elasticsearch 和 RediSerch
elasticsearch 和 RediSerch
前情提要
学习文章来自Docker 安装 ElasticSearch - 知乎 (zhihu.com)
docker 安装
docker pull docker.io/elasticsearch:7.1.1

启动!
docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" b0e9f9f047e6
-d:后台启动
--name:容器名称
-p:端口映射
-e:设置环境变量
discovery.type=single-node:单机运行
b0e9f9f047e6:镜像id
如果启动不了,可以加大内存设置:-e ES_JAVA_OPTS="-Xms512m -Xmx512m"
检查如何启动成功,访问9200端口即可
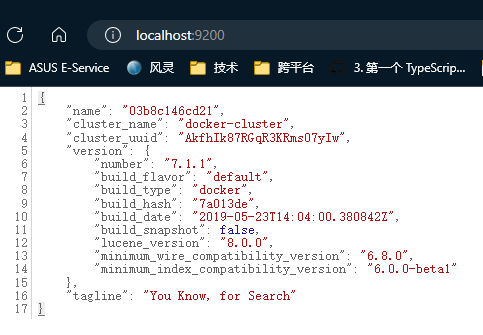
安装 ik 分词器
先查看号然后进入到里面
docker ps

docker exec -it es bash

进去之后输入
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.1/elasticsearch-analysis-ik-7.1.1.zip
安装完毕退出即可
测试访问端口9200下_analyze
localhost:9200/_analyze
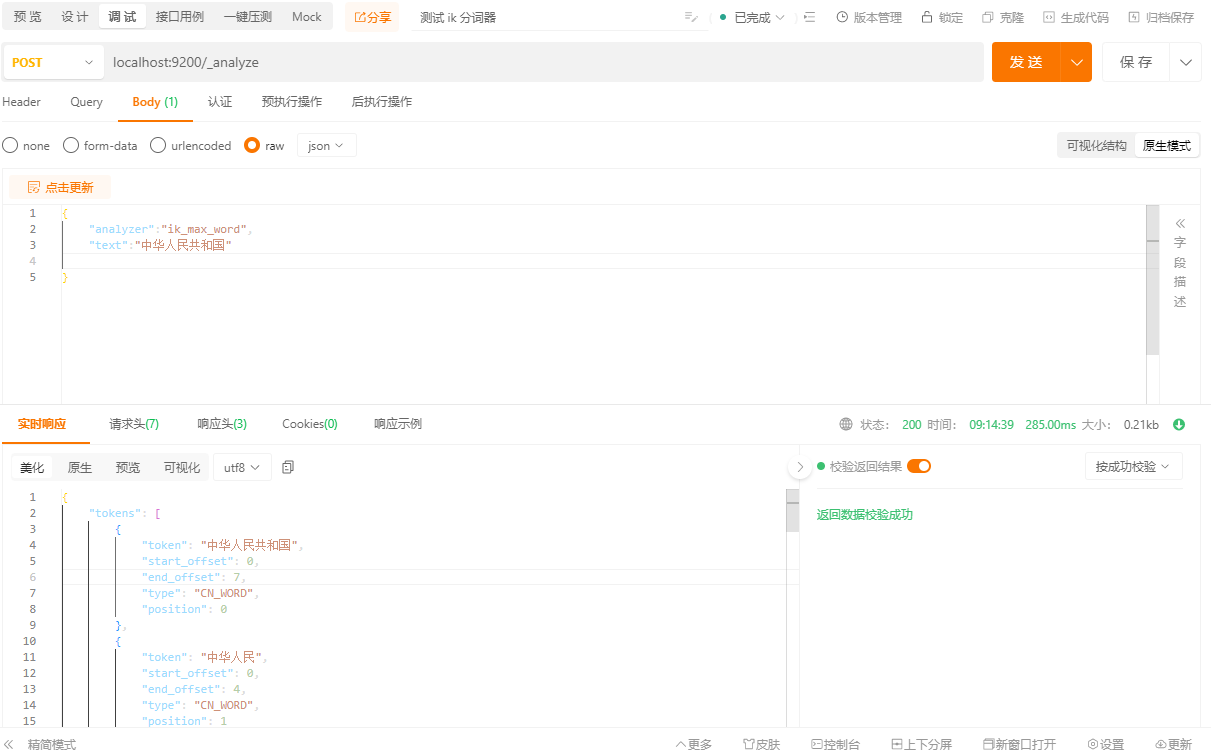
分词结果
ES可视化工具
docker pull mobz/elasticsearch-head:5
拉下来之后启动images
前提
需要在之前的es容器中设置跨域设置
docker exec -it es /bin/bash
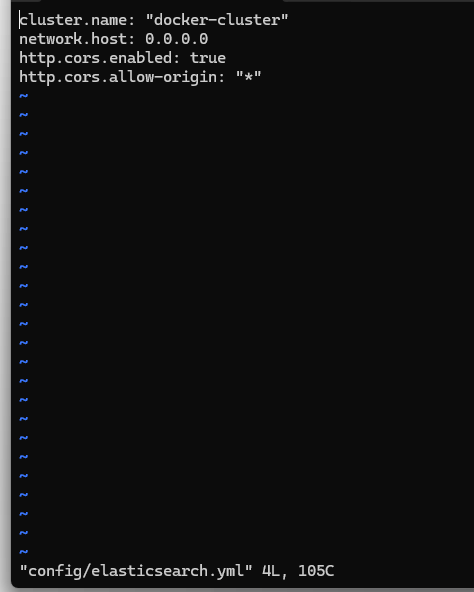
编辑文件
vi config/elasticsearch.yml
加入这两行信息
http.cors.enabled: true
http.cors.allow-origin: "*"
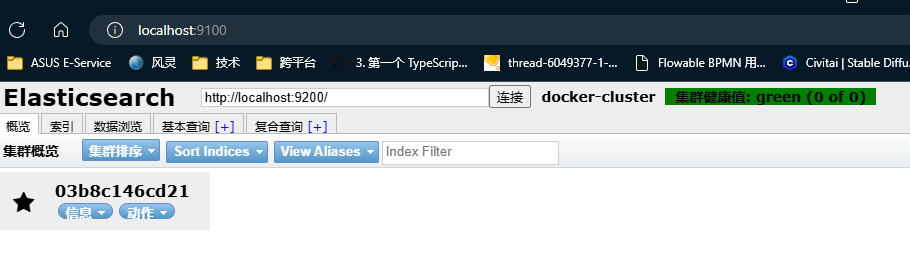
然后到界面localhost:9100进行连接
使用(初步整合SpringBoot3.XX rest客户端方式整合)
1. 依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.2.0</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.2.0</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.2.0</version></dependency><!--加入lombook--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
2. 配置文件
elasticsearch:uris: http://127.0.0.1:9200username:password:
3. config
package org.hj.elasticsearchstudy.elasticsearchstudy.config;import lombok.SneakyThrows;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.conn.ssl.NoopHostnameVerifier;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.apache.http.impl.nio.reactor.IOReactorConfig;
import org.apache.http.ssl.SSLContextBuilder;
import org.apache.http.ssl.TrustStrategy;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;import javax.net.ssl.SSLContext;
import java.util.ArrayList;
import java.util.List;@Configurationpublic class EsConfig {@Value("${elasticsearch.uris}")private String uris;@Value("${elasticsearch.username}")private String username;@Value("${elasticsearch.password}")private String password;@Bean(name = "restHighLevelClient")public RestHighLevelClient restHighLevelClient() {// 拆分地址List<HttpHost> hostLists = new ArrayList<>();String[] hostList = uris.split(",");for (String addr : hostList) {hostLists.add(HttpHost.create(addr));}// 转换成 HttpHost 数组HttpHost[] httpHost = hostLists.toArray(new HttpHost[] {});RestClientBuilder clientBuilder = RestClient.builder(httpHost);clientBuilder.