ANAH数据集- 大模型幻觉细粒度评估工具
大型语言模型(LLMs)在各种自然语言处理任务中取得了显著的性能提升。然而,它们在回答用户问题时仍面临一个令人担忧的问题,即幻觉,它们会产生听起来合理但不符合事实或无意义的信息,尤其是当问题需要大量知识时。鉴于LLMs生成的回应的流畅性和说服力,检测它们的幻觉变得越来越困难。这样的挑战阻碍了对LLM幻觉的深入分析和减少,并导致随着用户群的扩大和现实世界应用的增多,误导性信息的广泛传播。
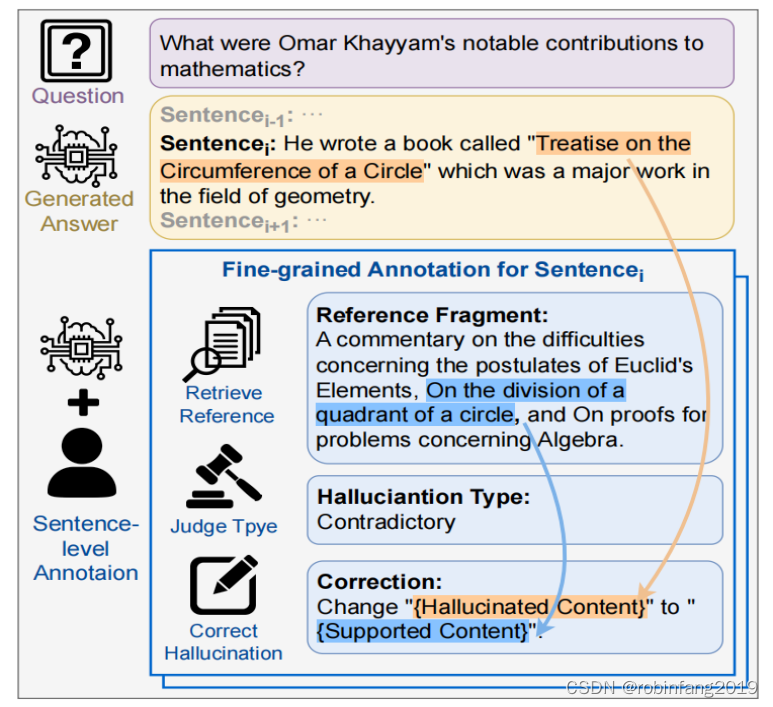
最近为LLMs提出的基准测试只是将整个响应是否包含幻觉进行分类,没有解释和参考。这种粗糙的性质使得很难追踪幻觉的确切触发因素,阻碍了进一步减轻幻觉的措施。因此,我们建立了一个新的大规模中英文基准测试,名为ANAH,它评估LLMs在基于知识的生成性问答场景中逐句注释LLMs幻觉的能力。与仅以结果为导向的方法不同,我们的方法促使模型对每个问题的答案进行注释,包括检索参考片段、判断幻觉类型(无/矛盾/无法验证的幻觉和无事实),如果存在幻觉,则根据参考片段纠正句子,如下图:
1、数据集的构建
ANAH数据集的建立包含四个阶段:

1.1 主题选择和参考资料检索
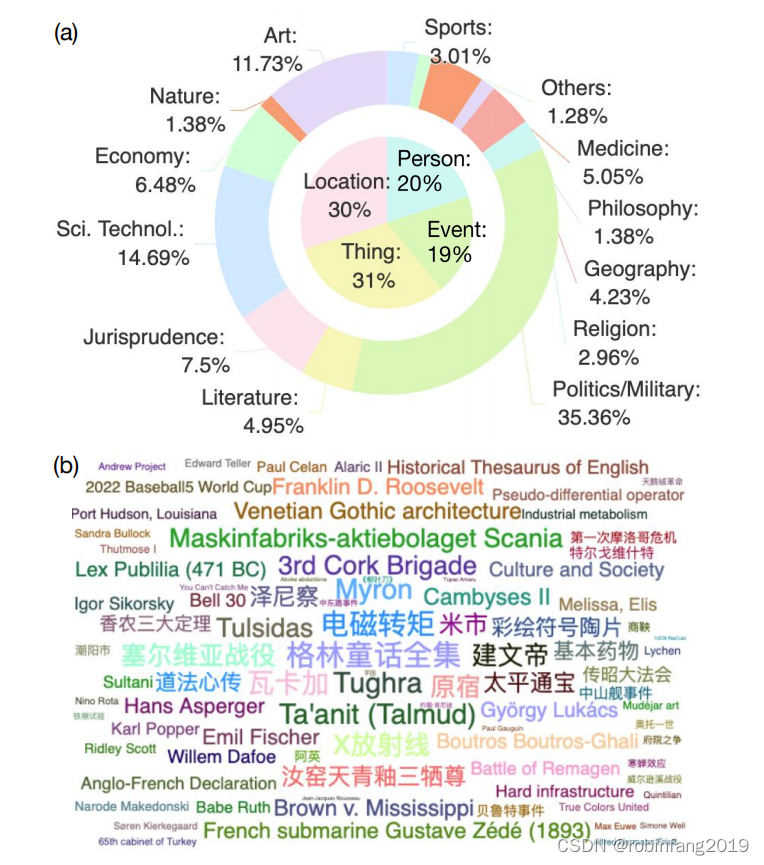
初始阶段涉及从知识密集型数据集中选择主题和相应的参考资料。为确保信息的多元化和广泛性,我们的主题选择被归类为名人、事件、地点和事物,涵盖了包括政治军事、艺术、科学技术、宗教等多个领域。主题是基于它们通过Google Ngram Viewer的出现频率来精心挑选的,因为更频繁出现且公众感兴趣的主题对LLMs的实际应用更为重要。
1.2 问题生成与选择
根据特定主题的参考资料生成和选择几个问题。为增加数据未被见过且未被污染的可能性,我们创建新问题而不是重新利用现有数据集。这些问题被设计为可以完全基于提供的参考资料来回答,避免过于主观或开放式。为确保问题多样性和可理解性,它们旨在涵盖不同类型,如“什么”、“何时”、“何地”、“为什么”等,以及不同视角,如描述、解释、原因等,涵盖信息的所有方面。问题还涉及不同知识层次,从基础、通用知识到更复杂、专业化的知识或特定领域的专业知识。
