【缓存常见问题】
在使用缓存时特别是在高并发场景下会遇到很多问题,常用的问题有缓存穿透、缓存击穿、缓存雪崩以及缓存一致性问题。
1、缓存穿透
首先,什么是缓存穿透呢?
缓存穿透是指请求一个不存在的数据,缓存层和数据库层都没有这个数据,这种请求会穿透缓存直接到数据库进行查询。它通常发生在一些恶意用户可能故意发起不存在的请求,试图让系统陷入这种情况,以耗尽数据库连接资源或者造成性能问题。

解决方案
增加校验机制
例如:我们规定执行查询语句时,id必须是长整型而且是固定长度的格式,如果请求的id不符合则不再查询数据库。这种方案可以解决一部分的问题,还是有一定的可行性的。
缓存一个空值或者特殊值
在查询数据库的时候,发现数据不存在,此时我们依旧进行缓存,而不是直接返回。在这个时候我们可以缓存一个特殊值或者空值,避免下次请求再去访问数据库,从而避免缓存穿透。
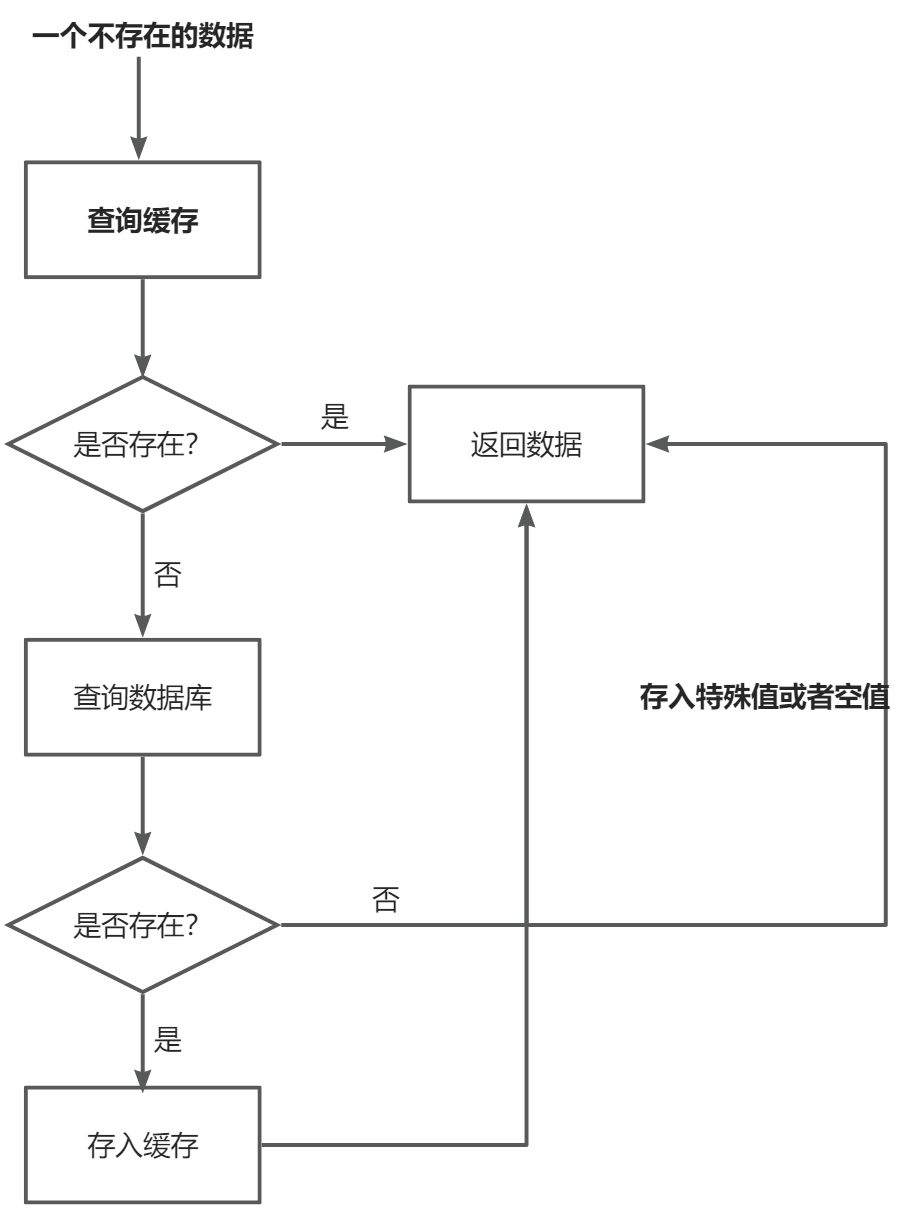
使用布隆过滤器
后续更新。。。
2、缓存击穿
首先缓存击穿是什么呢?
