详解LLMOps,将DevOps用于大语言模型开发
大家好,在机器学习领域,随着技术的不断发展,将大型语言模型(LLMs)集成到商业产品中已成为一种趋势,同时也带来了许多挑战。为了有效应对这些挑战,数据科学家们转向了一种新型的DevOps实践LLM-OPS,专为大型语言模型的开发和维护而设计。
本文将介绍LLM-OPS的核心思想,并分析这一策略如何帮助数据科学家更高效地运用DevOps的优秀实践,从而在语言模型的开发和部署过程中,提升工作效率和成果的质量。
1.LLM-OPS:大型语言模型的DevOps范式
大型语言模型(LLM)在原型设计阶段展现出了强大的性能,然而其开发过程却颇具挑战性,涉及数据采集、模型调优、部署实施以及持续监控等多个复杂环节。
LLM-OPS提供了解决方案,它全面覆盖了从初步实验、模型迭代、部署实施到持续改进的每一个阶段。LLM-OPS融合了DevOps的优秀实践,为数据科学家们构建起了一个结构化的框架,帮助高效管理和解决开发过程中的复杂问题。
2.DevOps最佳实践在LLM-OPS中的应用
基于DevOps的核心理念,深入分析构筑LLM-OPS基础的重要方法论。从利用Git Flow促进模型开发的协作流程,到通过基础设施即代码(IaC)实现部署环境的一致性保障,逐一审视这些实践如何提升大型语言模型(LLM)部署的效率与稳定性。
2.1 模型开发的Git Flow
LLM-OPS 采用 Git Flow,为数据科学家提供了一套高效的代码管理和版本控制机制。借助明确定义的分支策略和版本管理流程,模型的开发过程变得更加有序、透明,增强了团队协作的效率和追踪性。
2.2 基础设施即代码(IaC)
LLM-OPS鼓励使用“基础设施即代码”,使数据科学家能够以编程方式定义和管理基础设施配置。这种方式保障了不同环境下配置的一致性,降低了部署过程中的风险,提升部署的稳定性和可靠性。
2.3 零信任安全
在LLM-OPS中,安全至关重要。采用零信任安全模型能够确保所有组件和交互都经过验证,增强了LLM部署的整体安全性。
2.4 不可变工件
LLM-OPS强调生成不可变的工件,即模型及其配置的固定版本。这种做法保障了模型的可复现性和操作的透明度,对于满足合规要求和进行审计审查具有重大意义。通过不可变工件,每一次部署都可以精确追溯到源代码和配置,确保了模型运行的一致性和可信度。
3.LLM-OPS相关问题
接下来,一起深入了解LLM-OPS如何运用DevOps的最佳实践来解决数据科学家面临的核心问题。
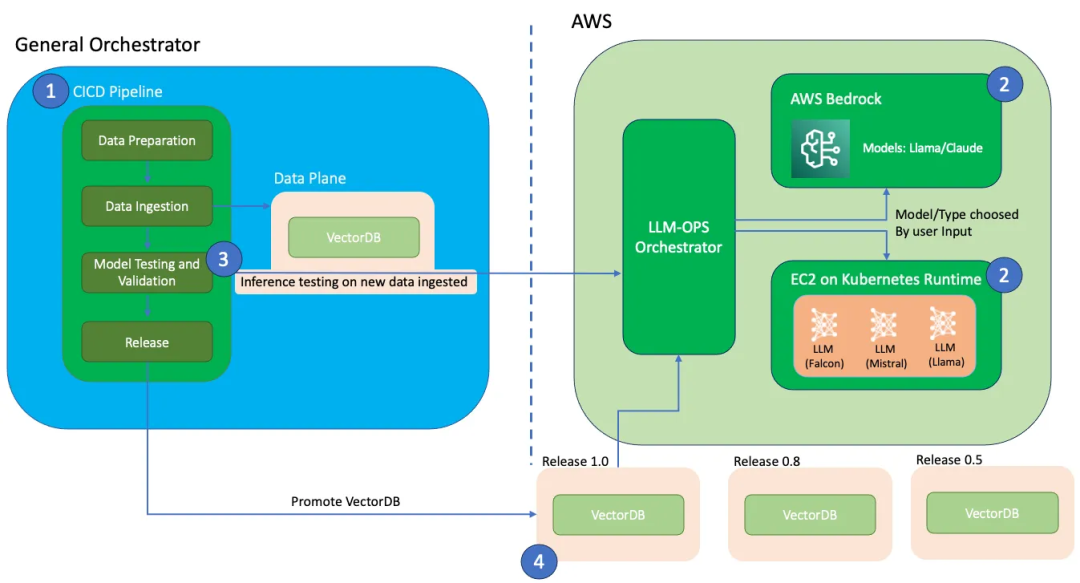
使用DevOps的LLM上下文学习
3.1 如何构建模型