使用GPT-4从上述候选问题中选择前三名问题,考虑以下特征:
- 高真实性:问题避免任何故意误导、含糊或虚假信息。
- 高可答性:表现出过度主观性、争议性或预测性的问题被排除。
- 难度适中:保证一定难度水平。
- 高多样性:在类型、复杂度、知识深度等方面增强整体多样性,排除相似问题。
1.3 答案生成
我们使用GPT-3.5带参考文档构建高质量答案,以及不带参考的早期版本的InternLM-7B生成低质量答案。这样的设计允许我们全面评估LLMs在不同场景下的幻觉注释能力。
1.4 细粒度幻觉注释
为注释者提供特定主题的文档和相关问题。对于每个答案句子,完整的注释包括找到确切相关的参考片段、评估幻觉类型,并相应地纠正幻觉。
为减少大量的时间和人力,并保持准确性,我们采用GPT-4进行初步注释,然后由人工注释者进行验证和完善。
2、幻觉标注
查找参考片段:注释者需要在提供的文档中找到与答案句子直接相关的参考片段。
评估幻觉类型:基于找到的参考片段,对答案句子进行幻觉类型的评估。幻觉类型分为以下几种:
- 无幻觉(No Hallucination):如果句子包含的事实信息与参考文档一致,且注释者能够找到具体的参考片段,则将该句子的幻觉类型标记为“无幻觉”。
- 矛盾幻觉(Contradictory Hallucination):如果答案句子与参考文档相矛盾,需要标记为“矛盾幻觉”,并提供具体的参考片段以及对答案进行修正的建议。
- 无法验证的幻觉(Unverifiable Hallucination):如果答案句子缺乏支持证据,无法在参考文档中找到验证,则将其标记为“无法验证的幻觉”,并提供修正建议。
- 无事实(No Fact):如果句子中没有包含可供评估的事实信息,则将其归类为“无事实”,并且不需要进一步的注释。
纠正幻觉:在评估了幻觉类型之后,需要根据参考片段对存在幻觉的答案句子进行相应的纠正。这包括提出修改建议,如何将包含幻觉的内容更改为与参考文档一致或可验证的信息。
