【数据库基础-mysql详解之索引的魅力(N叉树)】

索引的魅力目录
- 🌈索引的概念
- 🌈使用场景
- 🌈索引的使用
- 🌞🌞🌞查看MySQL中的默认索引
- 🌞🌞🌞创建索引
- 🌞🌞🌞删除索引
- 站在索引背后的那个男人~
- 🌞🌞🌞为什么不用哈希表
- 🌞🌞🌞为什么不用二叉搜索树
- 🌈B+ 树
- 🌈B树
- 🌈B+ 树
- 🌞🌞🌞B+树的一些优点:
- 🌈数据库的经典面试题
🌈 个人主页: 努力学编程’
⛅ 个人推荐: 基于java提供的ArrayList实现的扑克牌游戏 | C贪吃蛇详解
⚡ 学好数据结构,刷题刻不容缓: 点击一起刷题
🌙 心灵鸡汤: 总有人要赢,为什么不能是我呢

hello,友友们今天给大家来讲一下,数据库中的一个非常重要的知识索引,这不仅可以提高我们查找数据的效率,也可以然我们对于数据库有更加深刻的认识。
🌈索引的概念
索引的概念其实非常简单,这里可以类比书的目录进行对比,索引对于数据库来说其实就是一个目录,通过索引我们可以对数据进行快速的查找大大提高了我们操作数据库的成本。
🌈使用场景
通常我们使用索引,是基于数据量非常大的时候,且对于数据的修改操作执行比较少的时候,如果你的数据库是以下几种情况你就得认真思考一下啦:
- 数据库的数据量非常少,因为创建索引也要一定的的内存消耗,如果数据量少那就没必要创建索引了。
- 数据库的数据需要大量的修改操作,此时创建索引也是不划算的,大量的修改会提高你的维护成本,就好比你写了一本书,完成初稿后,你还要对内容进行大量的修改,如果你创建了目录,那目录岂不是也要大量的修改!!!
- 当然创建索引的时候,会占用一定的磁盘空间,要谨慎使用!!!
🌈索引的使用
在MySQL中有些约束条件会主动提供给我们一些索引,例如:unique,primary key ,foreign key 都会默认生成一个索引。
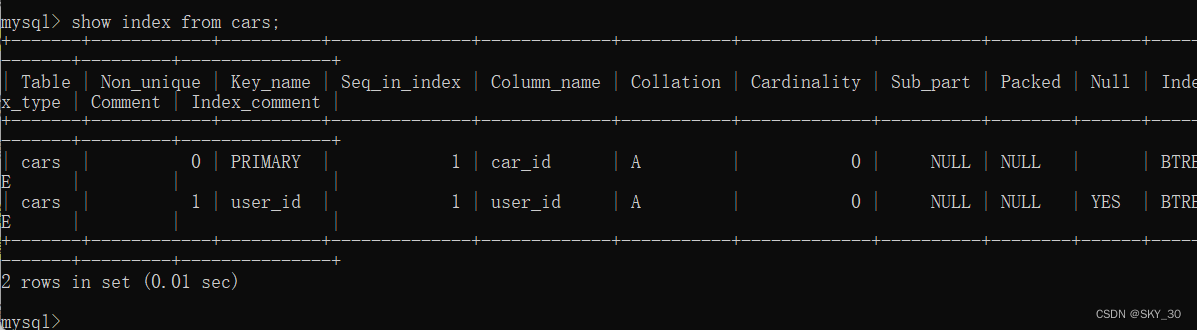
🌞🌞🌞查看MySQL中的默认索引
== show index from 表名;==
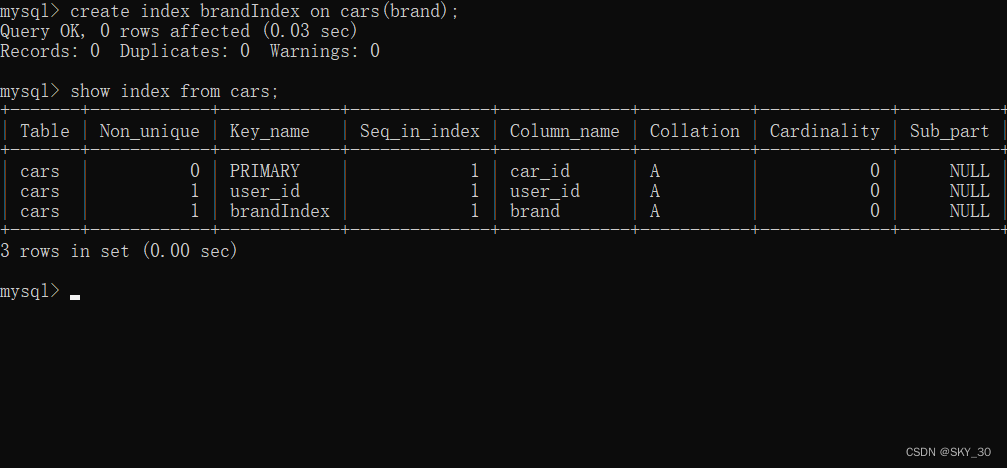
🌞🌞🌞创建索引
