智能语义识别电影机器人的rasa实现
文章目录
- 0.前言
- 1.项目整体框架
- 2.rasa训练数据结构
- 4.rasa启动命令及用到的API
0.前言
最近做了一个智能电影机器人的项目,我主要负责用户语义意图识别,用的框架是rasa,对应的版本为 3.6.15,对应的安装命令为:
pip3 install rasa==3.6.15 # 安装这个时候可能需要科学上网
pip3 install 'rasa[jieba]'
pip3 install 'rasa[transformers]'
pip3 install 'rasa[FallbackClassifier]'
pip3 install 'rasa[nlu]'
1.项目整体框架
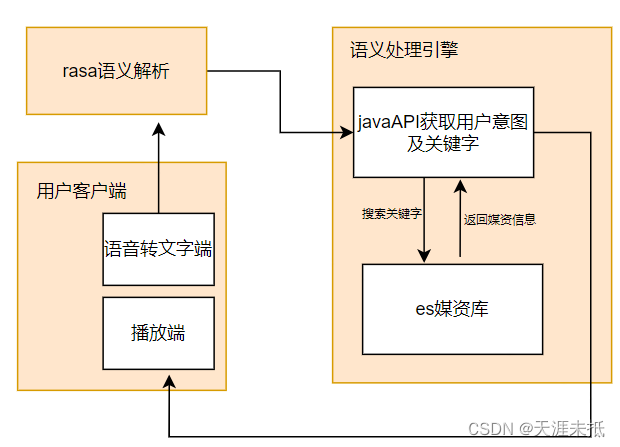
用户客户端通过语音说出他想看的电影,然后通过语音转文字模块,将文字传送给rasa,rasa识别出用户的意图和相应的关键字,通过rasa的api给到java端,(java这里其实充当是rasa里面的action这个操作,其实可以用python实现。)java端通过意图和关键字在es里面查询相应的索引,这里用es做媒资库的原因,是es的模糊搜索能力比关系型数据库强,最后将搜索到的媒资供用户选择进行播放。
2.rasa训练数据结构
由两部分数据组成,意图训练数据和相应的关键词查找数据,这里没有采用相应的关键词穷举放入意图训练数据进行训练,这里的意图训练数据只是训练的语料模版,然后实际使用的时候用户说话里面的实体由另一份关键词查找数据进行填充,这里用的是rasa的RegexEntityExtractor组件。现在举例这些两份数据,如何发挥作用的。
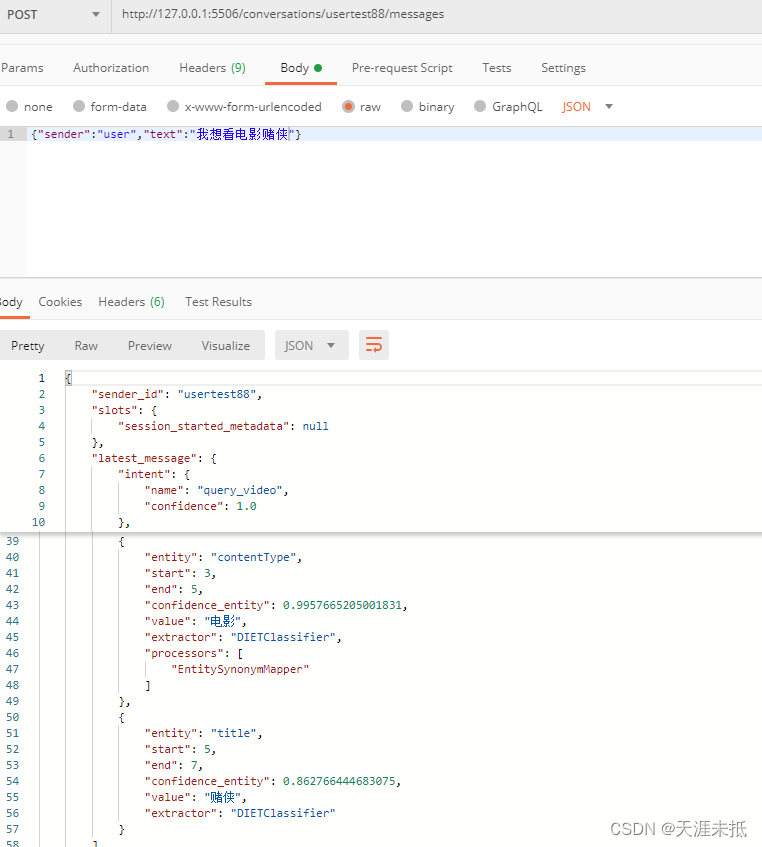
这是一份查询视频的意图训练数据,当用户说“我要看电影赌侠”的时候,这里rasa识别到的意图(intent)为query_video,这里的两个实体(entity)为contentType和title,分别识别为电影和赌侠
version: "3.1"
nlu:
- intent: query_video
examples: |- 我要看[电影](contentType)[赌侠](title)- 播放看[电影](contentType)[赌侠](title)- 我想看[电影](contentType)[赌侠](title)
由两部分数据组成,意图训练数据和相应的关键词查找数据,这里没有采用相应的关键词穷举放入意图训练数据进行训练,这里的意图训练数据只是训练的语料模版,然后实际使用的时候用户说话里面的实体由另一份关键词查找数据进行填充,这里用的是rasa的RegexEntityExtractor组件。现在举例这些两份数据,如何发挥作用的。
这是一份查询视频的意图训练数据,当用户说“我要看电影赌侠”的时候,这里rasa识别到的意图(intent)为query_video,这里的两个实体(entity)为contentType和title,分别识别为电影和赌侠
