淘宝数据分析——Python爬虫模式♥

大数据时代,
数据收集不仅是科学研究的基石,
更是企业决策的关键。
然而,如何高效地收集数据
成了摆在我们面前的一项重要任务。
本文将为你揭示,
一系列实时数据采集方法,
助你在信息洪流中,
找到真正有价值的信息。
提升方法
通常我们在使用爬虫的时候会爬取很多数据,而这些数据里边什么是有用的数据,什么是没用的数据,这个是值得我们关注的,在这一篇文章里,我们将通过一个简单的爬虫,来去简单介绍下如何使用python来去做数据分析.
1:爬虫部分
在这一篇文章中我们会以淘宝为例,爬取淘宝的店铺和商家信息,然后去进行分析,首先我们打开淘宝首页,搜索你想要查询的产品:

这里我们会发现在商品信息哪里会有商品的价格,商品的销量,商家店铺名称以及商家的地址,这时候我们就需要去解析网页,去从网页中寻找这些信息,在处理在这些信息我们要用到的是正则匹配公式.(建议多尝试几次,因为有时候服务器不太好会匹配不到).
另外在实现翻页的时候,淘宝的页码公式是44(k-1)

我们匹配的只需要是蓝色地部分,其中需要匹配的是(.*?),不需要匹配的是.*?,detail_url"这个不需要匹配.
在匹配之后,我们需要将爬取的数据写入文件中,这时候就需要引入pandas模块来去进行处理,写入文件保存在csv文件中.(csv文件无论是在我们机器学习或者是爬虫里都是处理数据的关键文件),在保存完数据之后,我们要对数据进行处理,加上标题,方便之后处理.

在这个例子,我们分析的是店家的销售数据: 这时候销售总额=销量*单价
![]()
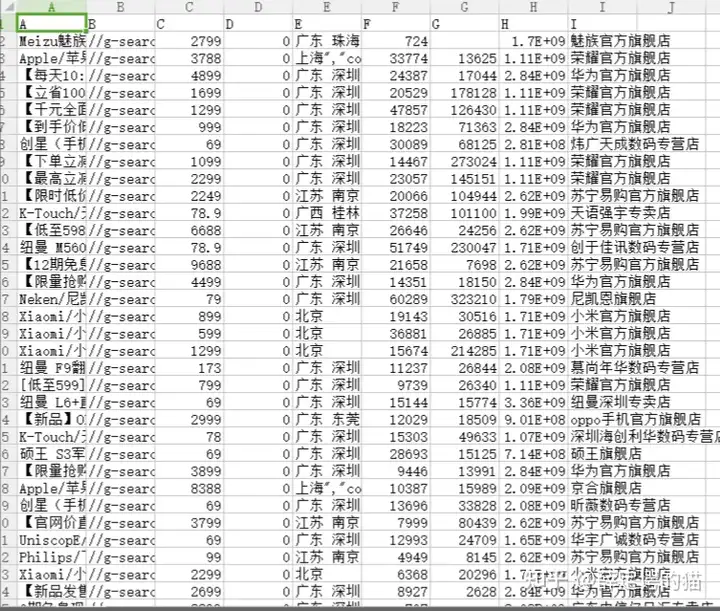
2:数据分析处理部分
在这一个部分我们处理的是pandas处理数据和matplotlib来绘制图形.

最后使用plot把图显示出来:

样式1

样式2
这时候销量的好坏就可以一目了然,当然,我们还可以做的还可以更多,但是这一篇文章的作用是希望大家能够去动手做更多有意思的事,这才是学习的意义.
最后代码部分:
#爬虫部分 import requests #网络请求 import re #正则表达式,提取数据 import pandas #数据分析模块 for ii in range(1,10):#实现翻页mn = 44*(ii-1)url = 'https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20171223&ie=utf8&psort=_lw_quantity&vlist=1&app=vproduct&cps=yes&cd=false&v=auction&tab=all&bcoffset=4&ntoffset=4&p4ppushleft=1%2C48&s='+str(mn)header ={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36'}html = requests.request('GET',url,headers=header)#加快执行效率ren = re.compile('"raw_title":"(.*?)","pic_url":"(.*?)","detail_url":".*?","view_price":"(.*?)","view_fee":"(.*?)","item_loc":"(.*?)","view_sales":"(.*?)人付款","comment_count":"(.*?)","user_id":"(.*?)","nick":"(.*?)"')data =re.findall(ren,html.text)
#数据块 import pandas import matplotlib as mpl #字体模块 import matplotlib.pyplot as plt #绘图模块mpl.rcParams["font.sans-serif"] = ['SimHei']#配置字体 #绘图格式 plt.rcParams["axes.labelsize"] = 16 plt.rcParams["xtick.labelsize"] =15 plt.rcParams["ytick.labelsize"] =10 plt.rcParams["legend.fontsize"]=10#图例字体大小 plt.rcParams["figure.figsize"]=[15,12]def1 =pandas.read_csv('D:\TBB.csv') TBdata = pandas.DataFrame(list(zip(def1['I'],def1['F']*def1['C']))) #可视化 DD = TBdata.groupby([0]).sum() DD[1].plot(kind='bar',rot=90) DD[1].plot(rot=90)#底下标旋转90度 plt.show()