3、实验与结论
3.1 实验细节
3.1.1 数据分割
ANAH数据集被分为训练集和测试集。为了研究注释器的泛化方向和数据集规模,我们进一步将测试集均等地划分为未见过话题(unseen-topic)和未见过问题(unseen-question)两个组。在未见过话题测试集中,话题及其相关的参考资料、问题和答案在训练期间未被暴露。在未见过问题测试集中,话题在训练期间已被暴露,但问题未被暴露。
3.1.2 实验设置
使用了不同的数据分割和评估设置,以评估模型在不同情况下的性能。例如,考虑了在训练中使用单一任务与多任务设置的影响,以及在测试中引入指令扰动(即测试指令与训练中未见过的指令)的影响。
3.1.3 评估模型
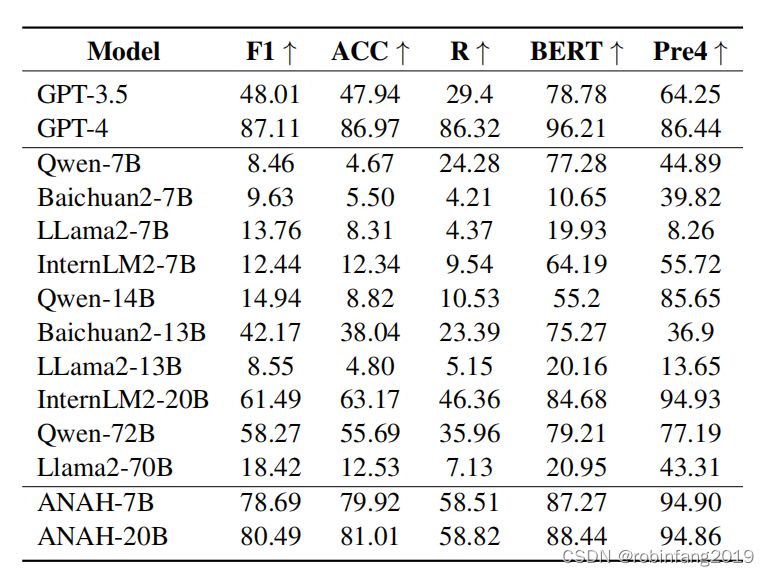
评估了多种不同大小的预训练语言模型,包括但不限于GPT-3.5、GPT-4、Qwen-7B、Baichuan2-7B、Llama2-7B等,以及在ANAH数据集上训练的模型。
3.1.4 评估指标
- F1 分数: 用于评估标注器预测的幻觉类型与人工标注的一致性。
- 准确率 (ACC): 用于评估标注器识别幻觉类型的能力。
- RougeL: 用于评估生成式标注器预测的参考片段与人工标注的参考片段在语法、连贯性、顺序和语义方面的相似度。
- BERTScore: 用于评估生成式标注器预测的修改建议与人工标注的修改建议在语法、连贯性、顺序和语义方面的相似度。
- n-gram 精确率: 用于评估生成式标注器预测的参考片段和修改建议是否忠实于原始文档。
3.2 结论
在整体测试集上的结果显示,当前的开源LLMs和GPT-3.5难以按照细粒度的方式注释幻觉,而GPT-4与人类注释的一致性较高。因此,利用ANAH的训练分割来训练我们的幻觉注释器。值得注意的是,ANAH-20B模型在F1分数上达到了80.49%,在准确率上达到了81.01%,超越了开源模型,并在性能上与GPT-4相媲美,同时模型尺寸更小,来源成本更低。