【Python】 XGBoost模型的使用案例及原理解析
原谅把你带走的雨天
在渐渐模糊的窗前
每个人最后都要说再见
原谅被你带走的永远
微笑着容易过一天
也许是我已经 老了一点
那些日子你会不会舍不得
思念就像关不紧的门
空气里有幸福的灰尘
否则为何闭上眼睛的时候
又全都想起了
谁都别说
让我一个人躲一躲
你的承诺
我竟然没怀疑过
反反覆覆
要不是当初深深深爱过
我试着恨你
却想起你的笑容
🎵 陈楚生/单依纯《原谅》
XGBoost(Extreme Gradient Boosting)是一种常用的梯度提升树(GBDT)算法的高效实现,广泛应用于各类数据科学竞赛和实际项目中。它的优势在于高效、灵活且具有很强的性能。下面,我们通过一个实际案例来说明如何使用XGBoost模型,并解释其原理。
案例背景
假设我们有一个客户流失预测的数据集,其中包含客户的特征数据及其是否流失的标注(流失为1,未流失为0)。我们需要构建一个XGBoost模型来预测客户是否会流失。
数据准备
首先,我们加载并准备数据。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, accuracy_score
import xgboost as xgb# 加载数据
df = pd.read_csv('customer_churn.csv')# 特征工程和数据预处理
X = df.drop('churn', axis=1)
y = df['churn']# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
模型训练
使用XGBoost进行模型训练。python
复制代码
# 转换数据格式为DMatrix,这是XGBoost高效的数据格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)# 设置XGBoost参数
params = {'booster': 'gbtree','objective': 'binary:logistic','eval_metric': 'logloss','eta': 0.1,'max_depth': 6,'scale_pos_weight': 80, # 处理不平衡数据,正负样本比例为1:80'subsample': 0.8,'colsample_bytree': 0.8,'seed': 42
}# 训练模型
num_round = 100
bst = xgb.train(params, dtrain, num_round)# 模型预测
y_pred_prob = bst.predict(dtest)
y_pred = (y_pred_prob > 0.5).astype(int)# 评估模型
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(classification_report(y_test, y_pred))
XGBoost原理解析
XGBoost是一种基于梯度提升(Gradient Boosting)算法的集成学习方法。梯度提升算法通过构建多个弱学习器(通常是决策树)来提升模型的预测性能。以下是XGBoost的关键原理:
-
加法模型和迭代训练:梯度提升是通过逐步迭代训练多个弱学习器(树模型),每个新的树模型学习前一轮残差(预测误差),即试图纠正前一轮模型的错误。
-
目标函数:XGBoost的目标函数由两部分组成:损失函数和正则化项。损失函数衡量模型的预测误差,正则化项控制模型的复杂度,防止过拟合。
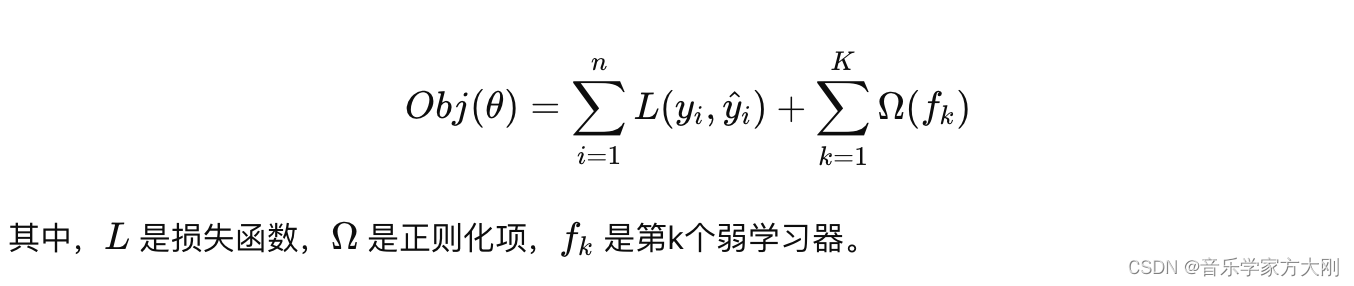
-
缺失值处理:XGBoost可以自动处理数据中的缺失值,通过在训练过程中找到最优的缺失值分裂方向。
-
并行计算:XGBoost在构建树的过程中,利用特征并行和数据并行技术,极大地提高了计算效率。
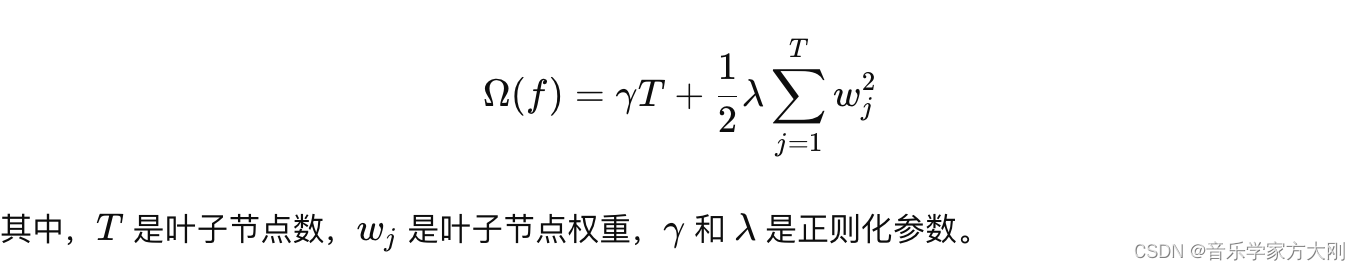
-
缺失值处理:XGBoost可以自动处理数据中的缺失值,通过在训练过程中找到最优的缺失值分裂方向。
-
并行计算:XGBoost在构建树的过程中,利用特征并行和数据并行技术,极大地提高了计算效率。
总结
XGBoost是一种强大的梯度提升算法,通过集成多个弱学习器来提高模型的预测性能。其高效的实现和诸多优化技术使其在实际应用中表现优异。通过调节参数如学习率、最大深度和正则化参数,XGBoost能够处理不同类型的任务,尤其是在处理不平衡数据集时具有很好的性能表现。在本案例中,我们展示了如何使用XGBoost进行客户流失预测,并解释了其背后的关键原理。