当然我们可以根据自己需要创建索引,这里要给大家提醒一下,其实创建索引也是一个很危险的操作如果是一个空表,当然没有什么风险,但是如果你的数据是几千几万那么当你创建索引的时候,就会触发大量的硬盘IO,可能会把硬盘吃满,机器直接崩溃~~
create index 索引名 on 表名(字段名);
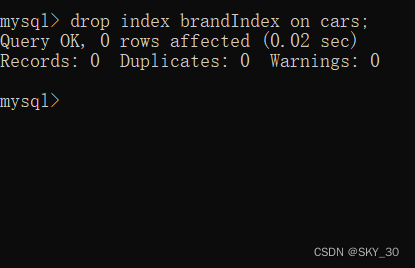
🌞🌞🌞删除索引
drop index 索引名 on 表名;
站在索引背后的那个男人~
所谓索引,其实就是对数据进行一定的整理,在我们查询数据的时候会大大提高效率,而这背后实际上用到的还是我们之前提到过的数据结构,那么那个数据结构可以对提升查找数据的效率呢,其实就两个,哈希表和搜索二叉树。
🌞🌞🌞为什么不用哈希表
在哈希表中我们只能判断是否相等的情况,对于范围的查询,以及类似于like的模糊查询,其实我们是做不到的~~
🌞🌞🌞为什么不用二叉搜索树
当我们处理的数据非常大的时候,创建一个二叉搜索树必然会使这棵树的高度非常高,树的高度一旦非常高,那么查找起来其实是非常低效的,所以这里也不选择二叉搜索树~~
🌈B+ 树
那么不用哈希表,也不用二叉搜索树,我们应该用什么数据结构去处理这个问题呢,其实这里专门为了数据库创建了一个数据结构-B树:
🌈B树
B树,又称N叉搜索树,相信这个名字,可以让你对于B树的理解,有一个比较清晰的认识,对比二叉搜索树,B树每个结点有N个度,而且每个节点也并非只有一个值,一般会有多个,通过这两个结构上的改变,就可以有效的降低树的高度,从而提升树的高度。
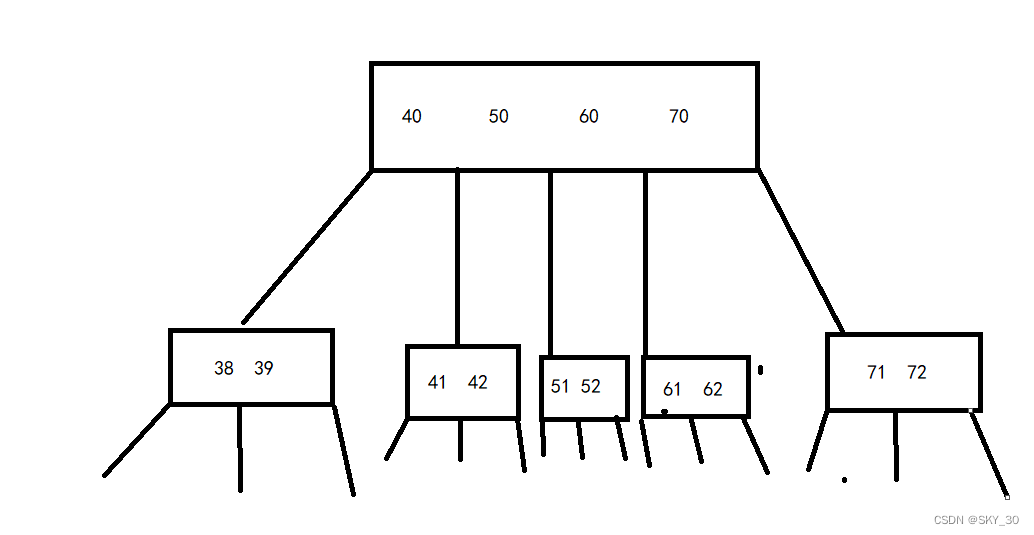
但是我们发现B树其实还是有很多需要改进的地方的,比如虽然我们降低了树的高度,但是我们提高了树的每个节点的值的数量,这就意味着如果我们要插入一个数据,可能就需要多个数据的比较,好像并没有对二叉搜索树做出很大的优化啊,其实还是优化了不少的,虽然增加了每个节点的值的数量,但是,针对每一个节点,只会发生一次硬盘IO,所以虽然每个节点的值变多了,但是对比与二叉搜索树,大大减少了硬盘IO的次数,这才是我们优化的最重要的方面!!!