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {@SneakyThrows@Overridepublic HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {if (!StringUtils.isEmpty(username) && !StringUtils.isEmpty(password)) {CredentialsProvider credentialsProvider = new BasicCredentialsProvider();UsernamePasswordCredentials credentials = new UsernamePasswordCredentials(username, password);credentialsProvider.setCredentials(AuthScope.ANY, credentials);httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);}IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(100).setConnectTimeout(10000).setSoTimeout(10000).build();httpClientBuilder.setDefaultIOReactorConfig(ioReactorConfig);SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() {@Overridepublic boolean isTrusted(java.security.cert.X509Certificate[] arg0, String arg1) {return true;}}).build();httpClientBuilder.setSSLContext(sslContext);httpClientBuilder.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE);return httpClientBuilder;}});return new RestHighLevelClient(clientBuilder);}}
测试查询
@Test
public void testMatchAll() throws IOException {//1.创建 SearchRequest搜索请求SearchRequest searchRequest = new SearchRequest();searchRequest.indices("book");//指定要查询的索引//2.创建 SearchSourceBuilder条件构造。builder模式这里就先不简写了SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();searchSourceBuilder.query(matchAllQueryBuilder.queryName("Java"));//3.将 SearchSourceBuilder 添加到 SearchRequest中searchRequest.source(searchSourceBuilder);//4.执行查询SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//5.解析查询结果System.out.println(searchResponse);System.out.println("花费的时长:" + searchResponse.getTook());SearchHits hits = searchResponse.getHits();System.out.println(hits.getTotalHits());System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
}

RediSearch
学习来源
[32 实战:RediSearch 高性能的全文搜索引擎 (lianglianglee.com)](https://learn.lianglianglee.com/专栏/Redis 核心原理与实战/32 实战:RediSearch 高性能的全文搜索引擎.md)
安装
docker run -p 6379:6379 redislabs/redisearch:latest
进入
安装完成之后使用 redis-cli 来检查 RediSearch 模块是否加载成功,使用 Docker 启动 redis-cli,命令如下:
docker exec -it myredis redis-cli
其中“myredis”为 Redis 服务器的名称,执行结果如下:
127.0.0.1:6379> module list
1) 1) "name"2) "ft"3) "ver"4) (integer) 10610
返回数组存在“ft”,表明 RediSearch 模块已经成功加载。
源码方式安装
如果不想使用 Docker,我们也可以使用源码的方式进行安装,安装命令如下:
git clone https://github.com/RedisLabsModules/RediSearch.git
cd RediSearch # 进入模块目录
make all
安装完成之后,可以使用如下命令启动 Redis 并加载 RediSearch 模块,命令如下:
src/redis-server redis.conf --loadmodule ../RediSearch/src/redisearch.so
使用
我们先使用 redis-cli 来对 RediSearch 进行相关的操作。
创建索引和字段
127.0.0.1:6379> ft.create myidx schema title text weight 5.0 desc text
OK
其中“myidx”为索引的ID,此索引包含了两个字段“title”和“desc”,“weight”为权重,默认值为 1.0。
