【RAG 论文】UPR:使用 LLM 来做检索后的 re-rank
论文:Improving Passage Retrieval with Zero-Shot Question Generation
⭐⭐⭐⭐
EMNLP 2022, arXiv:2204.07496
Code: github.com/DevSinghSachan/unsupervised-passage-reranking
论文:Open-source Large Language Models are Strong Zero-shot Query Likelihood Models for Document Ranking
⭐⭐⭐⭐
EMNLP 2023, arXiv:2310.13243
Code: github.com/ielab/llm-qlm
一、UPR 论文速读
关于 Improving Passage Retrieval with Zero-Shot Question Generation 这篇论文
论文提出了一个基于 LLM 的 re-ranker:UPR(Unsupervised Passage Re-ranker),它不需要任何标注数据用于训练,只需要一个通用的 PLM(pretrained LM),并且可以用在多种类型的检索思路上。
给定一个 corpus 包含所有的 evidence documents,给定一个 question,由 Retriever 来从 corpus 中检索出 top-K passages,re-ranker 的任务就是把这 K 个 passages 做重新排序,期待重排后再交给 LLM 做 RAG 能提升效果。
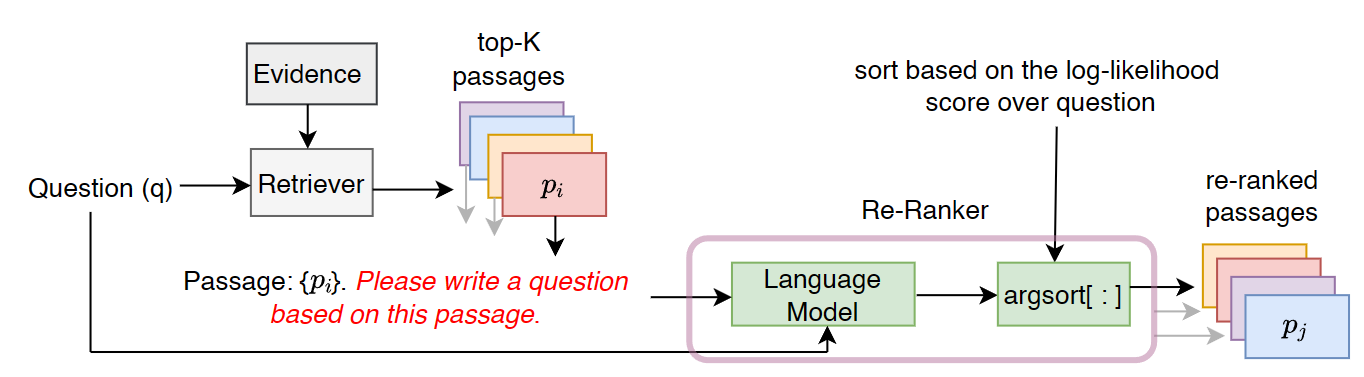
本论文的工作中,使用 LLM 来为每一个 passage 计算一个 relevance score,然后按照 relevance scores 来对这些 passages 做排序。passages z i z_i zi 的 relevance score 的计算方式是:以 passage z i z_i zi 为条件,计算 LLM 生成 question q q q 的 log-likelihood log p ( q ∣ z i ) \log p(q|z_i) logp(q∣zi):
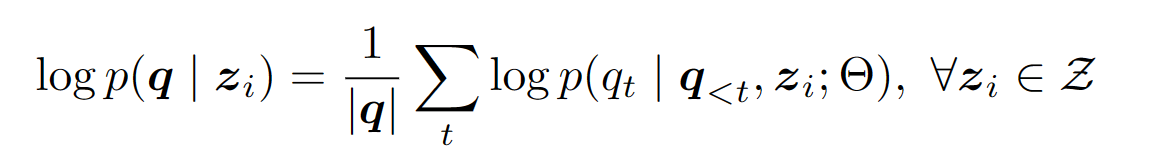
关于为什么使用 p ( q ∣ z ) p(q|z) p(q∣z) 来计算 relevance score 而非用 p ( z ∣ q ) p(z|q) p(z∣q),原因在于在假设 log p ( z i ) \log p(z_i) logp(zi) 是都一样的话,按照 Bayes 公式来算的话, p ( q ∣ z ) p(q|z) p(q∣z) 与 p ( z ∣ q ) p(z|q) p(z∣q) 呈正相关的关系。此外,使用 p(q|z) 允许模型利用交叉注意力机制(cross-attention)在问题和段落之间建立联系。而且实验发现使用 p ( q ∣ z ) p(q|z) p(q∣z) 效果更好。
其实从感性上想一想,也是通过 prompt 让 LLM 去计算 p ( q ∣ z ) p(q|z) p(q∣z) 来建模 question 和 passage 更合理。
二、开源 LLM 本身就是强 zero-shot 的 QLM re-ranker
QLM(Query Likelihood Model) 是指,通过计算特定 question 下 document 的概率来理解 docs 和 queries 的语义关系。QLM re-ranker 就是借助这个概率得出相关性分数从而做出排名,进而实现 re-rank。前面介绍的 UPR 就是一种 QLM re-ranker。
