数据结构的希尔排序(c语言版)
一.希尔排序的概念
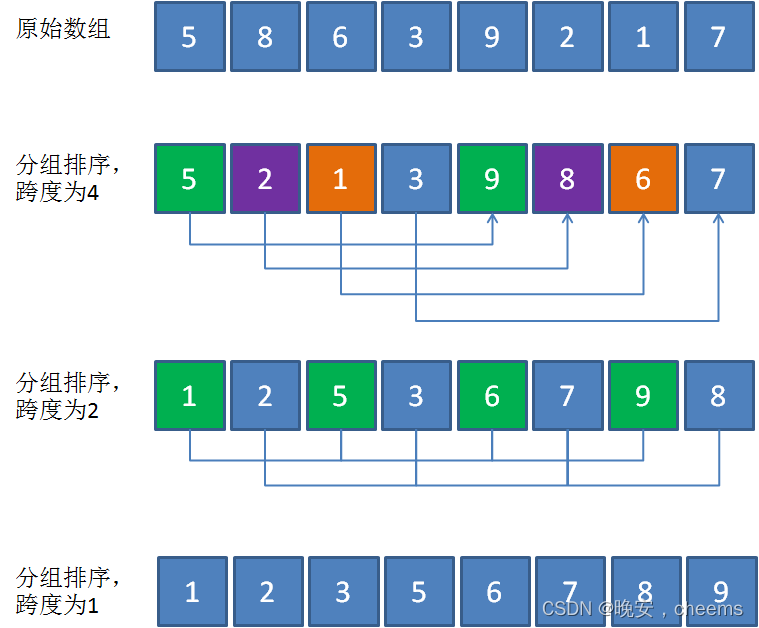
1.希尔排序的基本思想
希尔排序是一种基于插入排序算法的优化排序方法。它的基本思想如下:
-
选择一个增量序列 t1,t2,......,tk,其中 ti > tj, 当 i < j,并且 tk = 1。
-
按增量序列个数k,对数组进行k趟排序:
- 第一趟,按 t1 的增量对数组进行插入排序;
- 第二趟,按 t2 的增量对数组进行插入排序;
- ... ...
- 第k趟,按 tk 的增量(此时 tk = 1),也就是对整个数组进行插入排序。
2.希尔排序的优点
-
时间复杂度较低。希尔排序的时间复杂度一般在 O(n^1.25) 和 O(n^1.5) 之间,优于简单的插入排序。
-
在部分有序的数组中效率很高。希尔排序通过分组插入排序来利用数据的局部有序性,可以有效地加快排序速度。
-
空间复杂度低,只需要常量级的额外空间。
-
代码实现相对简单,易于理解和编码。
3.希尔排序的缺点
-
增量序列的选择对排序效率有很大影响。不同的增量序列会导致很大的性能差异。找到最优的增量序列是一个难题。
-
在数据量很大时,性能可能不如其他算法,如快速排序、堆排序等。
-
不稳定。希尔排序是不稳定的排序算法,即相等的元素可能会改变相对次序。
-
理论分析复杂。希尔排序的时间复杂度分析比较困难,没有得到一个统一的结论。
4.希尔排序与快速排序在使用情况时的差异
-
数据量中等且部分有序:
- 希尔排序通过分组排序利用了数据的局部有序性,在部分有序的数组上表现很好。
- 而快速排序在部分有序数组上可能会退化为 O(n^2) 的时间复杂度。
-
内存受限的环境:
- 希尔排序只需要常量级的额外空间,而快速排序需要递归调用栈,在内存受限的环境下可能会有优势。
-
数据分布不均匀:
- 快速排序的性能很容易受到数据分布的影响,而希尔排序相对更加好。
-
预先知道数据大致分布情况:
- 如果对数据的分布有一定了解,可以选择合适的增量序列来优化希尔排序的性能。
-
对稳定性要求不高:
- 快速排序是不稳定的,而希尔排序也是不稳定的。如果稳定性不是关键,希尔排序可能是更好的选择。
二.希尔排序的功能
1.分组插入排序
- 希尔排序的核心思想是通过分组插入排序来优化基本的插入排序算法。
- 它首先选择一个增量序列,如
[n/2, n/4, n/8, ...],将原始数组划分为多个子数组。 - 每个子数组的元素索引差为增量值。例如,当增量为 4 时,子数组为
arr[0]、arr[4]、arr[8]...。 - 对这些子数组分别进行插入排序。
- 随着增量序列逐步减小,子数组中的元素越来越集中,最终整个数组被完全排序。
2.利用局部有序性
- 在初始阶段,当增量较大时,子数组中的元素较为分散。
- 随着增量的不断减小,子数组中的元素逐渐趋于有序。
- 这种分组插入排序可以有效利用数据的局部有序性,从而减少插入排序的比较和移动操作次数。
3.时间复杂度优化
- 基本插入排序的时间复杂度为 O(n^2)。
- 而希尔排序通过分组插入排序和利用局部有序性,可以将平均时间复杂度优化到 O(n^1.25) 到 O(n^1.5)。
4.空间复杂度低
- 希尔排序只需要常量级的额外空间来存储一些中间变量,如增量序列等。
- 因此它的空间复杂度很低,仅为 O(1)。
5.代码实现简单
- 与其他高效排序算法相比,如快速排序和归并排序,希尔排序的代码实现较为简单。
- 它只需要一个嵌套循环来完成分组和插入排序即可。
三.希尔排序的代码实现
1.排序的实现
-
定义一个名为
shell_sort的函数,它接受两个参数:arr: 一个整型数组,需要被排序n: 数组的长度
-
shell_sort函数的实现:- 使用一个
for循环来遍历不同的增量值gap。初始的gap为n/2。 - 对于每个
gap值,我们再次使用一个for循环来遍历数组。 - 对于每个元素
arr[i],我们将其暂存到临时变量temp中。 - 然后,我们使用另一个内层
for循环来执行分组插入排序。在这个循环中,我们将arr[j]的值移动到arr[j - gap]的位置,直到找到temp应该插入的位置。 - 最后,我们将
