集成算法实验与分析(软投票与硬投票)
概述
目的:让机器学习效果更好,单个不行,集成多个
集成算法
Bagging:训练多个分类器取平均
f ( x ) = 1 / M ∑ m = 1 M f m ( x ) f(x)=1/M\sum^M_{m=1}{f_m(x)} f(x)=1/M∑m=1Mfm(x)
Boosting:从弱学习器开始加强,通过加权来进行训练
F m ( x ) = F m − 1 ( x ) + a r g m i n h ∑ i = 1 n L ( y i , F m − 1 ( x i ) + h ( x i ) ) F_m(x)=F_{m-1}(x)+argmin_h\sum^n_{i=1}L(y_i,F_{m-1}(x_i)+h(x_i)) Fm(x)=Fm−1(x)+argminh∑i=1nL(yi,Fm−1(xi)+h(xi))
(加入一棵树,新的树更关注之前错误的例子)
Stacking:聚合多个分类或回归模型(可以分阶段来做)
Bagging模型(随机森林)
全称: bootstrap aggregation(说白了就是并行训练一堆分类器)
最典型的代表就是随机森林,现在Bagging模型基本上也是随机森林。
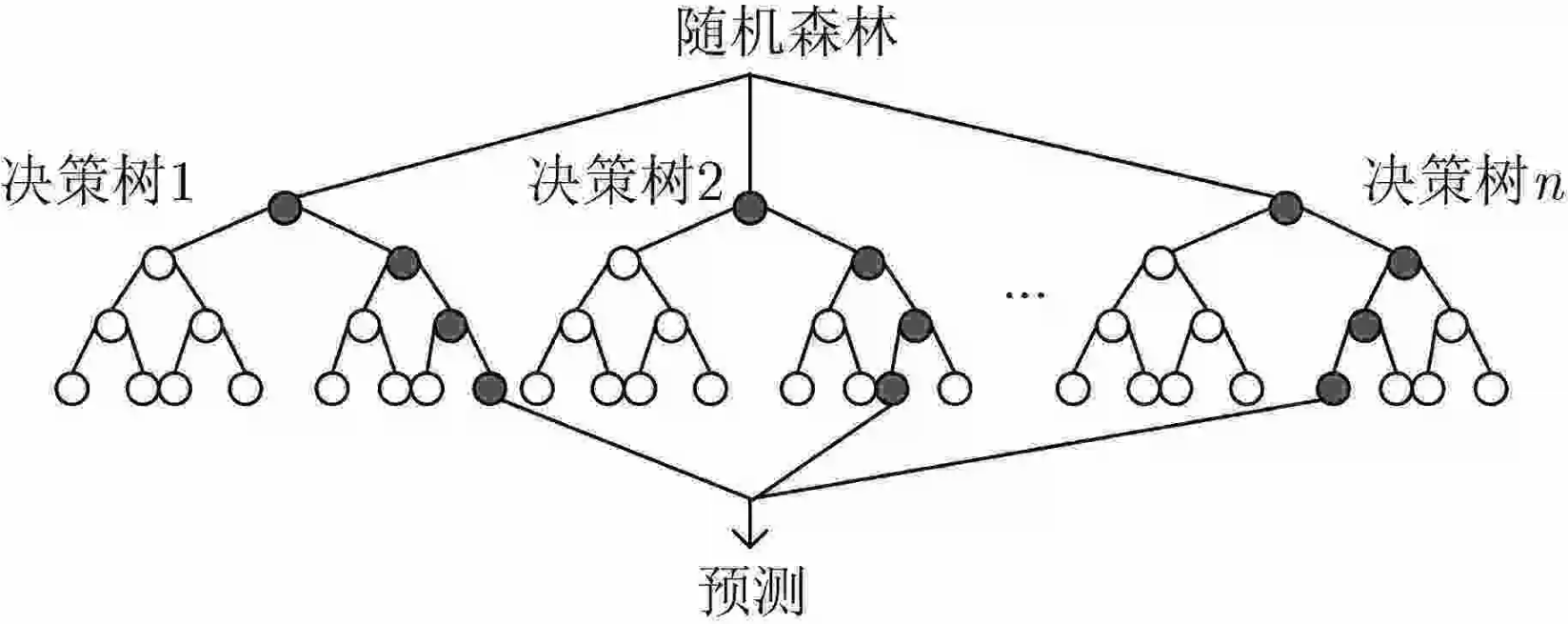
随机:数据采样随机,每棵树只用部分数据;数据有多个特征(属性)组成,每棵树随机选择部分特征。随机是为了使得每个分类器拥有明显差异性。
森林:很多个决策树并行放在一起
如何对所有树选择最终结果?分类的话可以采取少数服从多数,回归的话可以采用取平均值。
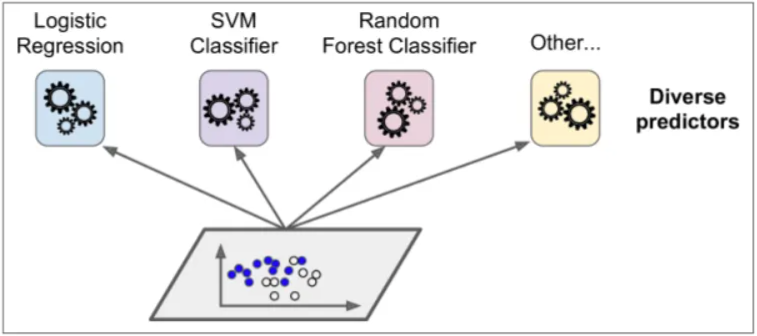
集成基本思想
训练时用多种分类器一起完成同一份任务
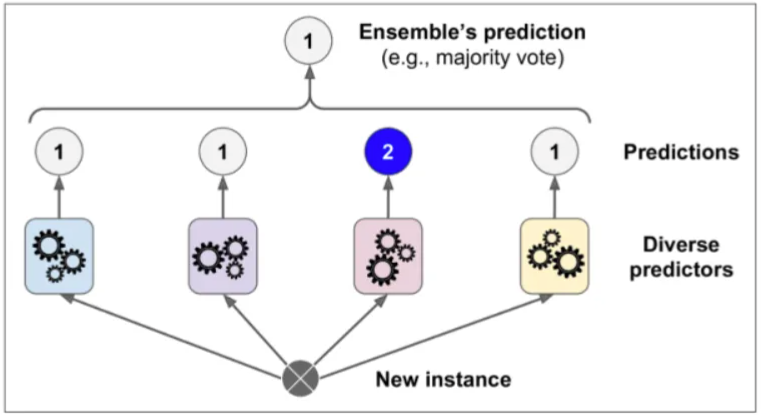
测试时对待测试样本分别通过不同的分类器,汇总最后的结果
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(42)
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moonsX,y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha = 0.6)
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha = 0.6)
投票策略:软投票与硬投票
- 硬投票:直接用类别值,少数服从多数
- 软投票:各自分类器的概率值进行加权平均,或者自己就去概率值最大的作为结果
硬投票实验
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC# 三种分类器,逻辑回归,随机森林,支持向量机
log_clf = LogisticRegression(random_state=42)
rnd_clf = RandomForestClassifier(random_state=42)
svm_clf = SVC(random_state=42)voting_clf = VotingClassifier(estimators =[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='hard')
