
}# 设置请求头
headers = {'User-Agent': 'Your User Agent'
}# 设置ChromeOptions以指定Chrome二进制文件位置和其他选项
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe" # 请根据你的Chrome安装路径进行修改
chrome_options.add_argument('--proxy-server=http://your_proxy_ip:your_proxy_port') # 添加代理IP地址# 加载ChromeDriver并应用Chrome选项
driver = webdriver.Chrome(options=chrome_options)# PubMed搜索基础URL,搜索关键词'h3k56'
base_url = "https://pubmed.ncbi.nlm.nih.gov/?term=h3k56&page="# 总共的页面数
total_pages = 23# 存储文章链接的列表
article_links = []# 遍历页面获取文章链接
for page_num in range(1, total_pages + 1):url = base_url + str(page_num) # 构建当前页面的完整URLtry:# 发起GET请求获取页面内容response = requests.get(url, headers=headers, proxies=proxy)if response.status_code == 200: # 如果响应码为200,表示请求成功soup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析页面内容for a in soup.find_all('a', class_='docsum-title', href=True): # 查找具有'docsum-title'类的<a>标签article_links.append("https://pubmed.ncbi.nlm.nih.gov" + a['href']) # 将找到的文章链接添加到列表中else:print(f"检索页面失败 {url}") # 请求失败时输出错误信息except Exception as e:print(f"请求异常: {e}")# 打印所有文章链接列表
print(article_links)# 存储提取到的邮箱地址
email_addresses = []# 遍历文章链接列表并提取邮箱地址
for link in article_links:try:driver.get(link)time.sleep(2) # 等待页面加载# 使用正则表达式查找页面中的邮箱地址email_matches = re.findall(r'[\w\.-]+@[\w\.-]+\.[a-zA-Z]+', driver.page_source)# 如果找到邮箱地址则添加到列表中if email_matches:for email in email_matches:email_addresses.append(email)except Exception as e:print(f"提取邮箱地址异常: {e}")# 关闭浏览器
driver.quit()# 打印提取到的邮箱地址
print(email_addresses)总结
以上是一个简单的爬虫示例,展示了如何使用亮数据的IP代理服务来爬取网页链接以及邮箱地址。通过亮数据的IP代理服务,我们可以轻松地突破网站的封锁,实现数据的高效获取。希望通过以上示例能够帮助大家更好地理解IP代理服务的重要性和使用方法。
如果您对IP代理服务感兴趣,可以通过亮数据官网了解更多信息。