【机器学习】随机森林:深度解析与应用实践


🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- 随机森林:深度解析与应用实践
- 引言
- 1. 随机森林基础
- 1.1 什么是随机森林?
- 1.2 随机森林的核心思想
- 2. 随机森林的构建过程
- 2.1 数据准备
- 2.2 构建决策树
- 2.3 集成预测
- 3. 关键参数与调优
- 3.1 树的数量(n_estimators)
- 3.2 特征随机选择的数量(max_features)
- 3.3 树的最大深度(max_depth)与节点最小样本数(min_samples_split)
- 4. 实际应用案例
- 4.1 信用评分
- 4.2 医疗诊断
- 4.3 推荐系统
- 5. 总结
随机森林:深度解析与应用实践
引言
在机器学习的广阔天地中,集成学习方法因其卓越的预测能力和泛化性能而备受青睐。其中,随机森林(Random Forest)作为集成学习的一个重要分支,凭借其简单、高效且易于实现的特性,在分类和回归任务中展现了非凡的表现。本文将深入探讨随机森林的基本原理、核心构建模块、关键参数调优以及在实际应用中的策略与案例分析,旨在为读者提供一个全面而深入的理解。
1. 随机森林基础
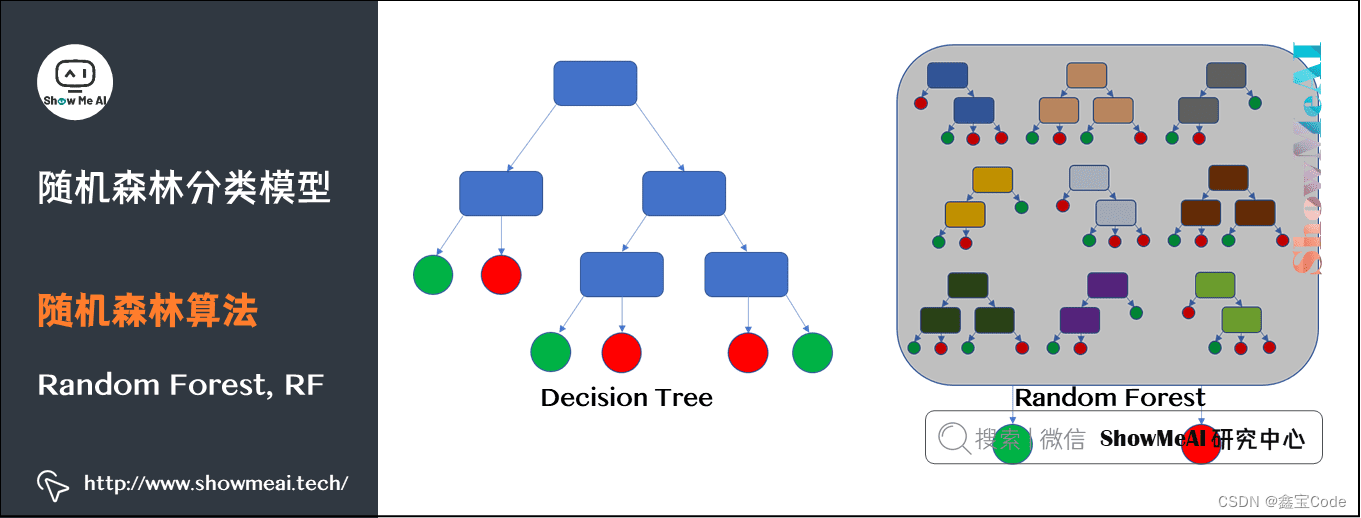
1.1 什么是随机森林?