🌈B+ 树
针对B树我们做了一定的优化,又有了另一种数据结构-B+树,他的主要特点对比B树就是每个节点的度是N个,并且每个节点的值都会在子节点以最大值的形式出现,直到最后一行,会把整个数据库中的数据做一个整理,以链表的形式将他们连接起来,便于查找!!!
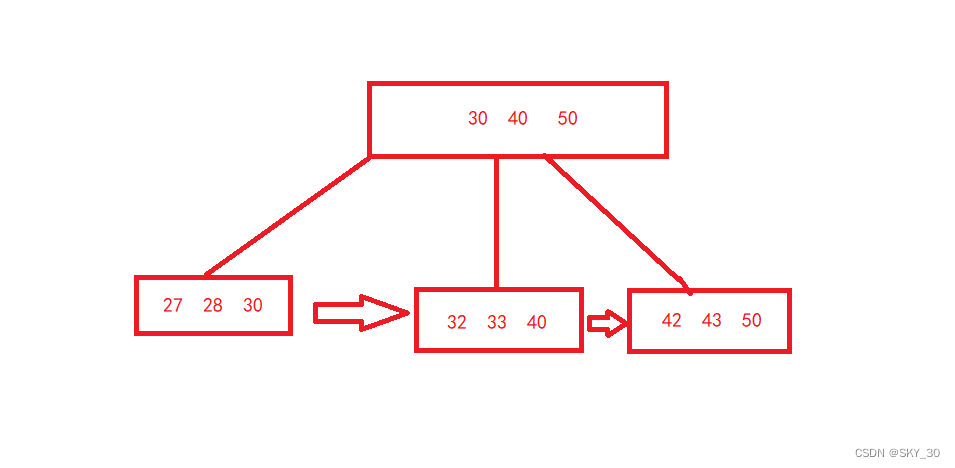
🌞🌞🌞B+树的一些优点:
- N叉搜索树,高度较低,硬盘IO的次数较少。
- 叶子结点是全集,并且用链表连接,便于查询。
- B+树每一次的查询,都是要落在叶子结点上的,所以每次的IO次数以及比较次数其实是差不多的,所以查询的开销是比较稳定的!!!
- 由于B+树的叶子结点是全集,所以非叶子结点不必存储数据行,只需要存储索引列的key即可,使得非子节点所消耗的空间变少,进一步较少硬盘IO的次数
🌈数据库的经典面试题
- 索引是啥,解决了什么问题
-
答:索引相当于书的目录,用来提升查询的效率
- 索引付出了什么代价
-
答:付出了更多的空间,有可能会影响增删找的效率,比如你的数据库需要大量修改的时候。但是我们认为创建索引总体来说是利大于弊的,我们支持创建索引。
- 如何使用sql命令,是否有注意事项
-
答:show index from 表名 (查看索引)-主键,外键,unique会自定生成目录~~,create index 索引名on 表名(指定列),删除索引 drop index 索引名 on 表名;,而且在我们创建了索引之后,在查询的时候,必须要和索引的列相匹配,否则不会提高查找数据的效率,类似于字典不同的目录,就有不同的查找方式!!!
-
- 索引背后的数据结构->B+树,及其优点和特点
-
特点即优点: N叉搜索树,每个节点有N个值,划分为N个区间,高度比较低,降低了硬盘IO的次数,范围查询非常方便,所有的节点都落到了叶子结点上,开销非常稳定,容易预估成本。叶子结点存储行的数据,非叶子节点只存储索引的key的值,非叶子节点占据空间小,可以加载到内存中,减少IO的次数,每个父节点都会下沉到子节点中,作为最大值的角色出现,叶子节点这一层构成了数据的全集,使用类似于链表的数据结构将叶子节点串起来~~