【MYSQL】分数排名
表: Scores
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | score | decimal | +-------------+---------+ id 是该表的主键(有不同值的列)。 该表的每一行都包含了一场比赛的分数。Score 是一个有两位小数点的浮点值。
编写一个解决方案来查询分数的排名。排名按以下规则计算:
- 分数应按从高到低排列。
- 如果两个分数相等,那么两个分数的排名应该相同。
- 在排名相同的分数后,排名数应该是下一个连续的整数。换句话说,排名之间不应该有空缺的数字。
按 score 降序返回结果表。
查询结果格式如下所示。
示例 1:
输入: Scores 表: +----+-------+ | id | score | +----+-------+ | 1 | 3.50 | | 2 | 3.65 | | 3 | 4.00 | | 4 | 3.85 | | 5 | 4.00 | | 6 | 3.65 | +----+-------+ 输出: +-------+------+ | score | rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | | 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+
MySQL
对于 SQL 用户,熟悉 窗口函数 在这里是有用的(对于大多数更高级的 SQL 问题也是如此):
窗口函数对一组查询行执行类似于聚合的操作。但是,聚合操作将查询行分组为一个单独的结果行,而窗口函数为每个查询行生成一个结果。
DENSE_RANK() 窗口函数恰好是我们在这个问题中需要的:
返回当前行在其分区中的排名,没有间隙。对等项被视为并列并获得相同的排名。此函数为对等组分配连续的排名;结果是大于一的组不产生不连续的排名号码。
看起来我们可以在这个问题中很好地使用 DENSE_RANK() 窗口函数。
SELECTS.score,DENSE_RANK() OVER (ORDER BYS.score DESC) AS 'rank'
FROMScores S;注意: MySQL 在 8.0 版本(2018 年 4 月 19 日)之前不支持窗口函数。一般来说,窗口函数直到 SQL:2003 才被引入 SQL,正如 MariaDB 的 窗口函数概述 文章中所述。
方法 2: 使用 COUNT(DISTINCT ...) 的相关子查询
简述
如果我们能够计算每个分数 S1.score 的不同分数 S2.score 的数量,而这些分数大于或等于此分数,那么这将有效地给我们提供 S1.score 的排名。然后我们可以按照 S1.score 对结果集进行排序,以符合问题的排名规则。
实现
可以使用 相关子查询 来完成上述的计数。
1.对于来自 Scores 表的每个分数,选择在 Scores 表中大于或等于此分数的不同分数的数量。
