爬虫学习:XPath提取网页数据
目录
一、安装XPath
二、XPath的基础语法
1.选取节点
三、使用XPath匹配数据
1.浏览器审查元素
2.具体实例
四、总结
一、安装XPath
控制台输入指令:pip install lxml
二、XPath的基础语法
XPath是一种在XML文档中查找信息的语言,可以使用它在HTML源代码文档中通过元素、属性等方式进行查找和提取数据。
1.选取节点
| 表达式 | 描述 |
| nodename | 选取此元素的所有子元素。 例:div选取div下所有子元素。 |
| / | 从根节点选取子节点。 例:/div选取根元素div |
| // | 从匹配选择的当前元素下选择文档中的元素,而不考虑它们在文档中的位置。 |
| . | 选取当前元素。 |
| .. | 选取父元素。 |
| @ | 选取属性。 |
例:XPath的常用语法格式
ul//li
#选取ul下所有li子元素,而不管它们在文档的位置。
//@class
# 选取所有具有class属性的元素
ul//li[1]
# 选取ul元素下第一个li子元素
//div[@id="t2"]
# 选取id属性为t2的所有div元素
//li[@class="it"]
#选取class属性为it的li子元素
/div/ul/li[@class="it"]
# 选取根元素div下ul元素下的class属性等于it的li子元素三、使用XPath匹配数据
1.浏览器审查元素
上文初步了解了XPath的语法,这里介绍一个技巧,无需我们自己写XPath,使用浏览器自带工具即可,自动生成XPath。
第一步:打开要爬取的网页( 以机场三字代码查询系统_机场代码 (6qt.net)为例)
按下F12,显示以下界面。
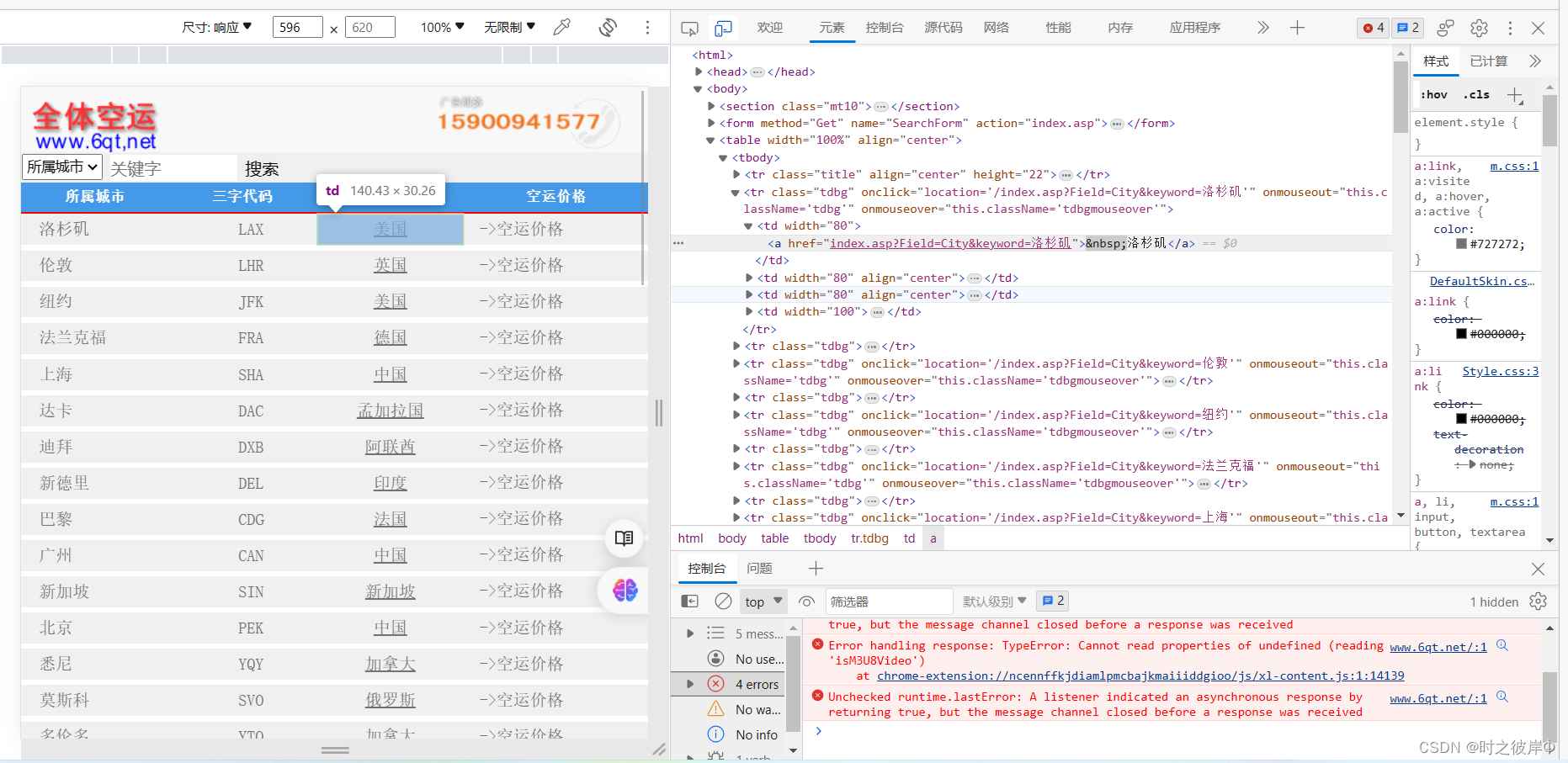
第二步: 点击审查元素按钮

