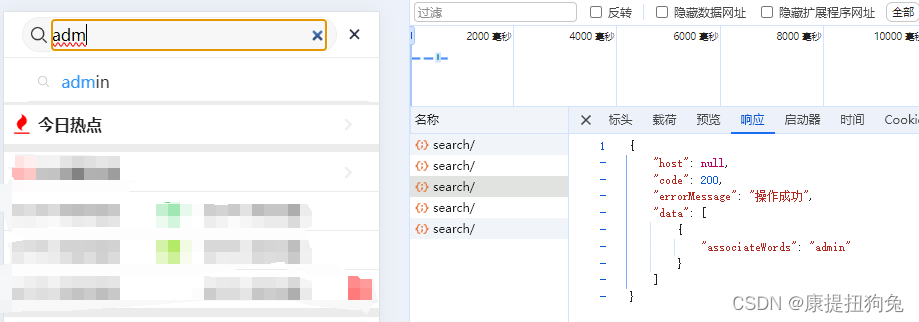
搜索自动补全-elasticsearch实现
1. elasticsearch准备
1.1 拼音分词器
github地址:https://github.com/infinilabs/analysis-pinyin/releases?page=6
必须与elasticsearch的版本相同
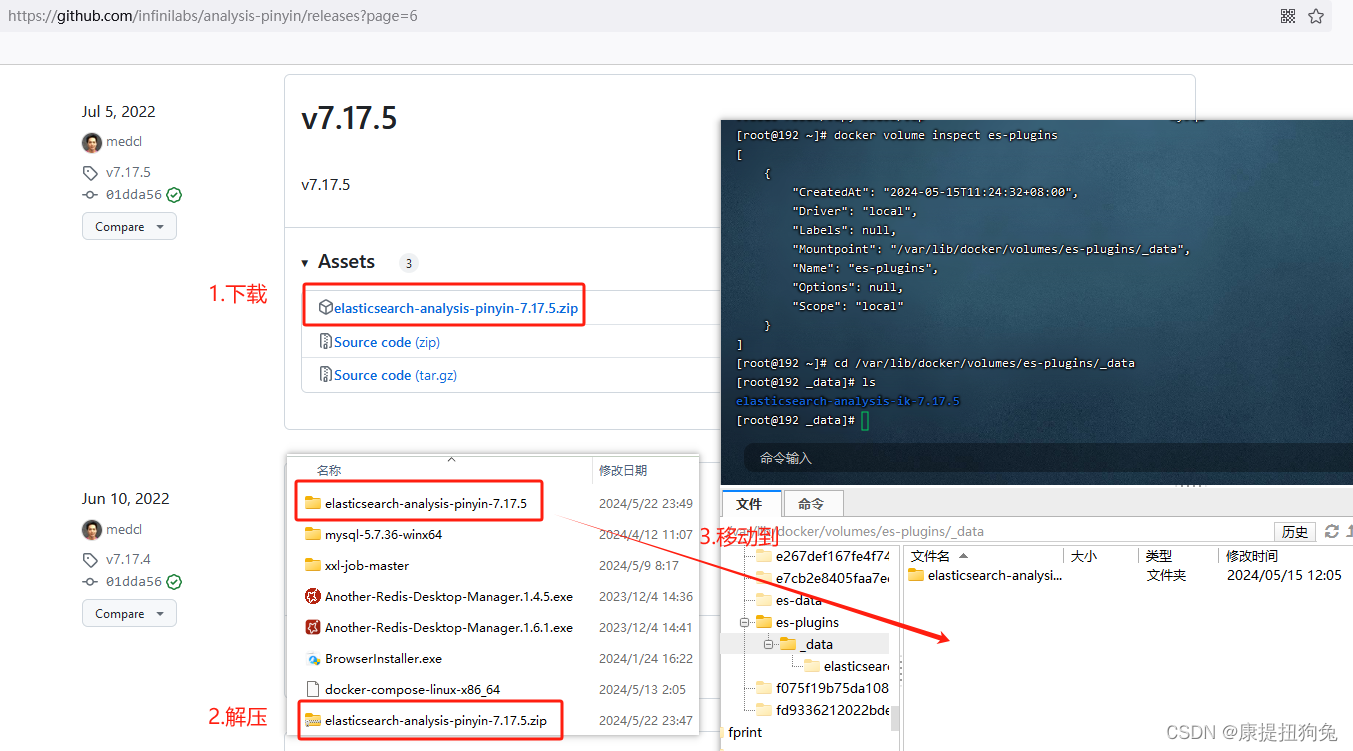 第四步,重启es
第四步,重启es
docker restart es
1.2 定义索引库
PUT /app_info_article
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings":{"properties":{"id":{"type":"long"},"publishTime":{"type":"date"},"layout":{"type":"integer"},"images":{"type":"keyword","index": false},"staticUrl":{"type":"keyword","index": false},"authorId": {"type": "long"},"authorName": {"type": "text"},"title":{"type":"text","analyzer":"text_anlyzer","search_analyzer": "ik_max_word", "copy_to": "all"},"content":{"type":"text","analyzer":"text_anlyzer","search_analyzer": "ik_max_word", "copy_to": "all"},"all":{"type": "text","analyzer": "ik_max_word"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
1.3 给索引库添加文档
详情参考我的另一篇博客: xxljob分片广播+多线程实现高效定时同步elasticsearch索引库
app_info_article对应的pojo类
@Data
public class SearchArticleVo {// 文章idprivate Long id;// 文章标题private String title;// 文章发布时间private Date publishTime;// 文章布局private Integer layout;// 封面private String images;// 作者idprivate Long authorId;// 作者名词private String authorName;//静态urlprivate String staticUrl;//文章内容private String content;//状态private int enable;//单词自动补全private List<String> suggestion;public void initSuggestion(){suggestion = new ArrayList<String>();suggestion.add(this.title);suggestion.add(this.authorName);}
