Google发布的CAT3D,在1分钟内,能够从任意数量的真实或生成的图像创建3D场景。
给定任意数量的输入图像,使用以这些图像为条件的多视图扩散模型来生成场景的新视图。生成的视图被输入到强大的 3D 重建管道,生成可以交互渲染的 3D 表示。总处理时间(包括视图生成和 3D 重建)仅需一分钟。


相关链接
论文:https://arxiv.org/pdf/2405.10314
项目:cat3d.github.io
论文阅读

CAT3D:使用多视图扩散模型以3D形式创建任何内容
摘要
3D重建的进步使高质量的3D捕获成为可能,但需要用户收集数百到数千张图像来创建3D场景。我们提出了cat3d,这是一种通过多视图扩散模型模拟真实世界的捕获过程来创建任何3D内容的方法。给定任意数量的输入图像和一组目标新颖视点,我们的模型生成高度一致的场景新颖视点。
这些生成的视图可以用作鲁棒的3D重建技术的输入,以产生可以从任何视点实时呈现的3D表示。CAT3D可以在短短一分钟内创建整个3D场景,并且优于现有的单图像和少视图3D场景创建方法。

方法
CAT3D是3D创建的两步方法:首先,我们使用多视图扩散模型生成大量与一个或多个输入视图一致的新视图,其次生成视图的鲁棒3D重建管道。我们从多视图扩散模型中生成大量几乎一致的新视图的方法,以及如何在3D重建管道中使用这些生成的视图。
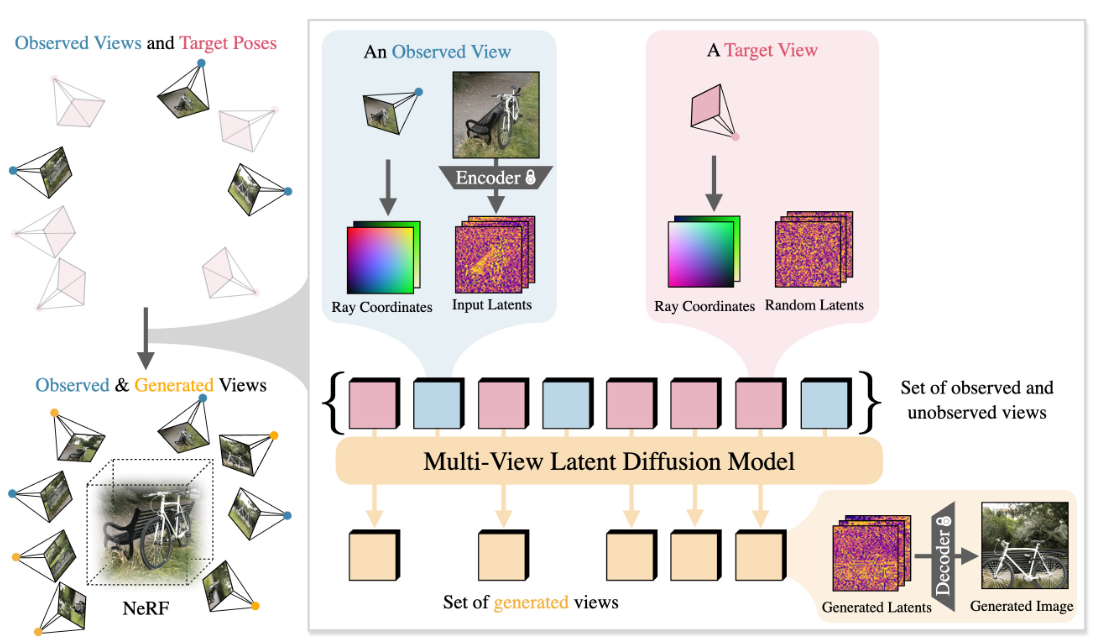
给定一对多视图,CAT3D在短短一分钟内创建整个场景的3D表示。CAT3D分为两个阶段:
-
(1)以输入视图和目标视图的相机姿态为条件,从多视图潜在扩散模型生成大量合成视图;
-
(2)在观察到的和生成的视图上运行一个鲁棒的3D重建管道,以学习NeRF表示。这种生成先验与3d重建过程的解耦导致了计算效率的提高和相对于先前工作的方法复杂性的降低,同时也产生了改进的图像均衡性。
实验
定性结果:CAT3D可以通过多种输入方式创建高质量的3D对象或场景:由文本到图像模型生成的输入图像(第1-2行),单个捕获的真实图像(第3-4行)和多个捕获的真实图像(第5行)。