第三步:在左侧选取要爬取的内容
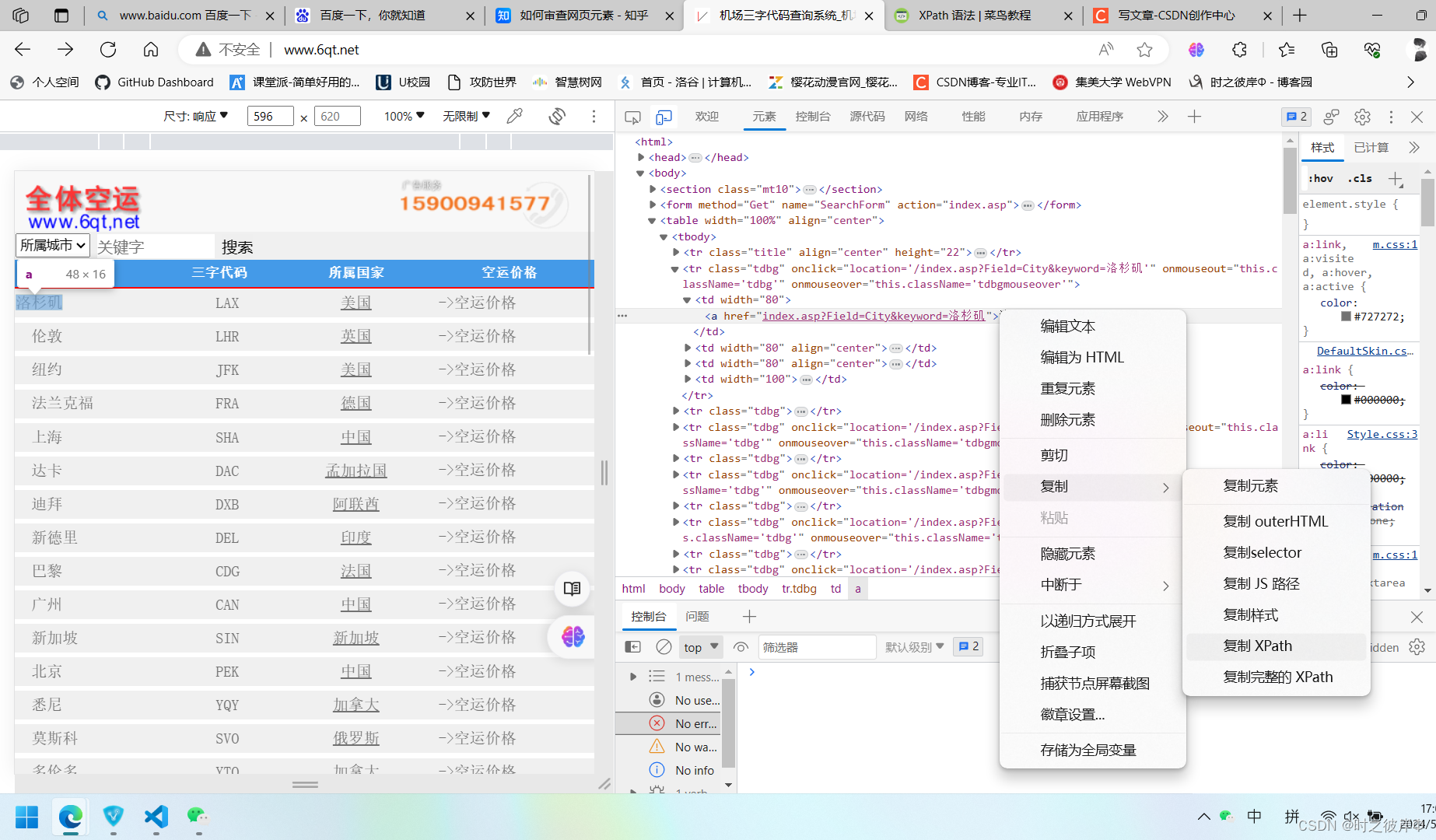
2.具体实例
实例一:根据class属性进行匹配
获取标签文本使用text() 。
from lxml import html
import requests
url="http://www.6qt.net"
res=requests.get(url)
res.encoding="gb2312"
data_html=html.fromstring(res.text)
# 将网络请求返回的文本res.text转换为一个HTML文档对象
name_list=data_html.xpath('//tr[@class="tdbg"]//td[1]/a/text()')
for x in name_list:print(x)运行结果:

实例二:根据id属性进行匹配
获取标签属性值使用@属性名,以下案例获取了属性title值:@title 。
from lxml import html
import requests
url="http://www.6qt.net"
res=requests.get(url)
res.encoding="gb2312"
data_html=html.fromstring(res.text)
# 将网络请求返回的文本res.text转换为一个HTML文档对象
name_list=data_html.xpath('//div[@id="logo"]/a/@title')
for x in name_list:print(x)运行结果:

实例三:根据name属性进行匹配
获取了meta标签的content属性
from lxml import html
import requests
url="http://www.6qt.net"
res=requests.get(url)
res.encoding="gb2312"
data_html=html.fromstring(res.text)
# 将网络请求返回的文本res.text转换为一个HTML文档对象
name_list=data_html.xpath('/html/head/meta[@name="Keywords"]/@content')
for x in name_list:print(x)运行结果:

四、总结
爬虫是一个自动化获取网页数据的工具,其使用关键在于会分析HTML文档结构,使用正确的Xpath匹配数据,才能获取到想要的内容,所见即所得。