NLP(16)--生成式任务
前言
仅记录学习过程,有问题欢迎讨论
输入输出均为不定长序列(seq2seq)
自回归语言模型:
- x 为 str[start : end ]; y为 [start+1 : end +1] 同时训练多个字,逐字计算交叉熵
encode-decode结构:
- Encoder将输入转化为向量或矩阵,其中包含了输入中的信息
- Decoder将Encoder的输出转化为输出
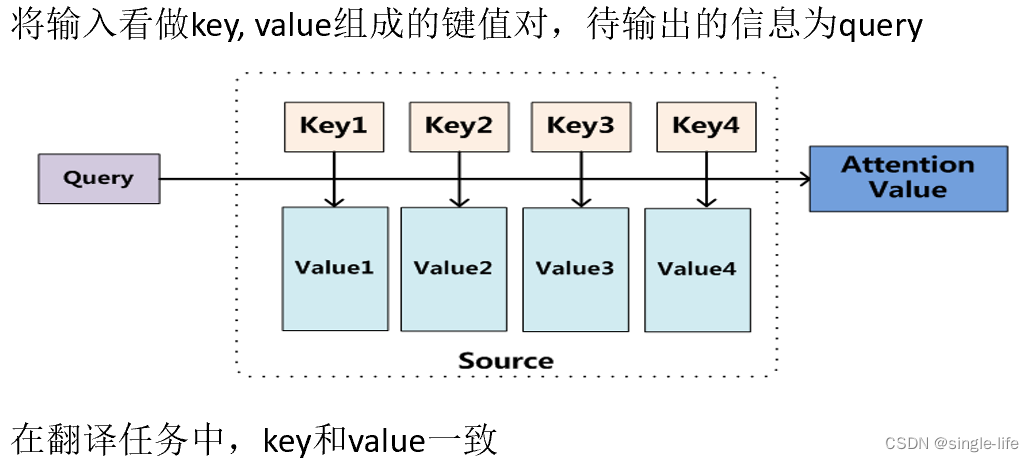
attention机制
- 输入和输出应该和重点句子强相关,给输入加权(所以维度应该和输入的size一致)
Teacher forcing
- 使用真实标签作为下一个输入(自回归语言模型就是使用的teacher forcing)
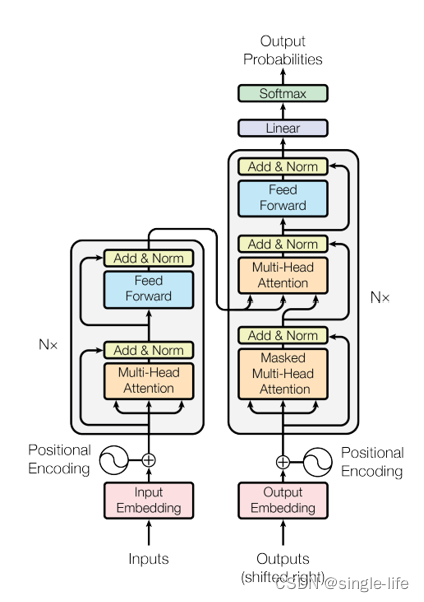
Transform结构
- Query来自Decode ,KV来自Encode
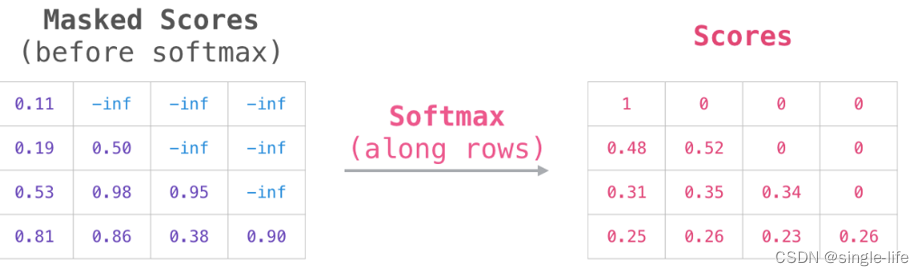
使用Mask Attation 来避免对output做计算时,获取了所有的信息。只使用当前的位置对应的output信息。(自回归模型,先mask,然后在softmax)
评价指标:
- BLEU:按照输出的字符计算一系列的数学(惩罚机制,Ngrim)计算来评价相似性
采样:
-
Beam size:
保留概率最大的n条路径 -
Temperature Sampling
根据概率分布生成下一个词,通过参数T,T越大,结果越随机,分布更均匀 -
TOP-P/K
采样先按概率从大到小排序,累加概率不超过P的范围中选
采样从TOP-K中采样下一个词
代码
使用bert实现自回归训练模型,
添加mask attention 来实现
# coding:utf8import torch
import torch.nn as nn
import numpy as np
import math
import random
import os
import refrom transformers import BertModel, BertTokenizer"""
基于pytorch的LSTM语言模型
"""class LanguageModel(nn.Module):def __init__(self, input_dim, vocab_size):super(LanguageModel, self).__init__()# self.embedding = nn.Embedding(len(vocab), input_dim)# self.layer = nn.LSTM(input_dim, input_dim, num_layers=1, batch_first=True)self.bert = BertModel.from_pretrained(r"D:\NLP\video\第六周\bert-base-chinese", return_dict=False)self.classify = nn.Linear(input_dim, vocab_size)# self.dropout = nn.Dropout(0.1)self.loss = nn.functional.cross_entropy# 当输入真实标签,返回loss值;无真实标签,返回预测值def forward(self, x, y=None):# x = self.embedding(x) # output shape:(batch_size, sen_len, input_dim)# 使用mask来防止提前预知结果if y is not None:# 构建一个下三角的mask# bert的mask attention 为(batch_size, vocab_size, vocab_size) L*Lmask = torch.tril(torch.ones(x.shape[0], x.shape[1], x.shape[1]))print(mask)x, _ = self.bert(x, attention_mask=mask)y_pred = self.classify(x)return self.loss(y_pred.view(-1, y_pred.shape[-1]), y.view(-1))else:x = self.bert(x)[0]y_pred = self.classify(x)return torch.softmax(y_pred, dim=-1)# 加载字表
def build_vocab(vocab_path):vocab = {"<pad>": 0}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):char = line[:-1] # 去掉结尾换行符vocab[char] = index + 1 # 留出0位给pad tokenreturn vocab# 加载语料
def load_corpus(path):corpus = ""with open(path, encoding="utf8") as f:for line in f:corpus += line.strip()return corpus# 随机生成一个样本
# 从文本中截取随机窗口,前n个字作为输入,最后一个字作为输出
def build_sample(tokenizer, window_size, corpus):start = random.randint(0, len(corpus) - 1 - window_size)end = start + window_sizewindow = corpus[start:end]target = corpus[start + 1:end + 1] # 输入输出错开一位# print(window, target)# 中文的文本转化为tokenizer的idinput_ids_x = tokenizer.encode(window, add_special_tokens=False, padding='max_length', truncation=True,max_length=10)input_ids_y = tokenizer.encode(target, add_special_tokens=False, padding='max_length', truncation=True,max_length=10)return input_ids_x, input_ids_y# 建立数据集
# sample_length 输入需要的样本数量。需要多少生成多少
# vocab 词表
# window_size 样本长度
# corpus 语料字符串
def build_dataset(sample_length, tokenizer, window_size, corpus):dataset_x = []dataset_y = []for i in range(sample_length):x, y = build_sample(tokenizer, window_size, corpus)dataset_x.append(x)dataset_y.append(y)return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)# 建立模型