在持续集成/持续部署(CI/CD)的流程中,LLM-OPS为数据科学家提供了一套简化且自动化的模型构建和部署方案。通过采用Git Flow,LLM-OPS实现了精准的版本控制和团队协作,使多位数据科学家能够无障碍地共同开发项目。同时,基础设施即代码(IaC)的实践确保了在不同环境下基础设施的配置都能保持一致性。此外,LLM-OPS的自动化流程精心设计,涵盖了数据采集、模型微调和部署等关键步骤,极大地简化了数据科学家构建高效模型的整个过程。
3.2. 模型在哪里运行
LLM-OPS赋予数据科学家在选择模型类型和架构方面更大的灵活性,以适配其特定的系统和自动化平台。借助DevOps实践,如容器化和编排技术,LLM-OPS实现了在不同环境中一致且可扩展的部署流程。无论是本地环境、云服务还是混合架构,LLM-OPS都能保障模型与运行环境的完美融合。
上图以AWS为例,展示了在AWS Bedrock或EC2实例上部署LLM模型的多样化选择。这不仅体现了LLM-OPS的灵活性,也突显了其在不同部署场景下的适应性和便捷性。
3.3. 如何测试模型
通过LLM-OPS,大型语言模型的测试变得更加系统化和精确。当VectorDB的数据摄取和配置工作完成后,自动化流程便开始提供全面的测试数据。这些数据包括详尽的性能指标和深入的分析洞察,赋予数据科学家进行细致测试的能力,从而验证模型的性能表现,并据此做出模型是否准备就绪投入部署的明智决策。
3.4. 如何运行VectorDB和访问应用程序
选择合适的VectorDB类型并制定有效的数据摄取策略,对于提升模型的准确性和性能很关键,尤其是在进行上下文学习时。VectorDB能够根据不同的应用程序和需求,在多种数据库环境中灵活部署。例如,对于在EC2上使用ChromaDB进行本地推理的模型,可以将其部署在Kubernetes Pod中,以适应不同的应用场景,并确保与模型训练过程的紧密集成。
此外,数据科学家拥有对模型进行微调的灵活性,这在必要时可以进一步提升模型针对特定任务的性能表现。这种灵活性和可定制性,使得VectorDB成为支持数据科学家工作的强大工具。
4.总结
在当今快速发展的语言模型领域,LLM-OPS代表了一项重要的技术突破,它架起了数据科学与DevOps之间的桥梁。通过整合Git Flow、基础设施即代码(IaC)、零信任安全框架和不可变工件等先进实践,LLM-OPS极大地提升了数据科学家在开发大型语言模型(LLM)时的效率,帮助顺利应对各种挑战。这些综合能力不仅推动了生成式AI技术在众多应用程序中的深度融合,也为未来的技术创新奠定了坚实基础。
展望未来,LLM-OPS不仅预示着最前沿的语言模型技术与弹性DevOps实践的结合,更为大型语言模型的开发和应用开辟了无限新可能,引领我们进入一个充满创新和机遇的新时代。