在前面介绍的 UPR 中,使用了 T0 LLM 模型作为 QLM 从而实现了有效的 re-rank,但是由于 T0 在许多 QG(Question Generation) 数据集上做了微调,所以该工作不能完全反映通用的 zero-shot 的 QLM ranking 场景。
本工作研究了使用 LLaMA 和 Falcon 这两个 decoder-only 的模型作为 QLM 来做 re-rank 任务的表现,这两个 LLM 都没有在 QG 数据集上做训练。
2.1 多种 QLM re-ranker
本文工作设计了多种 QLM re-ranker,下面分别做一个介绍。
1)Zero-shot QLM re-ranker
类似于前面 UPR 的做法,借助于 QLM 计算出一个 relevance score,计算方法也一样(以 retrieved doc 为条件的 question 的概率):
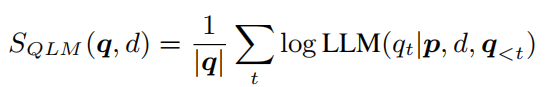
2)BM25 插值的 re-ranker
除了使用 QLM 计算出来的分数 S Q L M S_{QLM} SQLM,还融入第一阶段的检索器 BM25 给出的相关性分数,两者通过权重共同计算最终的 relevance score:
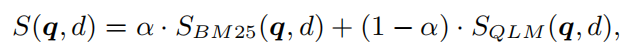
3)Few-shot QLM re-ranker
在前面 zero-shot 的基础上,使用 LLM 时,设计一个 prompt template 并加入一些 few-shot exemplars。
2.2 实验
论文详细介绍了多个实验,感兴趣可以参考原论文,这里列出几个结论:
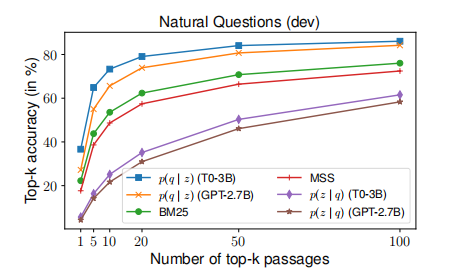
- 在 QG 数据集(NS NARCO 数据集)上微调的 retriever 和 re-ranker 在所有数据集上表现都由于 zero-shot 的 retriever 和 QLM re-ranker,这是意料之中的,因为这些方法会受益于大量人工判断的 QA 训练数据,其知识可以有效地迁移到测试数据集中。
- zero-shot 的 QLM 和经过 QG 指令微调的 QLM 表现出相似的竞争力,这一发现时令人惊讶的,这说明 pretrained-only 的 LLM 就具有强大的 zero-shot QLM 排名的能力。
- 如果 QG 任务没有出现在指令微调的数据中,那么指令微调反而会阻碍 LLM 的 QLM re-rank 能力。猜测原因在于,指令微调的模型往往更关注任务指令,而较少关注输入内容本身,但是评估 Query Likelihood 的最重要信息都在文档内容中,所以指令调优不利用 LLM 的 Query Likelihood 的估计。
- BM25 插值策略的改进究竟有没有用,取决于具体的 LLM 模型。
2.3 一个有效的 ranking pipeline
这篇论文工作(原文 4.3 节)还提出了一个有效的 ranking pipeline。
在第一阶段的 retriever 中,将 BM25 和 HyDE 结合作为 zero-shot first-stage hybird retriever,然后再使用 QLM 做 re-rank。
经过实验发现,这种方法可以与当前 SOTA 模型表现相当,重要的这种方法不需要任何训练。
总结
这两篇论文给了我们使用 LLM 来做 QLM re-rank 的思路,展现了通用的 LLM 本身具备强大的 QLM re-rank 的能力。