深入了解diffusion model
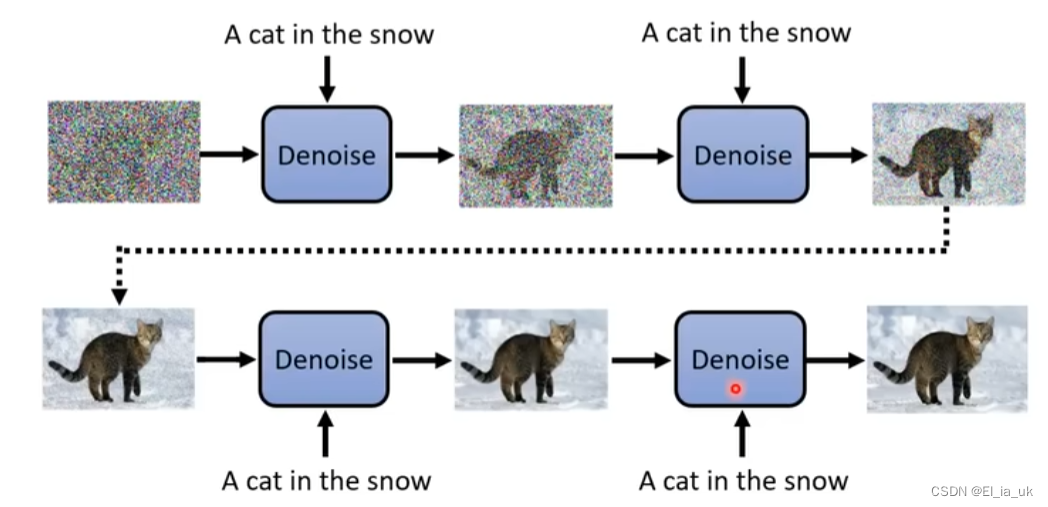
diffusion model是如何运作的
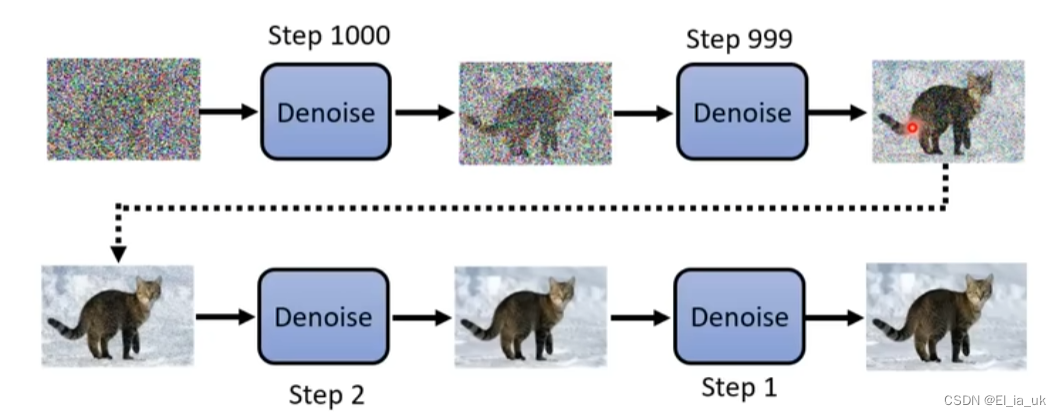

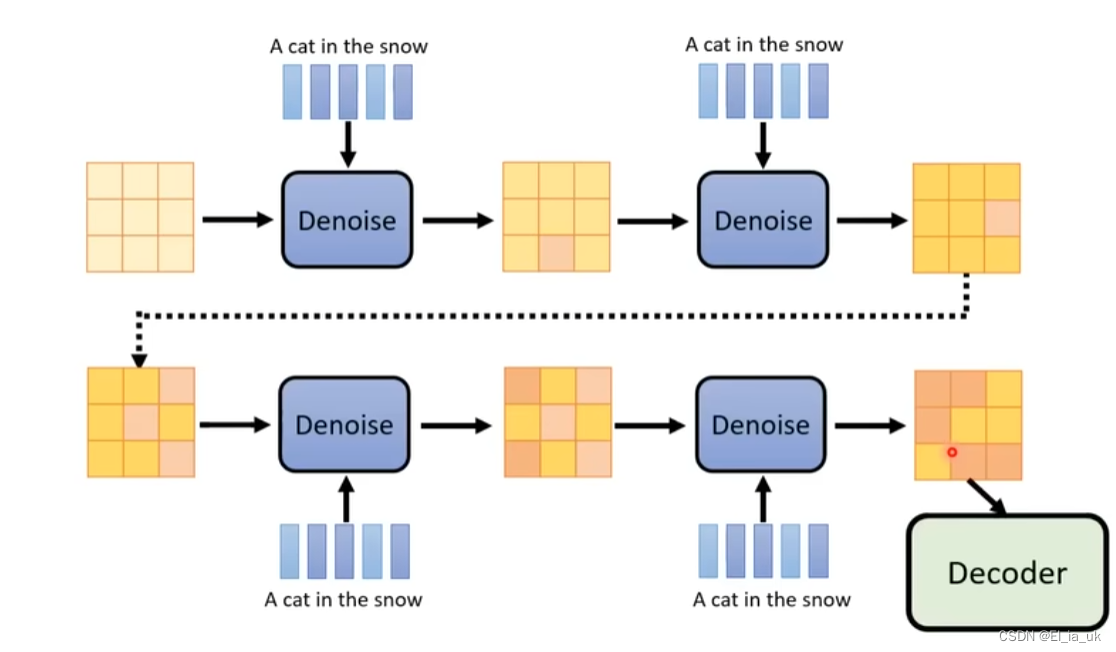
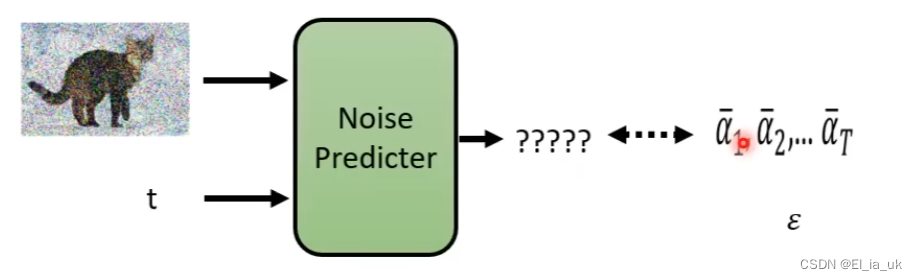
会输入当时noise的严重程度,根据我们的输入来确定在第几个step,并做出不同的回应。