mip-NeRF360和CO3D数据集场景少视图重建的定性比较。这里显示的示例是渲染图像,有3个输入捕获视图。与ReconFusion等基线方法相比,CAT3D在可见区域与地面真实相符,而在不可见区域产生似是而非的内容。

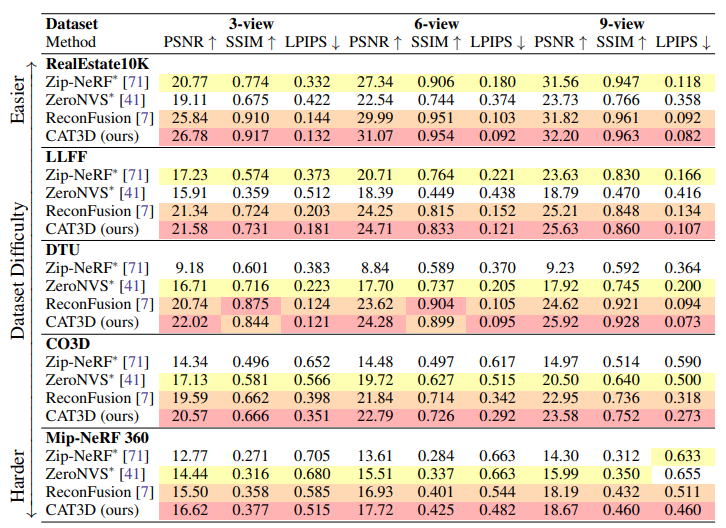
少视图三维重建的定量比较。CAT3D在几乎所有设置和指标上都优于基线方法(修改后的基线用取自的∗表示)。
从单一输入图像的3D创建。来自CAT3D的3D模型效果图(中图)的质量高于场景的基线(下行),并且对对象具有竞争力。请注意,比例歧义放大了方法之间渲染的差异。

结论
我们提出了CAT3D,一种从任意数量的输入图像创建3D内容的统一方法。CAT3D利用多视图扩散模型生成高度一致的3D场景新视图,然后将其输入到3D多视图重建管道中。CAT3D将生成先验与3D提取分离,从而实现高效、简单和高质量的3D生成。
尽管CAT3D产生了令人信服的结果,并且在多个任务上优于先前的工作,但它的局限性。因为我们的训练数据集对于相同场景的视图具有大致恒定的相机特征,所以训练模型不能很好地处理由多个具有不同特征的相机捕获的输入视图的测试用例。CAT3D的生成质量依赖于基本文本到图像模型的表达能力,当场景内容不在基础模型的分布范围内时,CAT3D的表现会更差。
我们的多视图扩散模型支持的输出视图数量仍然相对较少,因此当我们从模型中生成大量样本时,并非所有视图都可能彼此3D一致。最后,CAT3D使用手动构建的相机轨迹完全覆盖场景,这可能很难设计大规模开放式3D环境。
在未来的工作中,CAT3D的改进有几个值得探索的方向。多视图扩散模型可以从预训练的视频扩散模型初始化中受益。通过扩展模型处理的条件视图和目标视图的数量,可以进一步提高样本的一致性。自动确定不同场景所需的相机轨迹可以增加系统的灵活性.