}
核心代码
@XxlJob("syncIndex")public void syncIndex() {//1、获取任务传入的参数 {"minSize":100,"size":10}String jobParam = XxlJobHelper.getJobParam();Map<String,Integer> jobData = JSON.parseObject(jobParam,Map.class);int minSize = jobData.get("minSize"); //分片处理的最小总数据条数int size = jobData.get("size"); //分页查询的每页条数 小分页//2、查询需要处理的总数据量 total=IArticleClient.searchTotal()Long total = articleClient.searchTotal();//3、判断当前分片是否属于第1片,不属于,则需要判断总数量是否大于指定的数据量[minSize],大于,则执行任务处理,小于或等于,则直接结束任务int cn = XxlJobHelper.getShardIndex(); //当前节点的下标if(total<=minSize && cn!=0){//结束return;}//4、执行任务 [index-范围] 大的分片分页处理//4.1:节点个数int n = XxlJobHelper.getShardTotal();//4.2:当前节点处理的数据量int count = (int) (total % n==0? total/n : (total/n)+1);//4.3:确定当前节点处理的数据范围//从下标为index的数据开始处理 limit #{index},#{count}int indexStart = cn*count;int indexEnd = cn*count+count-1; //最大的范围的最后一个数据的下标//5.小的分页查询和批量处理int index =indexStart; //第1页的indexSystem.out.println("分片个数是【"+n+"】,当前分片下标【"+cn+"】,处理的数据下标范围【"+indexStart+"-"+indexEnd+"】");do {//=============================================小分页================================//5.1:分页查询//5.2:将数据导入ESpush(index,size,indexEnd);//5.3:是否要查询下一页 index+sizeindex = index+size;}while (index<=indexEnd);}/*** 数据批量导入* @param index* @param size* @param indexEnd* @throws