def build_model(vocab_size, char_dim):model = LanguageModel(char_dim, vocab_size)return model# 文本生成测试代码
def generate_sentence(openings, model, tokenizer, window_size):# reverse_vocab = dict((y, x) for x, y in vocab.items())model.eval()with torch.no_grad():pred_char = ""# 生成文本超过30字终止while len(openings) <= 30:openings += pred_charx = tokenizer.encode(openings, add_special_tokens=False, padding='max_length', truncation=True,max_length=10)x = torch.LongTensor([x])if torch.cuda.is_available():x = x.cuda()# batch_size = 1 最后一个字符的概率y = model(x)[0][-1]index = sampling_strategy(y)# 转化为中文 只有一个字符pred_char = tokenizer.decode(index)return openings# 采样方式
def sampling_strategy(prob_distribution):if random.random() > 0.1:strategy = "greedy"else:strategy = "sampling"if strategy == "greedy":return int(torch.argmax(prob_distribution))elif strategy == "sampling":prob_distribution = prob_distribution.cpu().numpy()return np.random.choice(list(range(len(prob_distribution))), p=prob_distribution)# 计算文本ppl
def calc_perplexity(sentence, model, vocab, window_size):prob = 0model.eval()with torch.no_grad():for i in range(1, len(sentence)):start = max(0, i - window_size)window = sentence[start:i]x = [vocab.get(char, vocab["<UNK>"]) for char in window]x = torch.LongTensor([x])target = sentence[i]target_index = vocab.get(target, vocab["<UNK>"])if torch.cuda.is_available():x = x.cuda()pred_prob_distribute = model(x)[0][-1]target_prob = pred_prob_distribute[target_index]prob += math.log(target_prob, 10)return 2 ** (prob * (-1 / len(sentence)))def train(corpus_path, save_weight=True):epoch_num = 15 # 训练轮数batch_size = 64 # 每次训练样本个数train_sample = 10000 # 每轮训练总共训练的样本总数char_dim = 768 # 每个字的维度window_size = 10 # 样本文本长度# vocab = build_vocab(r"vocab.txt") # 建立字表tokenizer = BertTokenizer.from_pretrained(r"D:\NLP\video\第六周\bert-base-chinese")vocab_size = 21128corpus = load_corpus(corpus_path) # 加载语料model = build_model(vocab_size, char_dim) # 建立模型if torch.cuda.is_available():model = model.cuda()optim = torch.optim.Adam(model.parameters(), lr=0.001) # 建立优化器print("文本词表模型加载完毕,开始训练")for epoch in range(epoch_num):model.train()watch_loss = []for batch in range(int(train_sample / batch_size)):x, y = build_dataset(batch_size, tokenizer, window_size, corpus) # 构建一组训练样本if torch.cuda.is_available():x, y = x.cuda(), y.cuda()optim.zero_grad() # 梯度归零loss = model(x, y) # 计算lossloss.backward() # 计算梯度optim.step() # 更新权重watch_loss.append(loss.item())print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))print(generate_sentence("忽然一阵狂风吹过,他直接", model, tokenizer, window_size))print(generate_sentence("天青色等烟雨,而我在", model, tokenizer, window_size))if not save_weight:returnelse:base_name = os.path.basename(corpus_path).replace("txt", "pth")model_path = os.path.join("model", base_name)torch.save(model.state_dict(), model_path)returnif __name__ == "__main__":train("corpus.txt", False)# mask = torch.tril(torch.ones(4, 4)).unsqueeze(0).unsqueeze(0)# print(mask)