2.按照 score 对结果集进行排序。
SELECTS1.score,(SELECTCOUNT(DISTINCT S2.score)FROMScores S2WHERES2.score >= S1.score) AS 'rank'
FROMScores S1
ORDER BYS1.score DESC;
方法 3:使用 INNER JOIN 和 COUNT(DISTINCT...)
简述
这个方法的基本思想与 方法 2 的相同,但实现方式完全不同。
实现
1.将 Scores 表与自身连接,以便我们得到所有分数大于或等于此分数的所有行。
2.将查询行按 id 和 score 值进行分组。
3.计算唯一的分数的数量,它应该大于或等于连接条件中使用的分数(也就是排名)。
4.按 score 值对结果集进行排序。
MYSQL:
SELECTS.score,COUNT(DISTINCT T.score) AS 'rank'
FROMScores SINNER JOIN Scores T ON S.score <= T.score
GROUP BYS.id,S.score
ORDER BYS.score DESC;
上述解决方案是有效的,因为项目是如何分组的--COUNT() 聚合函数在分组上工作,从而为我们提供所需的结果。为了更清楚地看到上述查询的工作原理,我们可以检查以下查询的输出结果:
SELECTS.id AS S_ID,S.score AS S_Score,T.id AS T_ID,T.score AS T_Score
FROMScores SINNER JOIN Scores T ON S.score <= T.score
ORDER BYS.id,T.score;如果我们将这个查询应用于问题描述中给定的示例数据,那么我们将得到以下结果集:
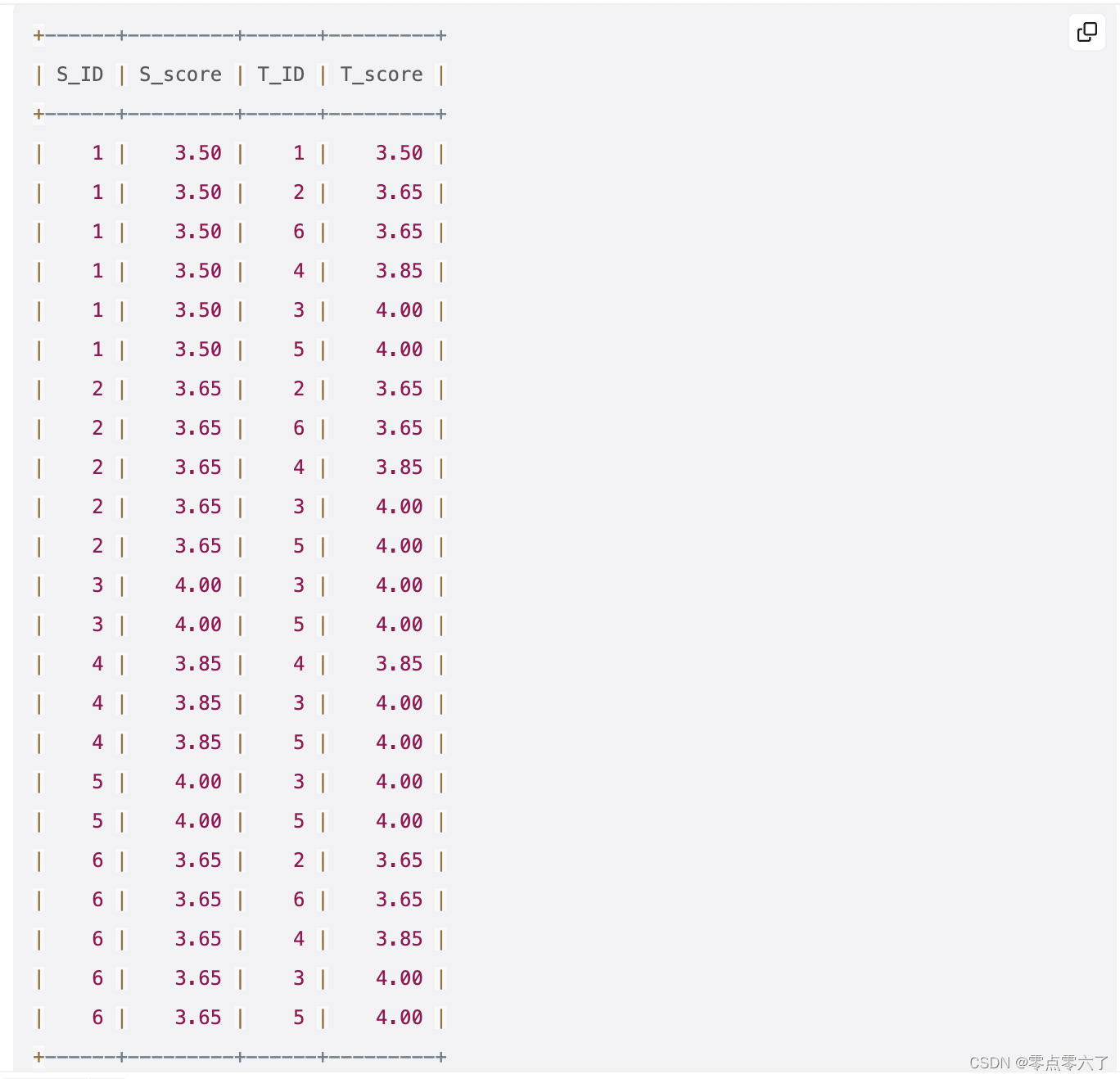
请注意,当我们在合适的分组上使用 COUNT(DISTINCT ...) 时,这为我们提供了所需的结果集

S_ID = 1;S_score = 3.50:有 4 个不同的 T_score 值(3.50、3.65、3.85 和 4.00)。
S_ID = 2;S_score = 3.65:有 3 个不同的 T_score 值(3.65、3.85 和 4.00)。
...
结论
出于各种原因,我们更喜欢 方法 1,特别是它的简单性、性能和上下文适用性。很少有问题会要求如此恰当地直接应用 DENSE_RANK()。但是,如 方法 1 结尾所述,窗口函数在 SQL 领域的到来相对较新,特别是对于它们在现代开发环境中的使用方式。
在面试环境中,方法 1 是最优的。但如果面试官要求不使用现代 SQL 工具(如窗口函数)来解决问题,使用 方法 2 或 方法 3 也是适当的策略。在这种情况下,方法 2 可能传达对 SQL 查询处理方式的更深入理解,而 方法 3 可能传达解决问题的创造性。无论哪种情况,都传达了一种积极和值得欢迎的特质。