IOException*/public void push(int index,int size,int indexEnd) {pool.execute(()->{System.out.println("当前线程处理的分页数据是【index="+index+",size="+(index+size>indexEnd? indexEnd-index+1 : size)+"】");//1)查询数据库数据List<SearchArticleVo> searchArticleVos = articleClient.searchPage(index, index+size>indexEnd? indexEnd-index+1 : size); //size可能越界// 第1页 index=0// indexEnd=6// 第2页 index=5// indexEnd-index+=2//2)创建BulkRequest - 刷新策略BulkRequest bulkRequest = new BulkRequest()//刷新策略-立即刷新.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);for (SearchArticleVo searchArticleVo : searchArticleVos) {//A:创建XxxRequestsearchArticleVo.initSuggestion();IndexRequest indexRequest = new IndexRequest("app_info_article")//B:向XxxRequest封装DSL语句数据.id(searchArticleVo.getId().toString()).source(com.alibaba.fastjson.JSON.toJSONString(searchArticleVo), XContentType.JSON);//3)将XxxRequest添加到BulkRequestbulkRequest.add(indexRequest);}//4)使用RestHighLevelClient将BulkRequest添加到索引库if(searchArticleVos!=null && searchArticleVos.size()>0){try {restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}}});}
在xxl-job任务调度平台执行一次该任务,文档就被添加进去了
如图
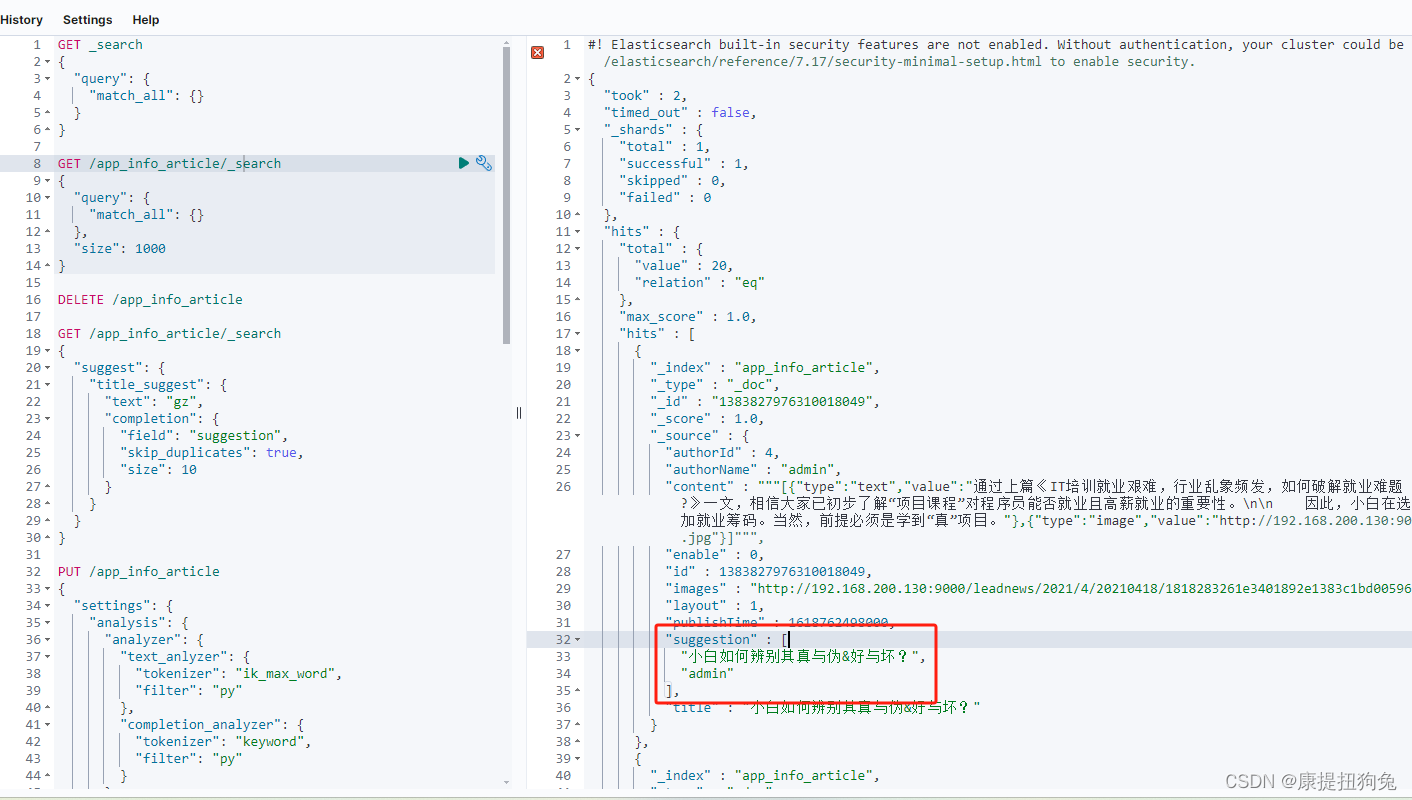
1.4 自动补全查询
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": { //设置这个自动查询操作的名称"text": "java", // 关键字"completion": {"field": "suggestion", // 补全查询的字段名"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
示例1.