随机森林是一种基于决策树的集成学习方法,通过构建多个决策树并综合它们的预测结果来提高预测准确性和模型的稳定性。每个决策树都是在训练数据的一个随机子集(bootstrap sample)上,以及特征的一个随机子集上构建的,这种方法减少了模型间的相关性,从而增强了整体模型的泛化能力。
1.2 随机森林的核心思想
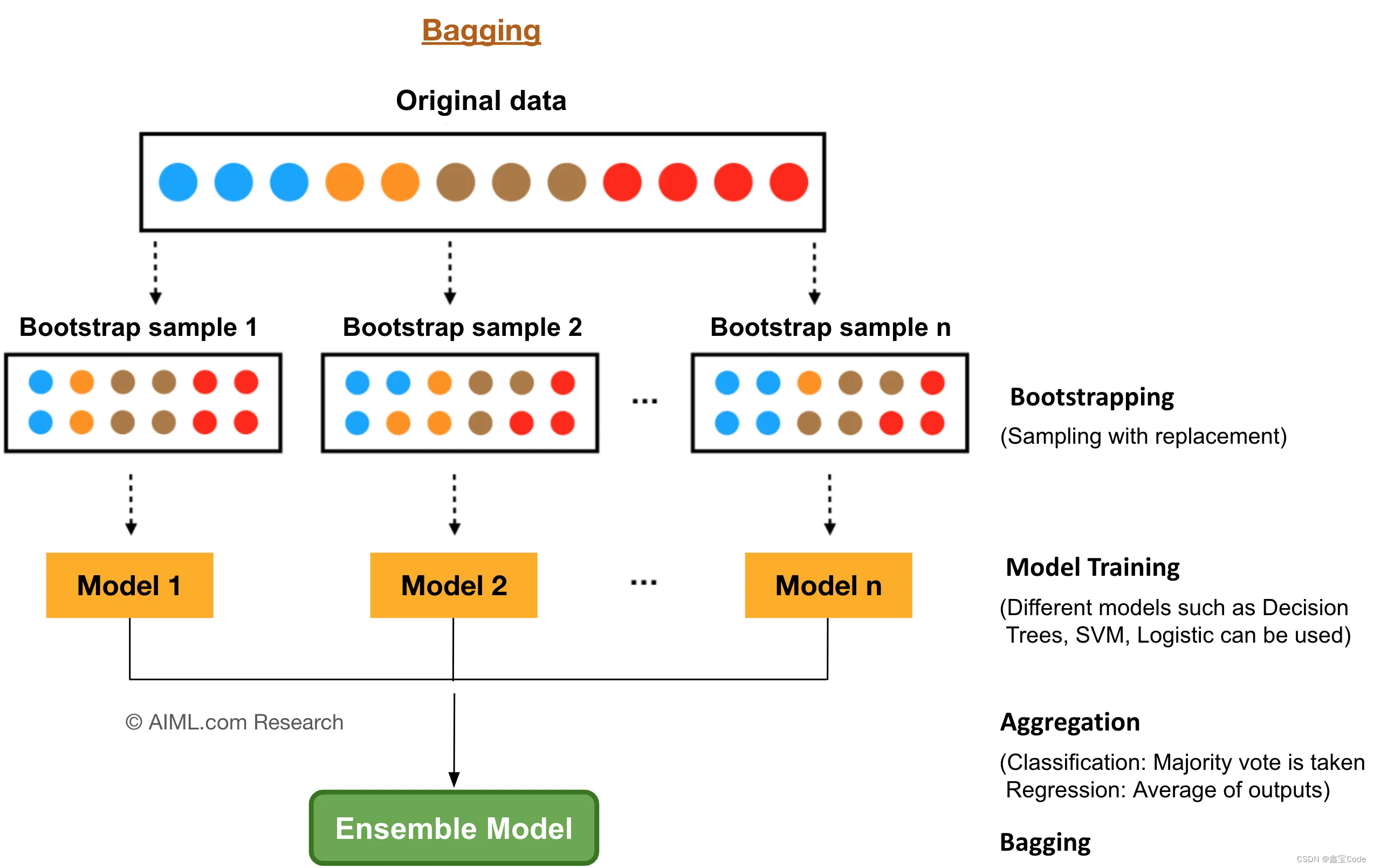
- Bootstrap Aggregating (Bagging):利用自助采样法从原始数据集中有放回地抽取样本,生成多个不同的训练集,每个训练集用于训练一个决策树。
- 特征随机选择:在决策树的每个节点分裂时,不是从所有特征中选择最佳分割特征,而是从一个随机特征子集中选择。
- 树的深度与复杂度控制:通常不剪枝或进行较轻的剪枝,以保持单个决策树的多样性。
2. 随机森林的构建过程
2.1 数据准备
首先,对原始数据进行预处理,包括缺失值处理、数据标准化或归一化等,确保数据质量。
2.2 构建决策树
- Bootstrap采样:从原始数据集中随机抽取N个样本(有放回),形成新的训练集。
- 特征随机选择:在每个节点分裂前,从所有特征中随机选取m个特征作为候选。
- 决策树构建:基于选定的特征,使用某种分裂准则(如信息增益、基尼不纯度)构建决策树,直到满足停止条件(如树的最大深度、节点最小样本数)。
2.3 集成预测
对于分类任务,采用多数投票机制确定最终类别;对于回归任务,则采用平均预测值。
3. 关键参数与调优
3.1 树的数量(n_estimators)
增加树的数量通常能提升模型的稳定性和性能,但过大会导致过拟合风险及计算成本增加。一般通过交叉验证来寻找最优值。
3.2 特征随机选择的数量(max_features)
影响模型的偏差-方差平衡。较小的值会增加模型的多样性,但可能因忽视重要特征而降低性能。常见的设置有“sqrt”(特征总数的平方根)或“log2”。
3.3 树的最大深度(max_depth)与节点最小样本数(min_samples_split)
限制树的复杂度,避免过拟合。适当调整这些参数可以优化模型的泛化能力。
下面是一个使用Python的scikit-learn库实现随机森林分类器的简单示例。这个例子将指导你如何加载数据集、预处理数据、构建随机森林模型、训练模型以及进行预测。
# 导入所需的库
from sklearn.datasets import load_iris # 用于加载Iris数据集
from sklearn.model_selection import train_test_split # 用于数据集的切分