缓存击穿发生在访问热点数据,大量请求访问同一个热点数据,当热点数据失效后同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用。前提是有大量的并发。
比如某手机新品发布,当缓存失效时有大量并发到来导致同时去访问数据库。
解决方案
使用锁
单体架构下(单进程内)可以使用同步锁控制查询数据库的代码,只允许有一个线程去查询数据库,查询得到数据库存入缓存。
synchronized(obj){//查询数据库//存入缓存
}分布式架构下(多个进程之间)可以使用分布式锁进行控制。
// 获取分布式锁对象
RLock lock = redisson.getLock("myLock");
try {// 尝试加锁,最多等待99秒,加锁后自动解锁时间为30秒boolean isLocked = lock.tryLock(99, 30, java.util.concurrent.TimeUnit.SECONDS);if (isLocked) {//查询数据库//存入缓存} else {System.out.println("获取锁失败,可能有其他线程持有锁");}
} catch (InterruptedException e) {e.printStackTrace();
} finally {// 释放锁lock.unlock();System.out.println("释放锁...");
}此处分布式锁的实现方式有多种,大家可自行了解,我这里使用的是redisson
缓存预热
- 分为提前预热、定时预热。
- 提前预热就是提前写入缓存。
- 定时预热是使用定时程序去更新缓存。
热点数据不过期
可以由后台程序提前将热点数据加入缓存,缓存过期时间不过期,由后台程序做好缓存同步。
热点数据查询降级处理
对热点数据查询定义单独的接口,当缓存中不存在时走降级方法避免查询数据库。
3、缓存雪崩
什么是缓存雪崩呢?
缓存雪崩是缓存中大量key失效后当高并发到来时导致大量请求到数据库,瞬间耗尽数据库资源,导致数据库无法使用。
例如对不同的几类信息设置相同的过期时间,在大量请求第一次查询这些信息时,会写入缓存当中,当过期时间一到,就会有大量的信息访问数据库,从而引发雪崩问题。
解决方案
对同一类型信息的key设置不同的过期时间
通常对一类信息的key设置的过期时间是相同的,这里可以在原有固定时间的基础上加上一个随机时间使它们的过期时间都不相同。
例如:
@Beanpublic RedisCacheManager cacheManagerOneDay(RedisConnectionFactory connectionFactory) {int randomNum = new Random().nextInt(9999);RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()//过期时间为基础时间加随机数.entryTtl(Duration.ofSeconds(48 * 60 * 60L + randomNum)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(JACKSON_SERIALIZER));return RedisCacheManager.builder(connectionFactory).cacheDefaults(config).transactionAware().build();}
使用锁进行控制
思路同缓存击穿。
缓存定时预热
不用等到请求到来再去查询数据库存入缓存,可以提前将数据存入缓存。使用缓存预热机制通常有专门的后台程序去将数据库的数据同步到缓存。
4、缓存数据不一致问题
什么数缓存数据不一致呢?