示例2.
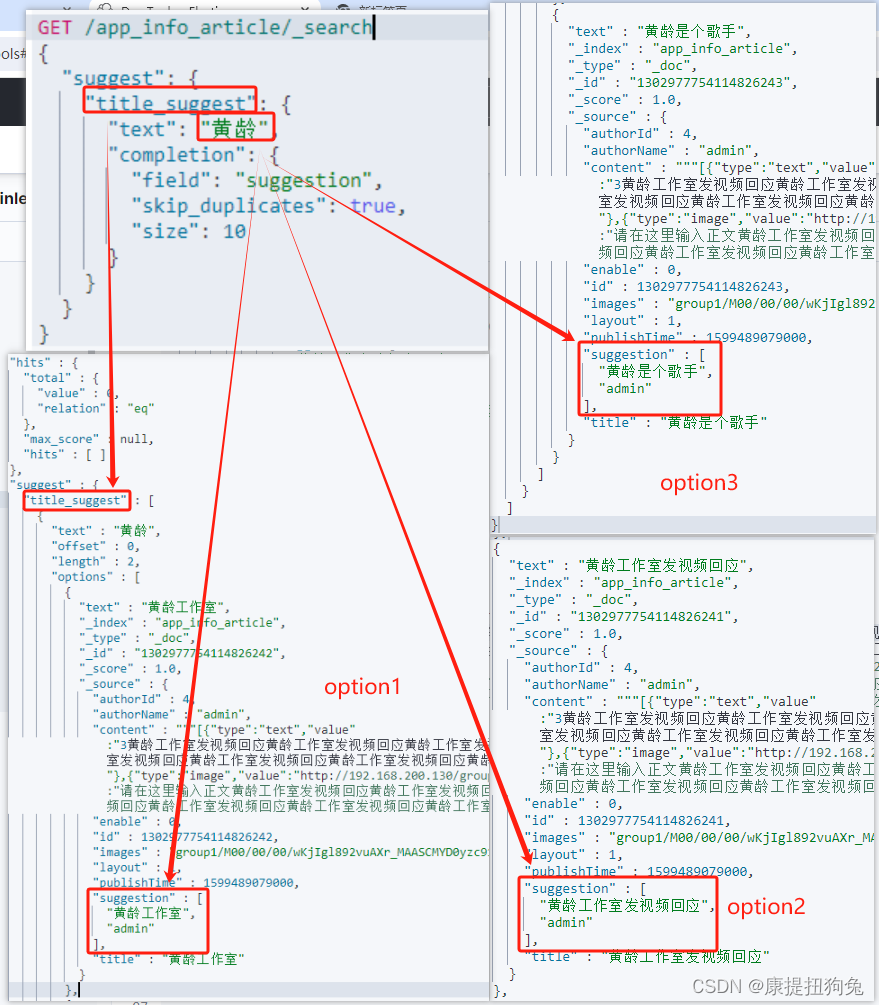
2. 代码流程
2.1 核心业务代码
AssociateController
@RestController
@RequestMapping(value = "/api/v1/associate")
public class AssociateController {@Autowiredprivate AssociateService associateService;/**** 单词自动补全*/@PostMapping(value = "/search")public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {return associateService.search(dto);}
}
核心search方法
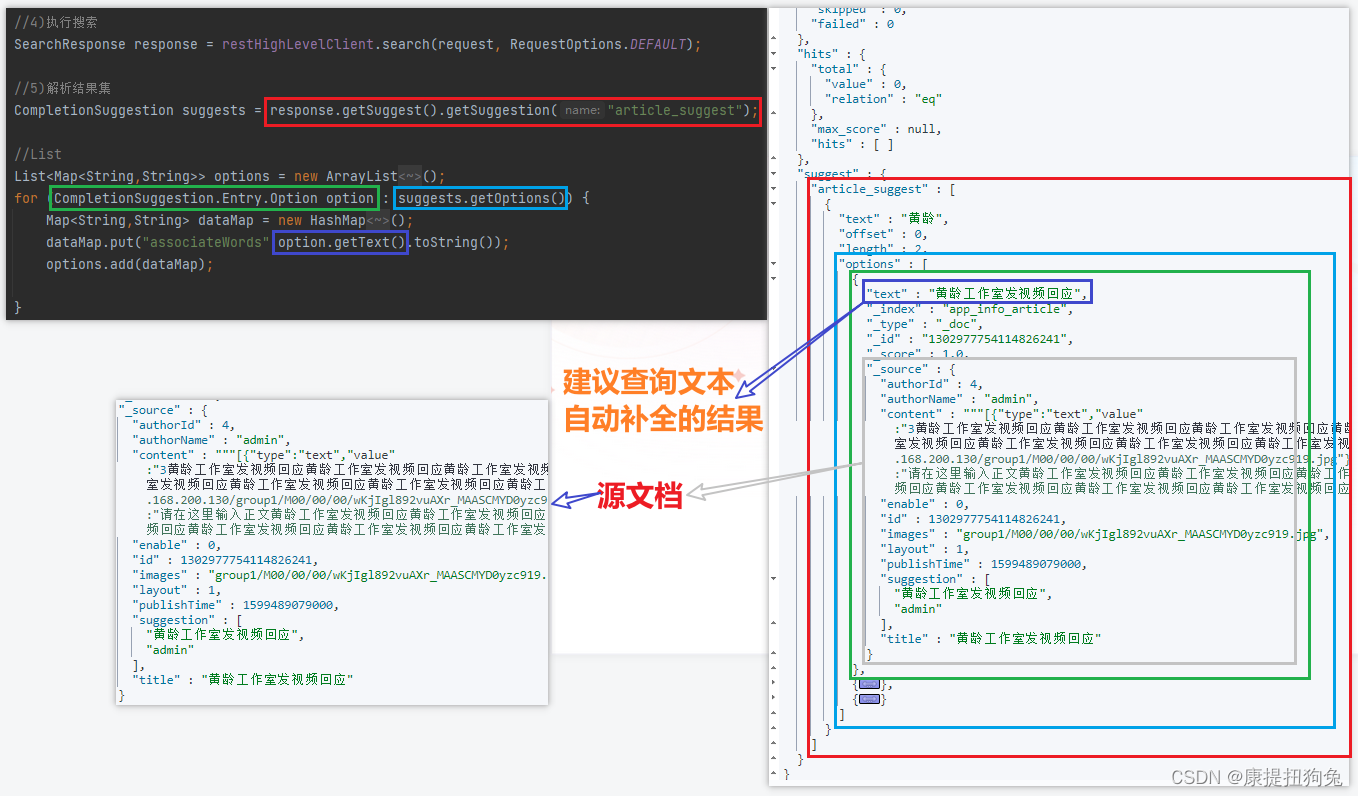
@Autowiredprivate RestHighLevelClient restHighLevelClient;/**** 单词自动补全* @param dto* @return*/@Overridepublic ResponseResult