Java文件操作①——XML文件的读取
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、邂逅XML
- 二、应用 DOM 方式解析 XML
- 三、应用 SAX 方式解析 XML
- 四、应用 DOM4J 及 JDOM 方式解析 XML
- JDOM 方式解析 XML
- DOM4J 方式解析 XML
前言
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。

一、邂逅XML
文件种类是丰富多彩的,XML作为众多文件类型的一种,经常被用于数据存储和传输。所以XML在现今应用程序中是非常流行的。本文主要讲Java解析和生成XML。用于不同平台、不同设备间的数据共享通信。
XML文件的表现:以“.xml”为文件扩展名的文件;
存储结构:树形结构;
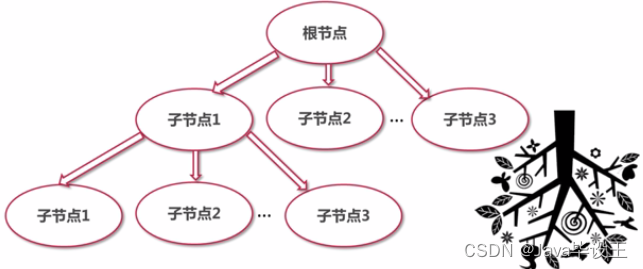
节点名称区分大小写。
1、 id为属性, 1 id为节点
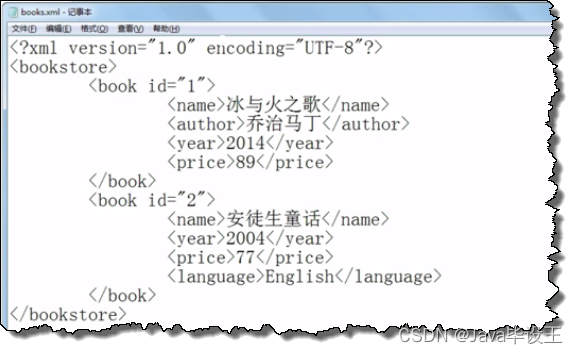
2、xml文件开头要加上版本信息和编码方式<?xml version="1.0" encoding="UTF-8"?>
比如:
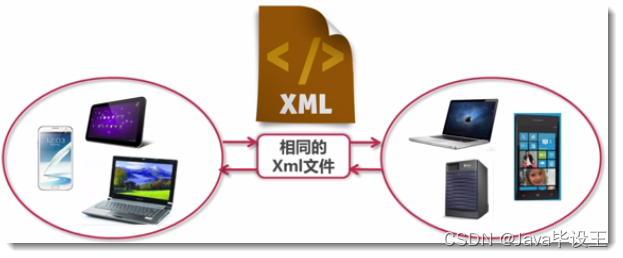
❤ 为什么要使用XML?
思考1:不同应用程序之间的通信?

思考2:不同平台间的通信?

思考3:不同平台间的数据共享?

答案就是我们要学习的XML文件。我们可以使用相同的xml把不同的文件联系起来
二、应用 DOM 方式解析 XML
❤ 在Java程序中如何获取XML文件的内容

解析的目的:获取节点名、节点值、属性名、属性值;
四种解析方式:DOM、SAX、DOM4J、JDOM
DOM、SAX :java 官方方式,不需要下载jar包
DOM4J、JDOM :第三方,需要网上下载jar包
示例:解析XML文件,目标是解析XML文件后,Java程序能够得到xml文件的所有数据
思考:如何在Java程序中保留xml数据的结构?
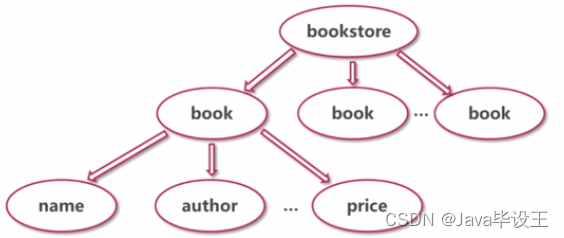
如何保留节点之间的层级关系?
注意常用的节点类型:

下面介绍DOM方式解析XML:
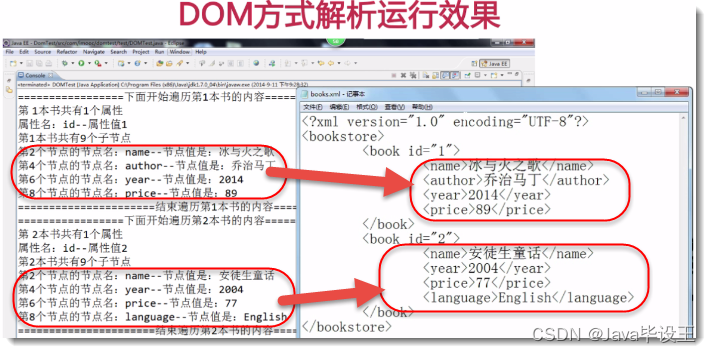
功能说明:


代码示例:
package com.study.domtest;import java.io.IOException;import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;/*** DOM方式解析xml*/
public class DOMTest {public static void main(String[] args) {//1、创建一个DocumentBuilderFactory的对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();//2、创建一个DocumentBuilder的对象try {//创建DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//3、通过DocumentBuilder对象的parser方法加载books.xml文件到当前项目下/*注意导入Document对象时,要导入org.w3c.dom.Document包下的*/Document document = db.parse("books.xml");//传入文件名可以是相对路径也可以是绝对路径//获取所有book节点的集合NodeList bookList = document.getElementsByTagName("book");//通过nodelist的getLength()方法可以获取bookList的长度System.out.println("一共有" + bookList.getLength() + "本书");//遍历每一个book节点for (int i = 0; i < bookList.getLength(); i++) {System.out.println("=================下面开始遍历第" + (i + 1) + "本书的内容=================");//❤未知节点属性的个数和属性名时://通过 item(i)方法 获取一个book节点,nodelist的索引值从0开始Node book = bookList.item(i);//获取book节点的所有属性集合NamedNodeMap attrs = book.getAttributes();System.out.println("第 " + (i + 1) + "本书共有" + attrs.getLength() + "个属性");//遍历book的属性for (int j = 0; j < attrs.getLength(); j++) {//通过item(index)方法获取book节点的某一个属性Node attr = attrs.item(j);//获取属性名System.out.print("属性名:" + attr.getNodeName());//获取属性值System.out.println("--属性值" + attr.getNodeValue());}//❤已知book节点有且只有1个id属性:/*//前提:已经知道book节点有且只能有1个id属性//将book节点进行强制类型转换,转换成Element类型Element book1 = (Element) bookList.item(i);//通过getAttribute("id")方法获取属性值String attrValue = book1.getAttribute("id");System.out.println("id属性的属性值为" + attrValue);*///解析book节点的子节点NodeList childNodes = book.getChildNodes();//遍历childNodes获取每个节点的节点名和节点值System.out.println("第" + (i+1) + "本书共有" + childNodes.getLength() + "个子节点");for (int k = 0; k < childNodes.getLength(); k++) {//区分出text类型的node以及element类型的nodeif(childNodes.item(k).getNodeType() == Node.ELEMENT_NODE){//获取了element类型节点的节点名System.out.print("第" + (k + 1) + "个节点的节点名:" + childNodes.item(k).getNodeName());//获取了element类型节点的节点值System.out.println("--节点值是:" + childNodes.item(k).getFirstChild().getNodeValue());<