voting_clf.fit(X_train,y_train)
from sklearn.metrics import accuracy_score
print('三种分类器的结果')
for clf in (log_clf,rnd_clf,svm_clf):clf.fit(X_train,y_train)y_pred = clf.predict(X_test)print (clf.__class__.__name__,accuracy_score(y_test,y_pred))
print('集成分类的硬投票结果(一般会在效果上有微量提升,但不会太大)')
voting_clf.fit(X_train,y_train)
y_pred = voting_clf.predict(X_test)
print (voting_clf.__class__.__name__,accuracy_score(y_test,y_pred))
结果输出:
三种分类器的结果
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896
集成分类的结果(一般会在效果上有微量提升,但不会太大)
VotingClassifier 0.912
软投票实验
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVClog_clf = LogisticRegression(random_state=42)
rnd_clf = RandomForestClassifier(random_state=42)
svm_clf = SVC(probability = True,random_state=42)voting_clf = VotingClassifier(estimators =[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='soft')
from sklearn.metrics import accuracy_score
print('三种分类器的结果')
for clf in (log_clf,rnd_clf,svm_clf):clf.fit(X_train,y_train)y_pred = clf.predict(X_test)print (clf.__class__.__name__,accuracy_score(y_test,y_pred))
print('集成分类的软投票结果(一般会在效果上有微量提升,但不会太大)')
voting_clf.fit(X_train,y_train)
y_pred = voting_clf.predict(X_test)
print (voting_clf.__class__.__name__,accuracy_score(y_test,y_pred))
结果输出:
三种分类器的结果
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896
集成分类的硬投票结果(一般会在效果上有微量提升,但不会太大)
VotingClassifier 0.92
总结:软投票要求必须各个分别器都能得出概率值,一般来说软投票效果更好一些