头歌-机器学习 第11次实验 softmax回归
第1关:softmax回归原理
任务描述
本关任务:使用Python实现softmax函数。
相关知识
为了完成本关任务,你需要掌握:1.softmax回归原理,2.softmax函数。
softmax回归原理
与逻辑回归一样,softmax回归同样是一个分类算法,不过它是一个多分类的算法,我们的数据有多少个特征,则有多少个输入,有多少个类别,它就有多少个输出。
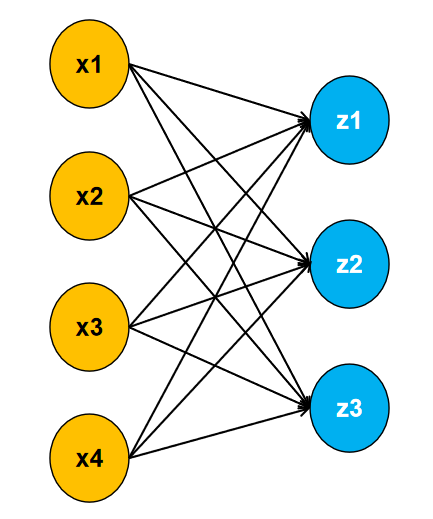
如上图,可以看出我们的数据有四个特征,三个类别。每个输入与输出都有一个权重相连接,且每个输出都有一个对应的偏置。具体公式如下:
z1=x1w11+x2w12+x3w13+x4w14+b1
z2=x1w21+x2w22+x3w23+x4w24+b2
z3=x1w31+x2w32+x3w33+x4w34+b3
输出z1,z2,z3值的大小,代表属于每个类别的可能性。如:z1=1,z2=10,z3=100表示样本预测为z3这个类别。 然而,直接将得到的输出作为判断样本属于某个类别的可能性存在不少的弊端。如,你得到一个输出为10,你可能觉得他属于这个类别的可能性很大,但另外两个输出的值都为1000,这个时候表示是这个类别的可能性反而非常小。所以,我们需要将输出统一到一个范围,如0到1之间。这个时候,如果有一个输出的值为0.9,那么你就可以非常确定,它属于这个类别了。
softmax函数
softmax函数公式如下:
y^i=∑i=1cexp(zi)exp((zi))
其中,i表示第i个类别,c为总类别数。由公式可知:
0≤y^≤0
i=1∑cy^=1
这样就可以将输出的值转换到0到1之间,且总和为1。每个类别对应的输出值可以当做样本为这个类别的概率。对于单个样本,假如一共有0,1,2三个类别,对应的输出为[0.2,0.3,0.5]则最后判断为2这个类别。
编程要求
根据提示,在右侧编辑器补充Python代码,实现softmax函数,底层代码会调用你实现的softmax函数来进行测试。
测试说明
程序会调用你实现的方法对随机生成的数据进行测试,若结果正确则视为通关,否则输出使用你方法后返回的数据。
#encoding=utf8
import numpy as npdef softmax(x):'''input:x(ndarray):输入数据,shape=(m,n)output:y(ndarray):经过softmax函数后的输出shape=(m,n)'''# 确保x是一个二维数组assert len(x.shape) == 2# 对每一行求最大值row_max = np.max(x, axis=1)# 对每个元素减去所在行的最大值x -= row_max.reshape((-1, 1))# 计算指数函数exp_x = np.exp(x)# 对每一行求和row_sum = np.sum(exp_x, axis=1)# 除以所在行的总和y = exp_x / row_sum.reshape((-1, 1))return y第2关:softmax回归训练流程
任务描述
本关任务:使用python实现softmax回归算法,使用已知鸢尾花数据对模型进行训练,并对未知鸢尾花数据进行预测。
相关知识
为了完成本关任务,你需要掌握:1.softmax回归模型,2.softmax回归训练流程。
softmax回归模型
与逻辑回归一样,我们先对数据进行向量化:
X=(x0,x1,...,xn)
其中,x0等于1。且X形状为m行n+1列,m为样本个数,n为特征个数。
W=(w1,...,wc)
W形状为n+1行c列,c为总类别个数。
Z=XW
Z形状为m行c列。
Y^=softmax(Z)
同样的,Y^的形状为m行c列。第i行代表第i个样本为每个类别的概率。
对于每个样本,我们将其判定为输出中最大值对应的类别。
softmax回归训练流程
softmax回归训练流程同逻辑回归一样,首先得构造一个损失函数,再利用梯度下降方法最小化损失函数,从而达到更新参数的目的。具体流程如下:
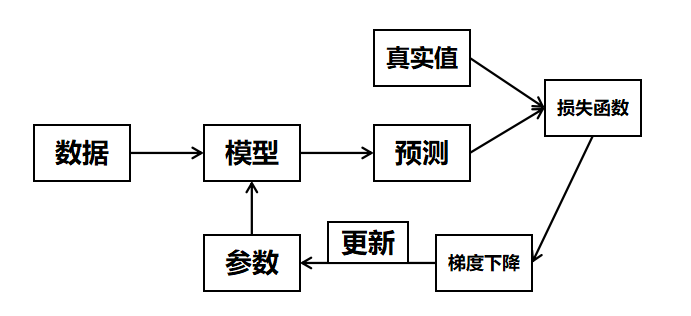
关于梯度下降详细内容请点击查看
softmax回归使用的损失函数为交叉熵损失函数,公式如下:
loss=m1i=1∑m−yilogy^i
其中,yi为onehot后的标签,y^i为预测值。同样的我们可以求得损失函数对参数的梯度为:
∂w∂loss=(y^−y)x
于是,在softmax回归中的梯度下降公式如下:
W=W−ηX.T(Y^−Y)
编程要求
根据提示,在右侧编辑器补充代码,实现softmax回归算法。
测试说明
程序会调用你实现的方法对模型进行训练,并对未知鸢尾花数据进行预测,正确率大于0.95则视为通关。
import numpy as np