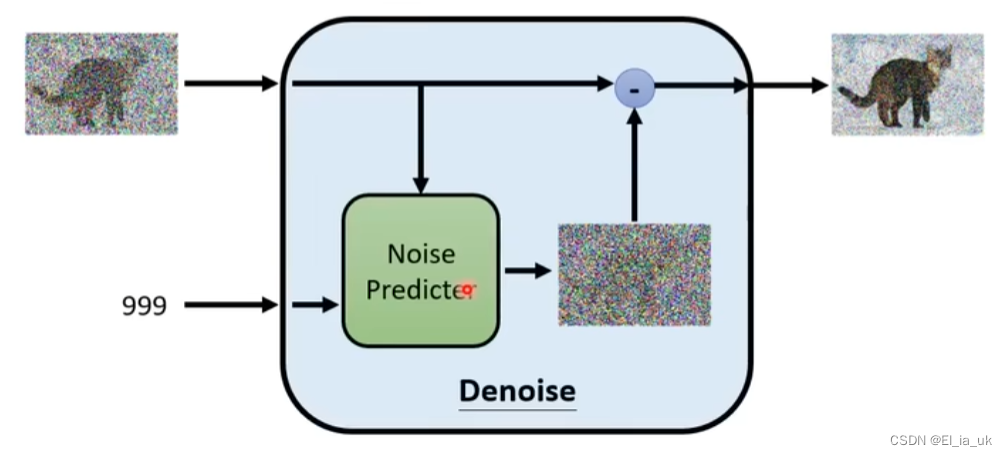
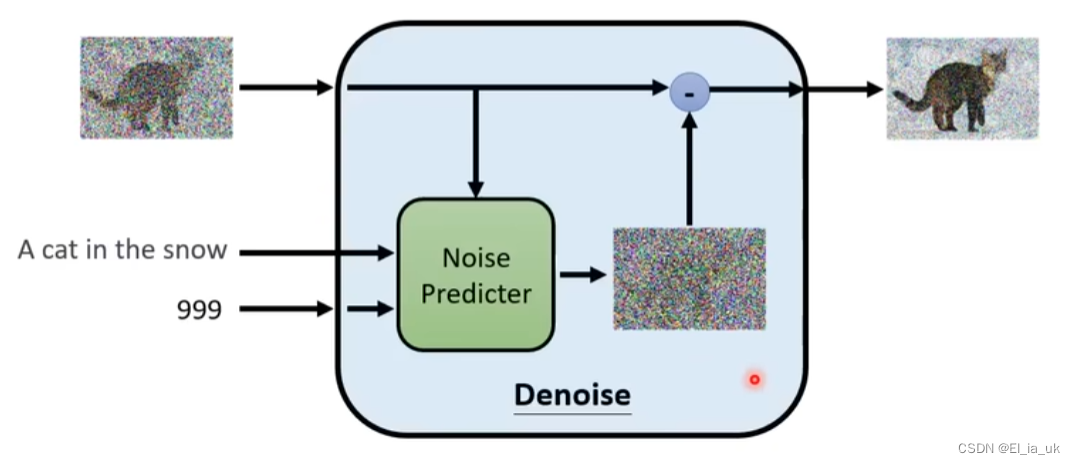
Denoise模组内部实际做的事情
产生一张图片和产生noise难度是不一样的,若denoise 模块产生一只带噪声的猫说明这个模块已经会画一只猫,所以产生一只带噪声的猫和产生图片中死亡噪声难度是不一样的
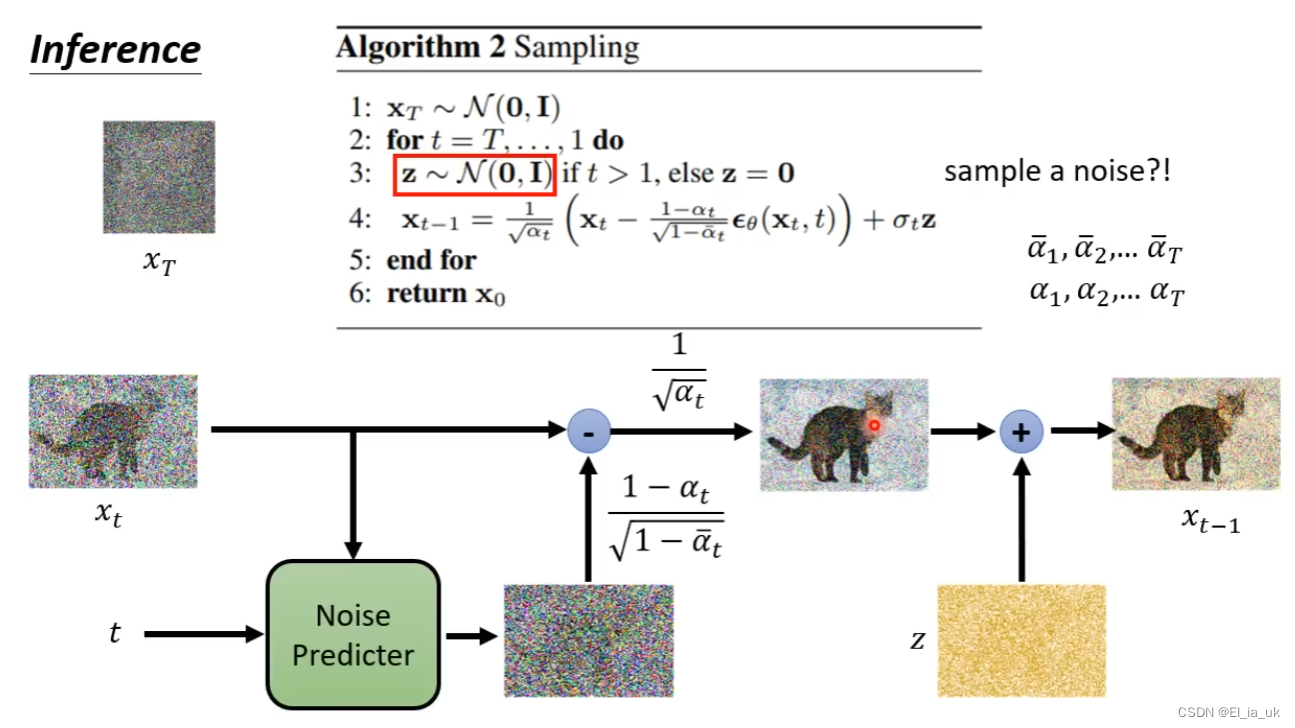