将内容添加到索引
127.0.0.1:6379> ft.add myidx doc1 1.0 fields title "He urged her to study English" desc "good idea"
OK
其中“doc1”为文档 ID(docid),“1.0”为评分(score)。
根据关键查询
127.0.0.1:6379> ft.search myidx "english" limit 0 10
1) (integer) 1
2) "doc1"
3) 1) "title"2) "He urged her to study English"3) "desc"4) "good idea"
可以看出我们使用 title 字段中的关键字“english”查询出了一条满足查询条件的数据。
中文搜索
首先我们需要先给索引中,添加一条中文数据,执行命令如下:
127.0.0.1:6379> ft.add myidx doc2 1.0 language "chinese" fields title "Java 14 发布了!新功能速览" desc "Java 14 在 2020.3.17 日发布正式版了,但现在很多公司还在使用 Java 7 或 Java 8"
OK
注意:这里必须要设置语言编码为中文,也就是“language “chinese””,默认是英文编码,如果不设置则无法支持中文查询(无法查出结果)。
我们使用之前的查询方式,命令如下:
127.0.0.1:6379> ft.search myidx "正式版"
1) (integer) 0
我们发现并没有查到任何信息,这是因为我们没有指定搜索的语言,不但保存时候要指定编码,查询时也需要指定,查询命令如下:
127.0.0.1:6379> ft.search myidx "发布了" language "chinese"
1) (integer) 1
2) "doc2"
3) 1) "desc"2) "Java 14 \xe5\x9c\xa8 2020.3.17 \xe6\x97\xa5\xe5\x8f\x91\xe5\xb8\x83\xe6\xad\xa3\xe5\xbc\x8f\xe7\x89\x88\xe4\xba\x86\xef\xbc\x8c\xe4\xbd\x86\xe7\x8e\xb0\xe5\x9c\xa8\xe5\xbe\x88\xe5\xa4\x9a\xe5\x85\xac\xe5\x8f\xb8\xe8\xbf\x98\xe5\x9c\xa8\xe4\xbd\xbf\xe7\x94\xa8 Java 7 \xe6\x88\x96 Java 8"3) "title"4) "Java 14 \xe5\x8f\x91\xe5\xb8\x83\xe4\xba\x86\xef\xbc\x81\xe6\x96\xb0\xe5\x8a\x9f\xe8\x83\xbd\xe9\x80\x9f\xe8\xa7\x88"
从结果可以看出中文信息已经被顺利的查询出来了。
删除索引的数据
127.0.0.1:6379> ft.del myidx doc1
(integer) 1
我们使用索引加文档 ID 就可以实现删除数据的功能。
删除索引
我们可以使用“ft.drop”关键字删除整个索引,执行命令如下:
127.0.0.1:6379> ft.drop myidx
OK
查询索引详细信息
我们可以使用“ft.info”关键查询索引相关信息,执行命令如下:
127.0.0.1:6379> ft.info myidx1) index_name2) myidx3) index_options4) (empty list or set)5) fields6) 1) 1) title2) type3) TEXT4) WEIGHT5) "5"2) 1) desc2) type3) TEXT4) WEIGHT5) "1"7) num_docs8) "2"9) max_doc_id
10) "2"
11) num_terms
12) "9"
13) num_records
14) "18"
15) inverted_sz_mb
16) "0.000102996826171875"
17) total_inverted_index_blocks
18) "29"
19) offset_vectors_sz_mb
20) "1.71661376953125e-05"
21) doc_table_size_mb
22) "0.000164031982421875"
23) sortable_values_size_mb
24) "0"
25) key_table_size_mb
26) "8.0108642578125e-05"
27) records_per_doc_avg
28) "9"
29) bytes_per_record_avg
30) "6"
31) offsets_per_term_avg
32) "1"
33) offset_bits_per_record_avg
34) "8"
35) gc_stats
36) 1) bytes_collected2) "0"3) total_ms_run4) "16"5) total_cycles6) "14"7) avarage_cycle_time_ms8) "1.1428571428571428"9) last_run_time_ms10) "2"11) gc_numeric_trees_missed12) "0"13) gc_blocks_denied14) "0"
37) cursor_stats
38) 1) global_idle2) (integer) 03) global_total4) (integer) 05) index_capacity6) (integer) 1287) index_total8) (integer) 0
其中“num_docs”表示存储的数据数量。
整合
暂时还没整合后续更新ing