基于FPGA的数字信号处理(9)--定点数据的两种溢出处理模式:饱和(Saturate)和绕回(Wrap)
1、前言
在逻辑设计中,为了保证运算结果的正确性,常常需要对结果的位宽进行扩展。比如2个3bits的无符号数相加,只有将结果设定为4bits,才能保证结果一定是正确的。不然,某些情况如7+7 = 14(1110),如果结果只用3bits表示那么就成了110(6)了,这样运算的结果就是错的。同理,乘法操作需要扩展的位宽更大,是两个乘数的位宽之和,比如2个3bits的无符号数做乘法,结果需要设定为6bits。
如果在后续数据处理的过程中,一直都这样对结果的位宽进行扩展,那么在算法链很长的情况下,将会消耗大量的逻辑资源。因此在设计中,常常需要对数据进行的位宽进行处理。
数据的位宽处理分为两个部分:
- 对整数的处理:例如原本用6bits表示的结果,下级模块规定只能用到4bits输入。因为6bits的表示范围大于4bits,就有可能出现4bits无法表示的情况(即溢出)
- 对小数的处理:原理同上。四舍五入就是一种经典的对小数截位的方式,类似的方法还有ceili,floor,nearest等等。
本文只讨论整数部分的溢出截位处理,小数部分的处理下篇文章再说。对整数的截位处理,实际上就是对溢出的处理,其决定了当运算结果大于该数位宽所能表示的最大值时,如果对溢出部分处理。通常有两种对溢出的处理方式:
- Saturate(饱和):一旦数据溢出,那么就将结果饱和处理为最大值或最小值(取决于正向溢出还是负向溢出)
- Wrap(绕回/截断):一旦数据溢出,那么就直接将溢出的高位截断
将6bits的整数41截位到4bits,两种溢出模式的处理结果如下:
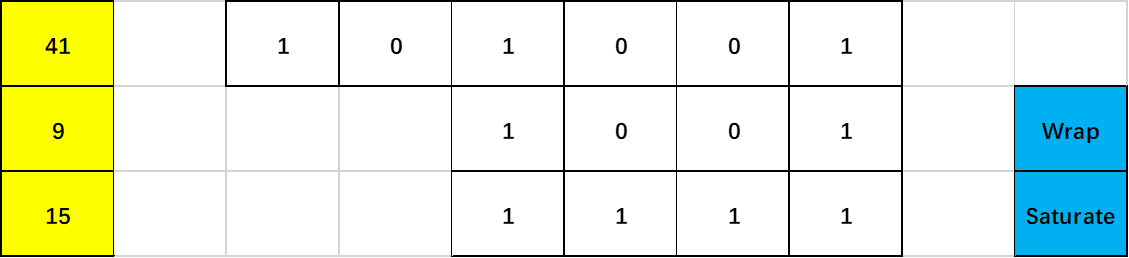
2、Saturate
因为有符号数和无符号存在表示范围的区别,所以二者的溢出处理也存在一定的区别,接下来对两种情况分别进行讨论。
2.1、无符号数的Saturate
Saturate是当数据溢出时,就直接用最大值或最小值来表示。因为无符号数不能表示负数,因此不存在对于负数的饱和处理,只存在正向的饱和。例如要将1个6bits的数截断到4bits,因为4bits能表示的最大值是15,那么所有大于15的数,都直接用15来表示,示意图如下:

将1个6bits的输入Saturate为4bits的输出,用Verilog可以这么写:
module test(input [5:0] data_6bits,output reg [3:0] data_4bits
);always@(*)
beginif(data_6bits > 4'd15) //溢出了data_4bits = 4'd15; //饱和到最大值else data_4bits = data_6bits; //没溢出则直接赋值
endendmodule
除了直接用大于符号(data_6bits > 4’d15)来判断是否溢出外,也可以这样判断:
if(|data_6bits[5:4]) //判断高2位是否存在1,若存在则该数的值必定大于15
再写个TB测试一下:因为输入比较少,所以可以用穷举法来测试,把输入从最小值0开始累加最大值63,观察输出是否会被Saturate。
`timescale 1ns/1ns
module test_tb();reg [5:0] data_6bits;
wire [3:0] data_4bits;//例化被测试模块
test test_inst(.data_6bits (data_6bits),.data_4bits (data_4bits)
);initial begindata_6bits = 0;while(~(&data_6bits))begin //当输入不全为1,即非最大值data_6bits = data_6bits + 1; //从0开始累加1#5;end#20 $stop();
endendmodule
仿真结果是这样的:

当输入超过4bits位宽能表示的最大值15时,就会都饱和处理,即输出为最大值15。
2.2、有符号数Saturate
对于有符号数的Saturate处理有两种情况:
- 正数太大无法表示,只能饱和到最大值。例如4bits有符号数最大只能表示 7,那么大于7的数就只能饱和处理为 7。
- 负数太小无法表示,只能饱和到最小值。例如4bits有符号数最小只能表示 -8,那么小于-8的数就只能饱和处理为 -8。
当数据溢出时,就直接用最大值或最小值来表示。因为无符号数不能表示负数,因此不存在对于负数的饱和处理,只存在正向的饱和。例如要将1个6bits的数截断到4bits,因为4bits能表示的最大值是15,那么所有大于15的数,都直接用15来表示,示意图如下:
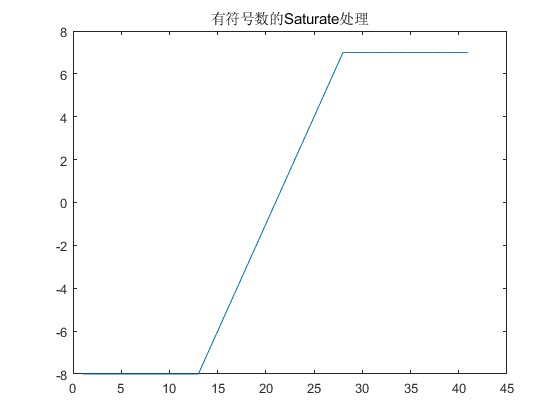
例如,将1个6bits的有符号数Saturate为4bits,对于数据的正向溢出判断和无符号数的Saturate是类似的,只要判断除了符号位的多出来的高位是否有1即可。
对于数据的负数方向溢出判断要麻烦一点,首先我们要知道,对于一个有符号的负数,在其高位扩展符号位,其数值是不会改变的。例如:
10\110\1110\11110,它们表示的都是 -2。
把6bits截位到4bits,只要判断它的高三位(因为讨论的是负数,所以最高位肯定是1)是否都为1就行了,如果是的话,说明高3位可是视为是1位符号位的扩展,数据的表示范围等价于4bits的表示范围。如果不为全1,则说明比4bits的表示范围要大,即数据产生了溢出。
综上,用Verilog可以这么写:
module test(input [5:0] data_6bits,output reg [3:0] data_4bits
);always@(*)
beginif(~data_6bits[5] && (|data_6bits[4:3])) //判断条件(正数 && 溢出),即正向溢出了data_4bits = 4'b0111; //饱和到最大值7else if(data_6bits[5] && ~(&data_6bits[4:3])) //判断条件(负数 && 溢出),即负向溢出了 data_4bits = 4'b1000; //饱和到最小值-8else data_4bits = data_6bits; //没溢出则直接赋值
endendmodule
仍然用上面的TB,仿真结果如下:
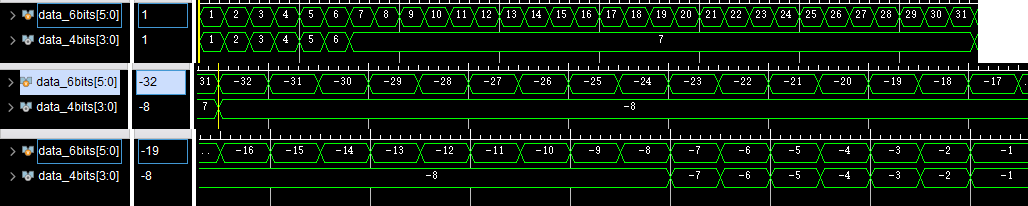
3、Wrap
Wrap从字面上理解是绕回,什么是绕回呢?比如一块手表,它只能表示0点~12点,超出了12点的话,它就会绕回到0点再重新开始。比如13点的表示就是到了12点后,再走到了1点。
对数据的Wrap处理也是类似的,比如4bits的无符号数最多只能表示1111(15),这个时候如果再加1就是16了,16是表示不了的。Saturate是直接表示最大值15,而Wrap则是重新回到开始表示0。类似的,17就Wrap到1,18就Wrap到2,19就Wrap到3,依此类推。示意图如下:

对于有符号数的Wrap处理也是一样的截掉高位,但是因为有符号数可以表示负数,所以它的绕回是从最小的负数开始的,例如最大的4bits有符号数是0111即7,溢出后是1000即-8,示意图如下:

Wrap处理用Verilog是很好实现的,因为它本质上相当于截掉高位,而截掉高位这个操作是可以被综合工具自动实现的,它甚至都不需要消耗任何逻辑资源。比如,将1个6bits的输入Wrap为4bits的输出,用Verilog可以这么写:
module test(input [5:0] data_6bits,output [3:0] data_4bits
);assign data_4bits = data_6bits; //直接赋值即可,工具会自动截位
//等价于下面的语句
//assign data_4bits = data_6bits[3:0];endmodule
用上面的TB测试就行,无符号数的测试结果如下:

有符号数的测试结果如下:

可以看到当输入大于4bits能表示的最大值后,就会回到最小值重新开始,相当于截掉了高位。
4、总结
- Saturate相当于溢出时,将结果保留在最大值或最小值;而Wrap则是溢出时重新绕回到起点。
- 相对来说Saturate损失的精度比较小,结果较为准确,但是消耗的硬件资源比Wrap方式要多;Wrap不需要消耗硬件资源,因为它实际上相当于截掉高位,等于是没有什么处理,精度损失大,结果不太准确(尤其是有符号数的Wrap),只适用于特定场合。