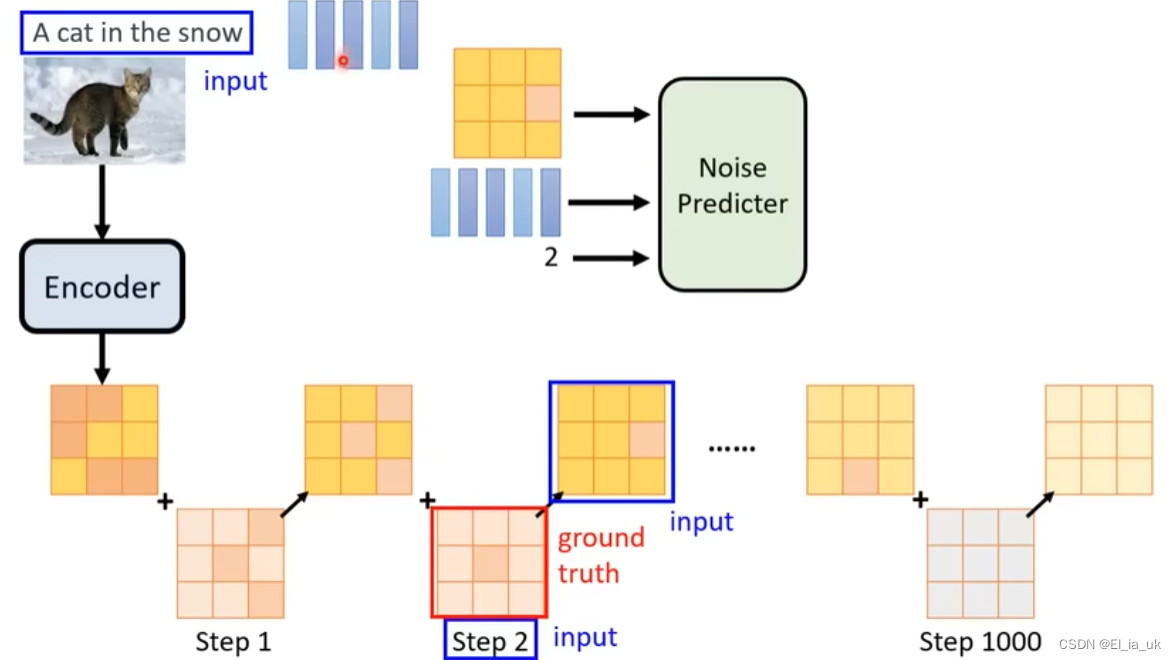
如何训练noise predictor
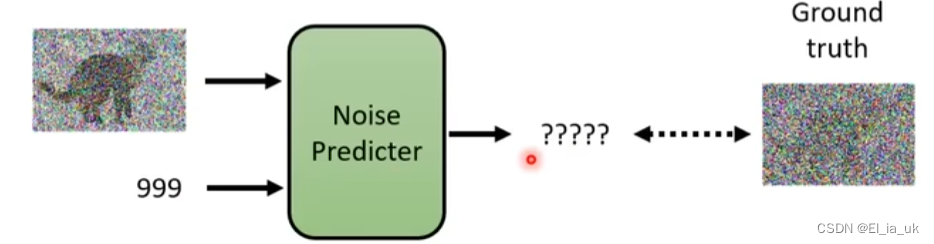
输入这张图片和step id 然后产生出一个预测中的噪声,但为了产生预测中的噪声,则需要输入这张图片的噪声是什么样子,才会学习如何把噪声输出。
noise predictor 的训练资料是人们创造出来的

Text-to-Image

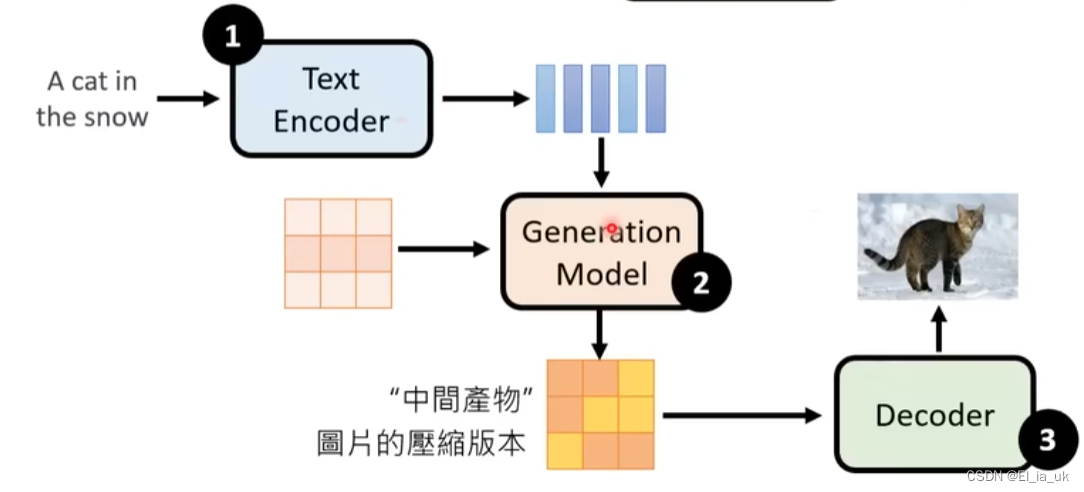