version: "3.1"
nlu:
- intent: query_video
examples: |- 我要看[电影](contentType)[赌侠](title)- 播放看[电影](contentType)[赌侠](title)- 我想看[电影](contentType)[赌侠](title)
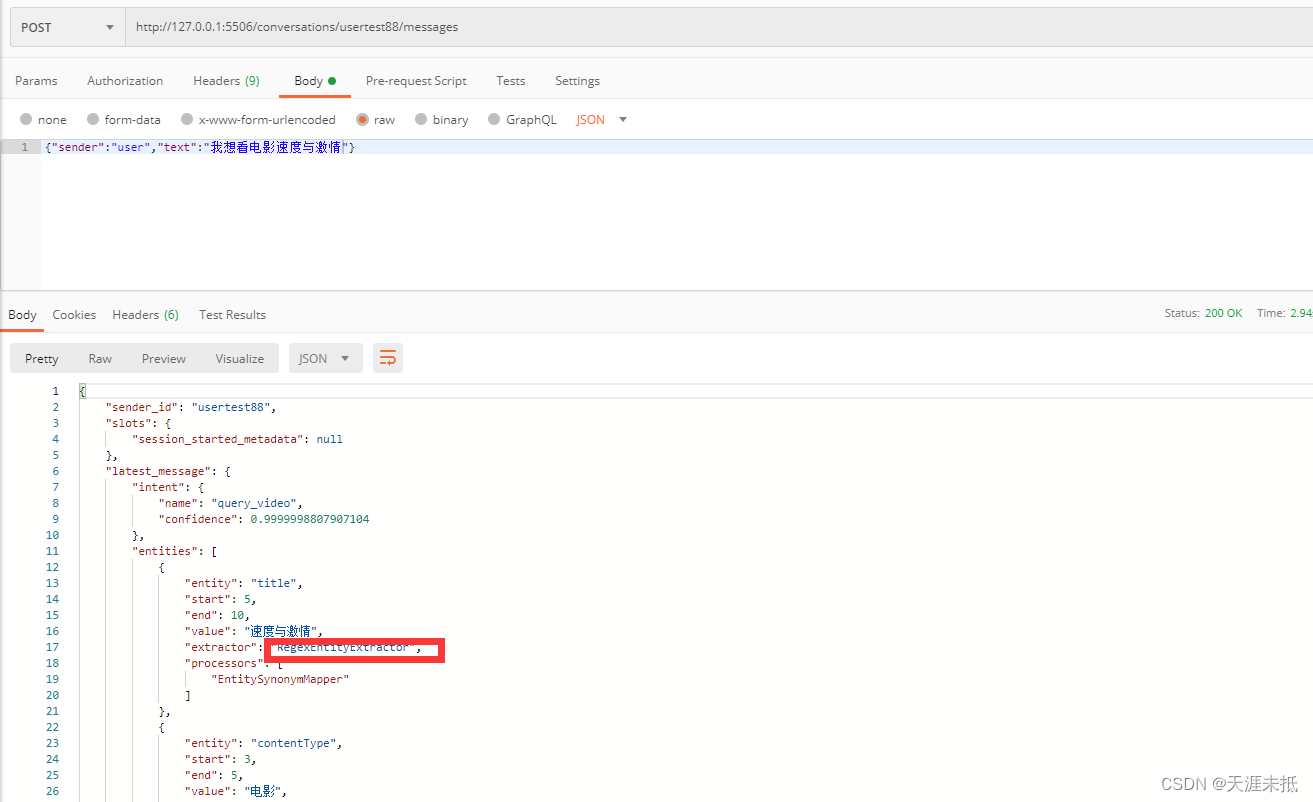
 如果用户说“我想看电影速度与激情”,这个数据可能不在我们的训练的意图数据中,但是rasa识别了意图为query_video,这里的两个实体(entity)为contentType为电影,title通过正则匹配为速度与激情,关键词数据的样式为
如果用户说“我想看电影速度与激情”,这个数据可能不在我们的训练的意图数据中,但是rasa识别了意图为query_video,这里的两个实体(entity)为contentType为电影,title通过正则匹配为速度与激情,关键词数据的样式为
version: "3.1"
nlu:
- lookup: title
examples: |- 速度与激情8- 石头娃- 中甲精华- 畲族彩带传承人- 最美奋斗者- 唤醒巨人
3.rasa训练配置如下
pipeline:
name: JiebaTokenizer
name: LanguageModelFeaturizer
model_name: "bert"
model_weights: "bert-base-chinese"
name: "RegexEntityExtractor"
use_word_boundaries: False
use_lookup_tables: True
use_regexes: True
name: "DIETClassifier"
epochs: 100
tensorboard_log_directory: ./log
learning_rate: 0.001
name: "ResponseSelector"
name: "EntitySynonymMapper"
name: FallbackClassifier
threshold: 0.9
ambiguity_threshold: 0.01policies:
name: MemoizationPolicy
max_history: 1
name: TEDPolicy
max_history: 1
epochs: 10
name: RulePolicy
max_history: 1
4.rasa启动命令及用到的API
rasa run --enable-api --cors "*" --port 5506
post http://127.0.0.1:5506/conversations/usertest88/messages
{"sender":"user","text":"我想看电影速度与激情"}
如需源码,请关注微信公众号:造轮子的坦克,回复w,获取个人微信,然后私发给您。