缓存不一致问题是指当发生数据变更后该数据在数据库和缓存中是不一致的,此时查询缓存得到的并不是与数据库一致的数据。
经典案例:双写不一致
解决方案
使用分布式锁
延迟双删
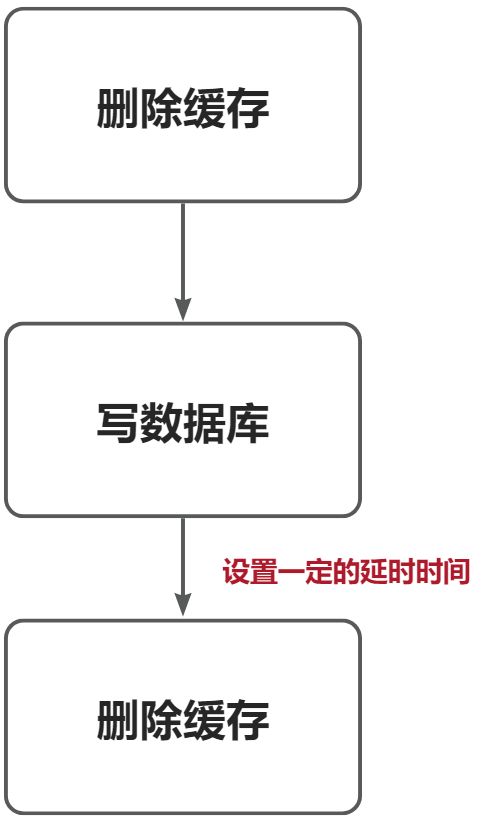
延迟多长时间呢?
主数据向从数据库同步的时间间隔,如果延迟时间设置不合理也会导致数据不一致。
使用canal+mq的方式
延迟双删的目的也是为了保证最终一致性,即允许缓存短暂不一致,最终保证一致性。
保证最终一致性的方案有很多,比如:通过MQ、Canal、定时任务都可以实现。
Canal是一个数据同步工具,读取MySQL的binlog日志拿到更新的数据,再通过MQ发送给异步同步程序,最终由异步同步程序写到redis。此方案适用于对数据实时性有一定要求的场景。