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import accuracy_score # 评估模型准确率# 加载数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 目标变量# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 初始化随机森林分类器
# 这里可以设置随机森林的一些参数,例如n_estimators(树的数量)、max_depth等
rf_classifier = RandomForestClassifier(n_estimators=100, max_depth=4, random_state=42)# 使用训练集训练模型
rf_classifier.fit(X_train, y_train)# 在测试集上进行预测
predictions = rf_classifier.predict(X_test)# 计算并打印模型的准确率
accuracy = accuracy_score(y_test, predictions)
print(f"随机森林模型的准确率: {accuracy:.2f}")
这段代码首先导入了必要的库和模块,然后使用load_iris函数加载了经典的Iris数据集,这是一个用于分类任务的常用数据集,包含了150个样本,每个样本有4个特征和一个目标变量(类别)。接着,数据被划分为训练集和测试集,比例为70%训练,30%测试。之后,初始化了一个随机森林分类器,并设置了树的数量为100,最大树深度为4,以及随机种子以确保结果的可复现性。模型在训练集上进行训练后,对测试集进行预测,并使用accuracy_score函数计算预测的准确率。
4. 实际应用案例
4.1 信用评分
在金融领域,随机森林被广泛应用于信用评级,通过分析客户的交易记录、收入状况、历史还款行为等多维度数据,预测客户的违约风险。
4.2 医疗诊断
随机森林能够处理高维数据,适用于医疗领域的疾病预测。比如,基于病人的生理指标、生活习惯等因素,预测患特定疾病的风险。
4.3 推荐系统
在推荐系统中,随机森林可以用于用户偏好的分类,通过分析用户的历史行为、商品属性等信息,为用户推荐最可能感兴趣的商品或内容。
5. 总结
随机森林以其强大的预测能力、良好的鲁棒性和易于实现的特点,在众多领域展现了其价值。理解其核心原理、掌握关键参数调优技巧,并结合具体应用场景灵活运用,是发挥其最大效能的关键。随着数据科学的不断进步,随机森林及其变种仍在持续发展,为解决更复杂的问题提供可能性。
本文通过对随机森林的基本概念、构建过程、参数调优以及实际应用的深入解析,希望能为读者提供一个全面的认识框架。在实践中,不断探索与创新,将理论知识转化为解决实际问题的能力,是每个算法开发者追求的目标。

