[MySQL索引]3.索引的底层原理(二)
索引的底层原理(二)
- InnoDB的主键和二级/辅助索引树(涉及回表)
- MyISAM存储引擎的主键和二级索引树
InnoDB的主键和二级/辅助索引树(涉及回表)
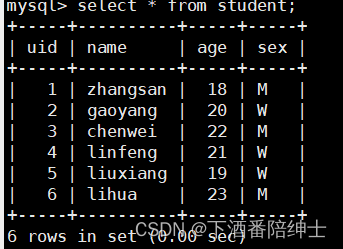
看下面这张student数据库表:
-
场景一:uid是主键
 主键索引树
主键索引树注意:主键索引树的key值是主键字段的值,就是uid的值,data存的是该值所在行的所有数据
select * from student; // 搜索的是整棵索引树// 等值查询,可以看到type为const,是根据索引值直接在索引树中进行搜索,最后只扫描一行就找到了data explain select * from student where uid=5;
// 范围搜索,type是range,并且rows为4,根据B+索引树的结果,我们知道范围搜索直接遍历叶子节点那一层的有序链表就可以了 explain select * from student where uid<5;
// where过滤条件后面是非索引字段,可以看到type为all,进行的是整表扫描 explain select * from student where name='zhangsan';
-
场景二:uid是主键,name创建了普通索引(二级索引)
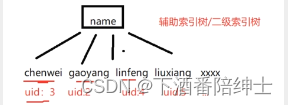 辅助索引树/二级索引树
辅助索引树/二级索引树注意:辅助索引树上key值是辅助索引的值,这里就是name的值,然后key所对应的data存的就是所在记录行的主键值
// where后面是name普通索引,select后面跟的也是该字段,这里只要在辅助索引树上进行搜索 select name from student where name='zhangsan';// 因为辅助索引树上key对应的data存的是所在行的主键,所以也只要在辅助索引树上进行搜索即可 select uid,name from student where name='zhangsan';// 先在辅助索引树上搜索到name,uid,然后再根据uid到主键索引树上去搜索,获得所在行的数据(age,sex),即回表操作; // 需要再到主键索引树上进行搜索,意味着更多的磁盘I/O以及搜索索引树所带来的时间开销 select * from student where name='zhangsan'; // 回表接下来再来一点复杂的:如果只给age添加索引(name没有),行不行?还有什么没有考虑到的呢?
select * from student where age=20 order by name;如果age上没有索引,执行SQL语句我们可以看到执行的是整表的搜索,而且还会进行文件排序(外排序),结果如下:

那如果我们只在age上添加索引字段呢?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QHNDqe29-1678283718216)(C:\Users\chenfei\AppData\Roaming\Typora\typora-user-images\image-20220424155957935.png)]
从上面结果可以看到查询时使用了age索引,但是依然会执行文件排序,尝试再给name字段创建索引,但是由于一张表的一次SQL查询只能用到一个索引,所以name上的索引不会用上,依然还是文件排序
综合上述的分析,我们可以得出结论:不能只给age添加索引,否则会执行文件排序,我们应该创建(age,name)的多列索引,所谓多列索引就是辅助索引树上的key值存的是(age+name),并且我们知道索引树是有序的(先按照age排序,age一样按照name排序),所以当我们使用age=20搜索索引树时,name已经是排好序了

不过需要注意多列索引一定要使用到第一个索引进行匹配
这里select 后面跟了*就涉及到了回表,因为辅助索引树不能获得所有字段的数据
MyISAM存储引擎的主键和二级索引树
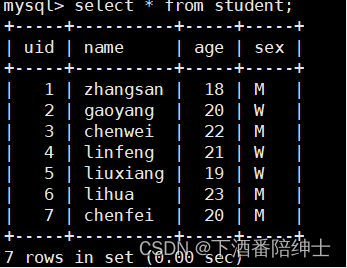
- 场景:uid是主键,name是二级索引
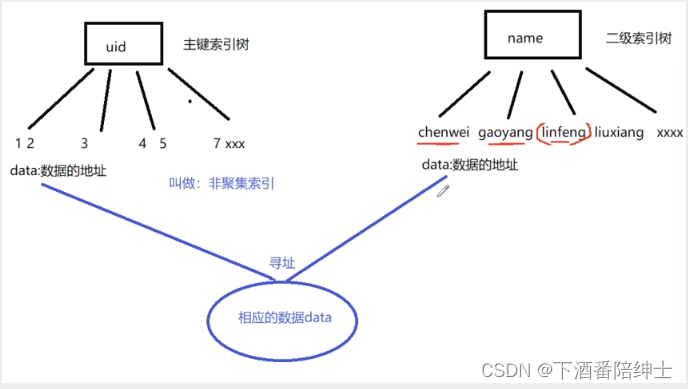
我们可以看到主键索引树和辅助索引树中key所对应的data存的都是数据的地址,这种 数据和索引没有存放在一起的结构叫做非聚集索引结构
而innoDB中的主键索引树和辅助索引树那种==索引和数据存放在一起的结构叫做聚集索引结构==
这样的话MyISAM存储引擎就涉及不到回表操作了。