Stable Diffusion
内部有三个元件
1、Text Encoder:好的文字的encoder,会把一段文字变成向量
2、Generation Model:可以用其他model(如diffusion Model),用一个粉红色的矩阵表示以恶搞噪声,将噪声与文字的encode产生一个中间产物(为一张图片被压缩后的结果)
3、Decoder:把图片压缩后的版本还原成原图
第一元件:如何评估影像生成的模型好坏(常用FID Frechet Inception Distance)
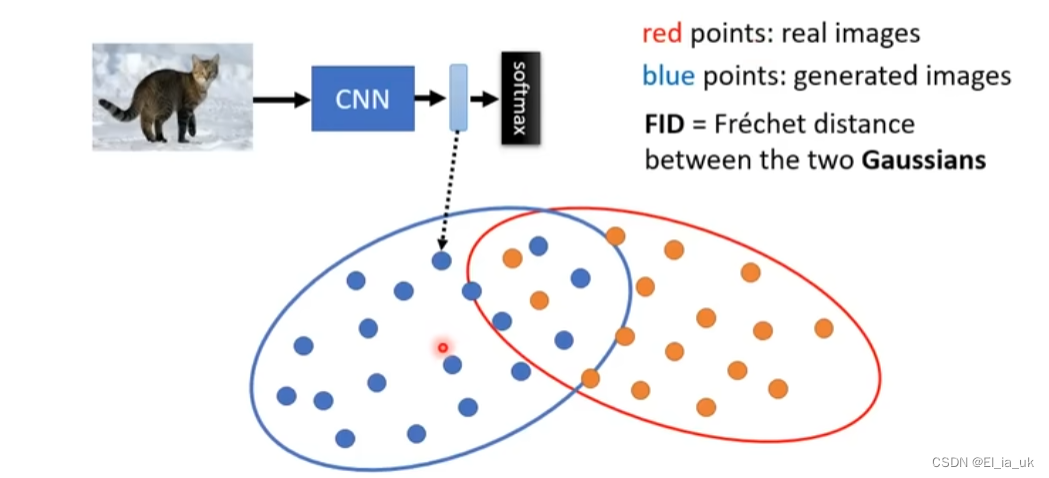
若这两组越接近,则表示生成的影像与原图更接近。
FID需要许多的图片
第三元件:它训练不需要文字的输入,可任意单凭影像的输入自动训练decoder
中间产物为:压缩后的图片
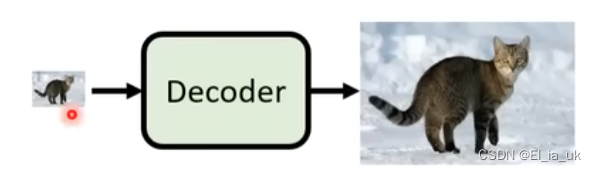
中间产物为:Latent Representation ,则应该如何训练decoder,把其还原成图片