search(UserSearchDto dto) throws IOException {//1)新建一个SearchRequestSearchRequest request = new SearchRequest("app_info_article");//2)创建一个单词自动补全配置 Suggest,给它取个别名request.source().suggest(new SuggestBuilder().addSuggestion(//给它取个别名"article_suggest",SuggestBuilders//指定查询的字段.completionSuggestion("suggestion")//去重.skipDuplicates(true)//搜索的前缀.prefix(dto.getSearchWords()).size(10)));//4)执行搜索SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//5)解析结果集CompletionSuggestion suggests = response.getSuggest().getSuggestion("article_suggest");//ListList<Map<String,String>> options = new ArrayList<Map<String,String>>();for (CompletionSuggestion.Entry.Option option : suggests.getOptions()) {Map<String,String> dataMap = new HashMap<String,String>();dataMap.put("associateWords",option.getText().toString());options.add(dataMap);}return ResponseResult.okResult(options);}
结果集解析

2.2 测试
请求url:http://127.0.0.1:8801/app/search/api/v1/associate/search/
其中/app/search为nginx和gateway处理过
-
测试1
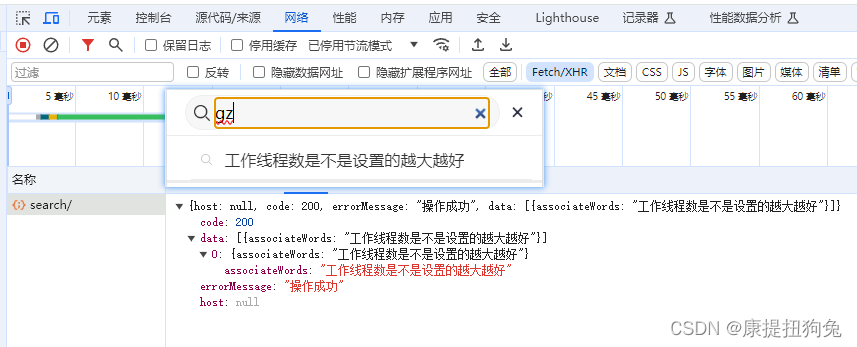
-
测试2
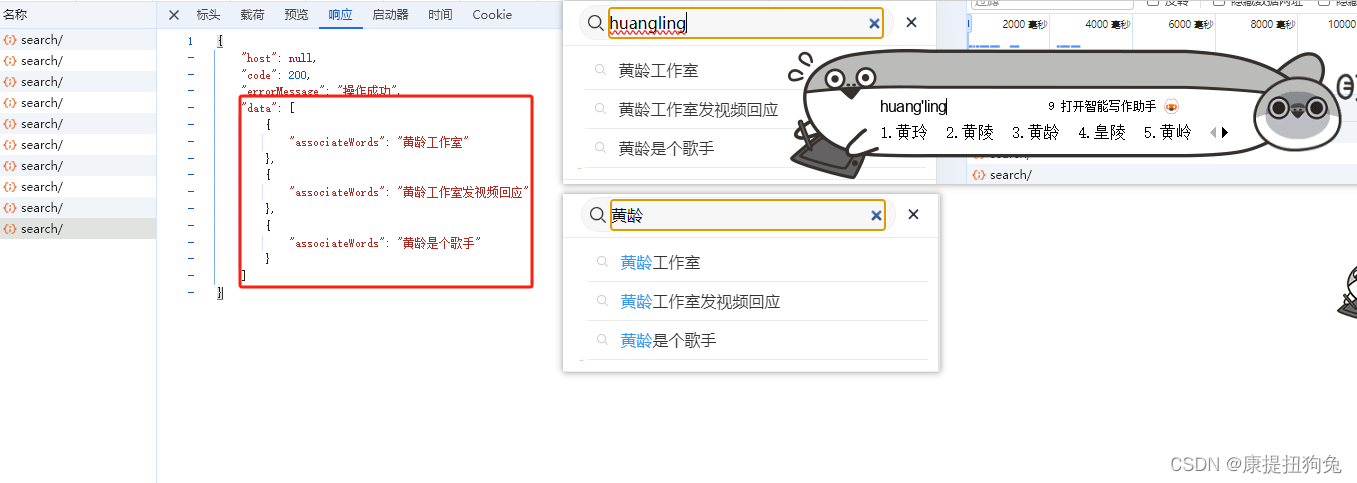
ps:联想词中的蓝色高亮是前端处理的。 -
测试3