temp赋值给arr[j]。 - 重复上述过程,直到
gap变为 0。
- 使用一个
void shell_sort(int arr[], int n) {for (int gap = n / 2; gap > 0; gap /= 2) {for (int i = gap; i < n; i++) {int temp = arr[i];int j;for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {arr[j] = arr[j - gap];}arr[j] = temp;}}
}2.main函数
- 定义一个示例数组
arr。 - 计算数组长度
n。 - 打印出未排序的数组。
- 调用
shell_sort函数对数组进行排序。 - 打印出排序后的数组。
int main() {int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);printf("Unsorted array: ");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");shell_sort(arr, n);printf("Sorted array: ");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");return 0;
}3.程序的执行流程
- 首先,在
main函数中,我们定义了一个示例数组arr。 - 然后,我们计算数组的长度
n。 - 接下来,我们打印出未排序的数组。
- 调用
shell_sort函数对数组进行排序。 - 在
shell_sort函数内部,我们使用一个for循环来迭代不同的增量值gap。初始的gap为n/2。 - 对于每个
gap值,我们遍历数组,对于每个元素arr[i],我们将其暂存到临时变量temp中。 - 然后,我们使用另一个内层
for循环来执行分组插入排序。在这个循环中,我们将arr[j]的值移动到arr[j - gap]的位置,直到找到temp应该插入的位置。 - 最后,我们将
temp赋值给arr[j]。 - 重复上述过程,直到
gap变为 0。 - 排序完成后,我们在
main函数中打印出排序后的数组。
四.希尔排序的源代码
- 首先,我们定义一个
shell_sort函数,接受一个整型数组arr和数组长度n作为参数。 - 在函数内部,我们使用一个
for循环来迭代不同的增量值gap。初始的gap为n/2。 - 对于每个
gap值,我们遍历数组,对于每个元素arr[i],我们将其暂存到临时变量temp中。 - 然后,我们使用另一个内层
for循环来执行分组插入排序。在这个循环中,我们将arr[j]的值移动到arr[j - gap]的位置,直到找到temp应该插入的位置。 - 最后,我们将
temp赋值给arr[j]。 - 重复上述过程,直到
gap变为 0。
#include <stdio.h>void shell_sort(int arr[], int n) {for (int gap = n / 2; gap > 0; gap /= 2) {for (int i = gap; i < n; i++) {int temp = arr[i];int j;for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {arr[j] = arr[j - gap];}arr[j] = temp;}}
}int main() {int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);printf("Unsorted array: ");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");shell_sort(arr, n);printf("Sorted array: ");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");return 0;
}