需要训练一个Auto-encoder ,过程如下图所示:
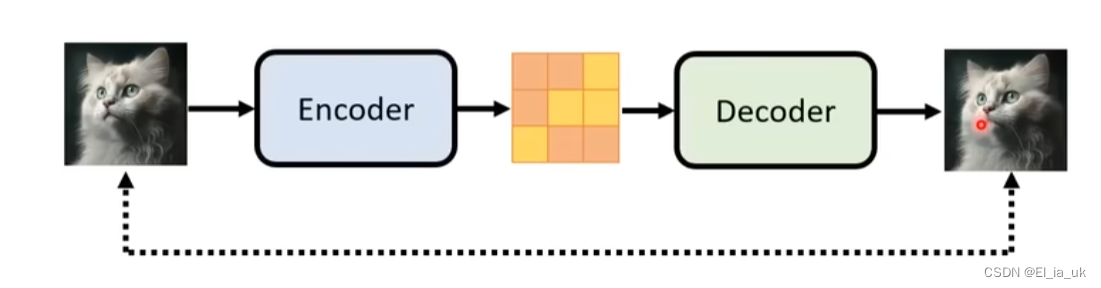
输入和输出的结果越接近越好。把训练好的decoder直接拿出来将Latent Representation还原成图片即可。
第二元件:generation model
 diffusion model的数学原理
diffusion model的数学原理
Training

第三行表示从1-T sample一个数出来, 第四行表示从normal distribution sample一个