通过Canal加MQ异步任务方式流程如下:
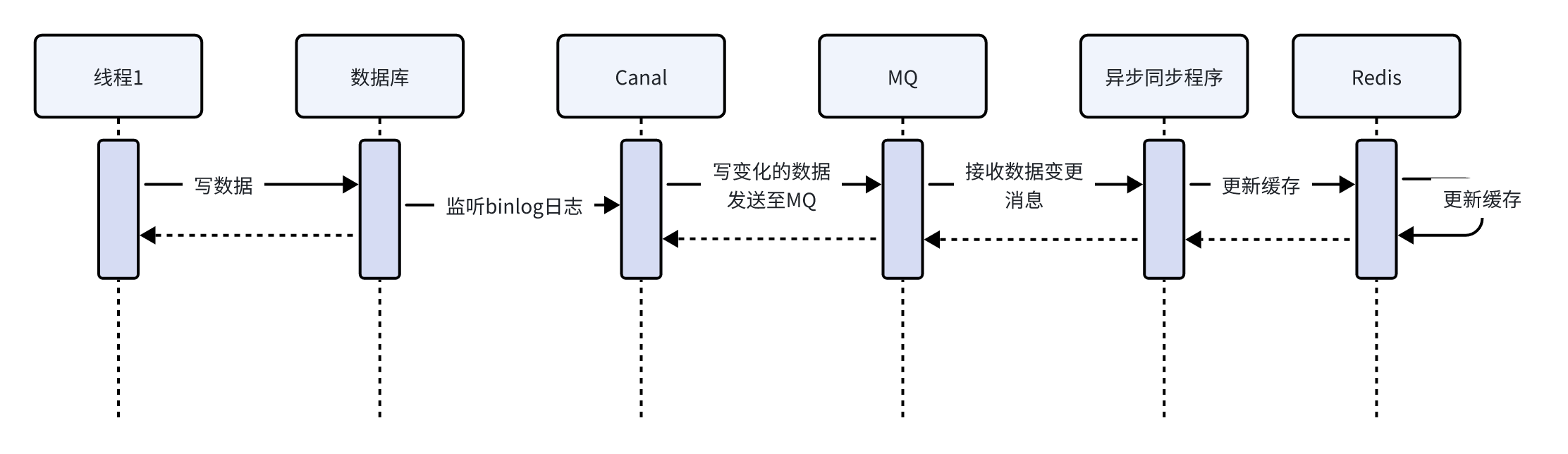
流程如下:
线程1写数据库
canal读取binlog日志,将数据变化日志写入mq
同步程序监听mq接收到数据变化的消息
同步程序解析消息内容写入redis,写入redis成功正常消费完成,消息从mq删除。
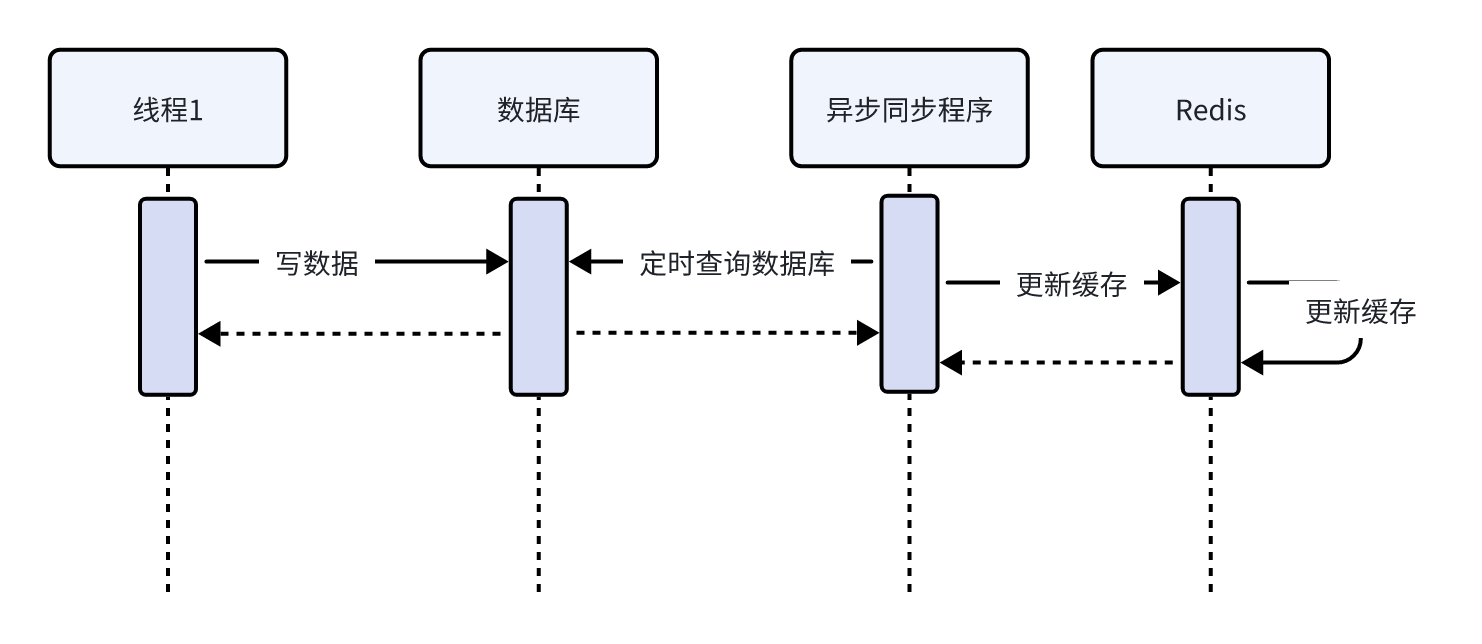
定时任务方式流程如下:
专门启动一个数据同步任务定时读取数据同步到redis,此方式适用于对数据实时性要求不强更新不频繁的数据。