from sklearn.preprocessing import OneHotEncoderdef softmax(x):'''input:x(ndarray):输入数据output:y(ndarray):经过softmax函数后的输出'''#********* Begin *********## 确保x是一个二维数组assert len(x.shape) == 2# 对每一行求最大值row_max = np.max(x, axis=1)# 对每个元素减去所在行的最大值x -= row_max.reshape((-1, 1))# 计算指数函数exp_x = np.exp(x)# 对每一行求和row_sum = np.sum(exp_x, axis=1)# 除以所在行的总和y = exp_x / row_sum.reshape((-1, 1))#********* End *********#return ydef softmax_reg(train_data,train_label,test_data,lr,max_iter):'''input:train_data(ndarray):训练数据train_label(ndarray):训练标签test_data(ndarray):测试数据lr(float):梯度下降中的学习率参数max_iter(int):训练轮数output:predict(ndarray):预测结果'''#********* Begin *********##将x0加入训练数据m,n = train_data.shapetrain_data = np.insert(train_data, 0, values=np.ones(m), axis=1)#转换为onehot标签enc = OneHotEncoder()train_label = enc.fit_transform(train_label.reshape(-1, 1)).toarray()#对w,z,y初始化w = np.zeros((n+1, train_label.shape[1]))z = np.dot(train_data, w)y = softmax(z)#利用梯度下降对模型进行训练for i in range(max_iter):# 计算梯度gradient = np.dot(train_data.T, (y - train_label))# 更新权重w -= lr * gradient# 重新计算z和yz = np.dot(train_data, w)y = softmax(z)#将x0加入测试数据m_test,n_test = test_data.shapetest_data = np.insert(test_data, 0, values=np.ones(m_test), axis=1)#进行预测predict = np.argmax(np.dot(test_data, w), axis=1)#********* End *********#return predict第3关:sklearn中的softmax回归
任务描述
本关任务:使用sklearn中的LogisticRegression类完成红酒分类任务。
相关知识
为了完成本关任务,你需要掌握如何使用sklearn提供的LogisticRegression类。
数据集介绍
数据集为一份红酒数据,一共有178个样本,每个样本有13个特征,3个类别,你需要自己根据这13个特征对红酒进行分类,部分数据如下图:

数据获取代码:
import pandas as pddata_frame = pd.read_csv('./step3/dataset.csv', header=0)
LogisticRegression
LogisticRegression中将参数multi_class设为"multinomial"则表示使用softmax回归方法。 LogisticRegression的构造函数中有三个常用的参数可以设置:
solver:{'newton-cg' , 'lbfgs', 'sag', 'saga'}, 分别为几种优化算法。C:正则化系数的倒数,默认为1.0,越小代表正则化越强。max_iter:最大训练轮数,默认为100。
和 sklearn 中其他分类器一样,LogisticRegression类中的fit函数用于训练模型,fit函数有两个向量输入:
X:大小为 [样本数量,特征数量] 的ndarray,存放训练样本Y:值为整型,大小为 [样本数量] 的ndarray,存放训练样本的分类标签
LogisticRegression类中的predict函数用于预测,返回预测标签,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本
LogisticRegression的使用代码如下:
softmax_reg = LogisticRegression(multi_class="multinomial")softmax_reg.fit(X_train, Y_train)result = softmax_reg.predict(X_test)
编程要求
根据提示,在右侧编辑器补充代码,利用sklearn实现softmax回归。
测试说明
程序会调用你实现的方法对红酒数据进行分类,正确率大于0.95则视为通关。
#encoding=utf8
from sklearn.linear_model import LogisticRegression
def softmax_reg(train_data,train_label,test_data):'''input:train_data(ndarray):训练数据train_label(ndarray):训练标签test_data(ndarray):测试数据output:predict(ndarray):预测结果'''#********* Begin *********#clf = LogisticRegression(C=0.99,solver='lbfgs',multi_class='multinomial',max_iter=200)clf.fit(train_data,train_label)predict = clf.predict(test_data)#********* End *********#return predict