第五行红色方框表示T越大表示所加的噪声越多
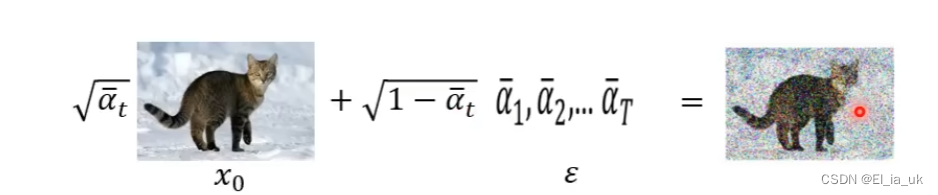
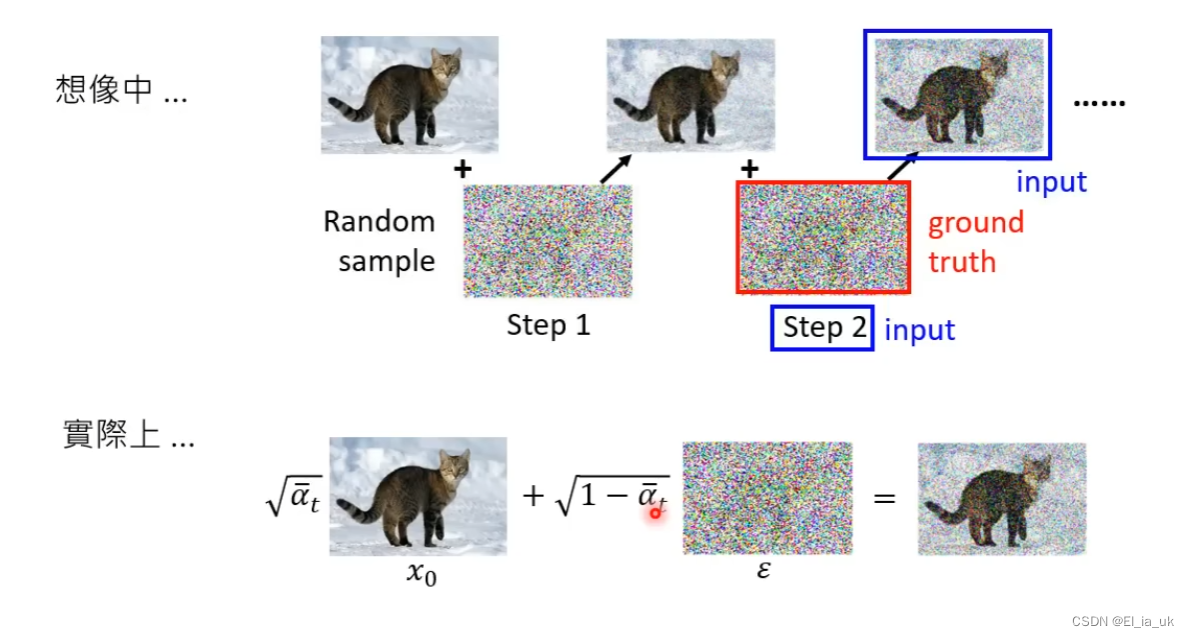
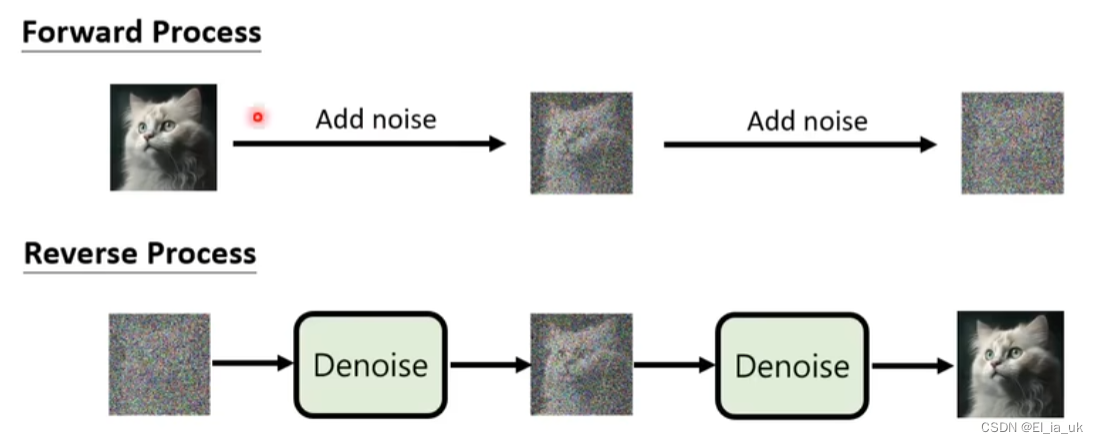
想象中噪声是一点一点加进去的, 去噪声也是把噪声一点一点的抹去,实际上真正做的事情并没有把噪声一点一点的加进去,噪声一次加入,去噪声也是一次便去除
sampling