Clickhouse数据去重
1. Hive去重
先以两个简单的sql启发我们的话题
select count(distinct id)from order_combine;select count(id)
from (select id from order_combine group by id
) t;
从执行日志当中我们可以看到二者的差异(只摘取关键部分)
# distinct
+ Stage-Stage-1:Map: 396 Reduce: 1 ...Time taken: 200.192 seconds#group byStage-Stage-1: Map: 396 Reduce: 457 ...Time taken: 87.191 seconds
二者关键的区别就在于使用distinct会将id都shuffle到一个reducer里面,当数据量大了之后,不可避免的就会出现数据倾斜。
group by在reducer阶段会将数据分布到多台机器上执行,在处理大数据时在执行性能上自然相比于distinct提高很多。
其实一般面试中,这种程度的回答会考量到MapReduce阶段数据的分区分组以及流向是否真正理解。
但是我们今天的主题主要是去重,写到这里就此打住很显然是不行的。
让我们换个角度思考一下
针对一个常用的order表去重就需要消耗87s的时间,如果我们在日常工作中经常需要针对order表进行数据分析,可想而知,这样的速度是难以忍受的。
老兵也常常就遇到这样的问题,两年前公司就开始慢慢的用Spark引擎替换Hive,在速度上加快了很多,但是随着业务的发展,Spark的实时查询能力还是显得有些力不从心,在去重方面的性能自然不必多说。
能不能找到一个方案让去重更快?
说到这里,ClickHouse就呼之欲出了。接下来会详细介绍ClickHouse的主要原理以及他是如何去重的。
2. Clickhouse
ClickHouse 是 Yandex(俄罗斯最大的搜索引擎)开源的一个用于实时数据分析的基于列存储的数据库。
ClickHouse的性能超过了目前市场上可比的面向列的 DBMS,每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。
2.1 MergeTree存储结构
说得这么神乎其神,很多人可能会有疑问,ClickHouse真的有这么强大吗?
要了解Clickhouse的强大,首先要提的绝对是合并树MergeTree引擎,因为Clickhouse的核心原理就是依赖于它,而所有的其他引擎都是基于它来实现的。
我将以MergeTree为切入点揭开ClickHouse神秘面纱。
从图中可以看出,一张数据表的完整物理结构分为3个层级,依次是数据表目录、分区目录及各分区下具体的数据文件。接下来逐一介绍它们的作用。

partition:分区目录,属于相同分区的数据最终会被合并到同一个分区目录,而不同分区的数据,永远不会被合并到一起。checksums.txt:校验文件,使用二进制格式存储。它保存了各类文件(primary.idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。columns.txt:列信息文件,使用明文格式存储。用于存储此数据文件下的列字段信息。count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数。所以,利用Clickhouse我们经常算的分区总行数又何必反复扫描计数。primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引。借助稀疏索引有效减少数据扫描范围,加快查询速度。[Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式。由于MergeTree采用列式存储,所以每一个列都拥有独立的.bin数据文件,并以列字段名称命名(例如impdate.bin,age.bin等)。[Column].mrk:列字段标记文件,使用二进制格式存储。用以保存.bin数据的偏移量。因此,MergeTree就是通过标记文件建立了primary.idx稀疏索引与.bin数据文件之间的映射关系。[Column].mrk2:如果使用了自使用大小的索引间隔,则标记文件会以.mrk2命名。partition.dat与minmax_[Column].id:如果使用了分区键,例如Parition By ImpTime,则会额外生产partition.dat与minmax索引文件,它们均用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。在这些分区索引的作用下,进行数据查询能够快速跳过不必要的数据分区目录,从而减少最终需要扫描的数据范围。skp_idx_[Column].idx与skp_idx_[Column].mrk:如果在建表时声明了二级索引就会额外生成相应的二级索引与标记文件,它们同样也使用二进制存储。显然,最终目的与一级索引相同,都是为了进一步减少所需扫描的数据范围。
反问一个问题,为什么Clickhouse的引擎叫MergeTree呢?
搞懂了它的数据分区相信你们得到答案。我将详细介绍一下Clickhouse是如何进行数据分区的。
2.2 MergeTree数据分区
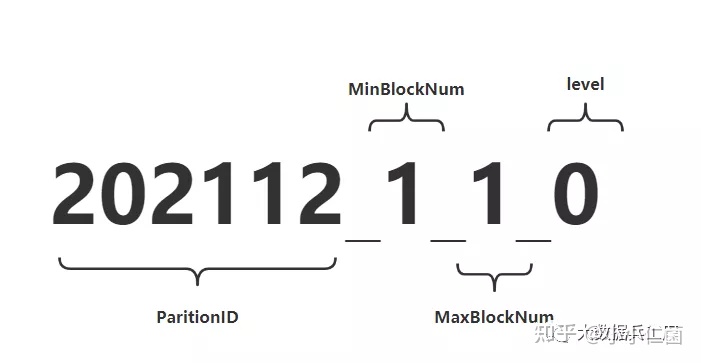
如果进入数据表所在的磁盘目录后,会发现MergeTree分区目录的完整物理名称并不是只有id而已,在id之后还跟着一串奇怪的数字,例如202112_1_1_0。这些数字代码什么呢?
对于MergeTree而言,最核心的特点就是分区目录的合并过程,想要搞清楚过程,其实从分区目录的命名中就能解读出它的合并逻辑。如下一个完整分区目录的命名公式:
PartitionID_MinBlockNum_MaxBlockNum_Level
我这里画了一张图来便于大家理解,并在下面附加对它的解释。
2.2.1 命名规则
PartitionID: 分区ID**MinBlockNum和MaxBlockNum:顾名思义,最小数据块编号和最大数据块编号。这里的BlockNum是一个整型的自增长编号,从1开始,每新创建一个分区目录时,计数n就会累加1。对于一个新的分区目录而言,MinBlockNum与MaxBlockNum取值一样,等同于n,例如202112_1_1_0、202112_2_2_0以此类推。Level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄,数值越高,年龄越大。
2.2.2 分区目录的合并过程
MergeTree的分区目录当然和传统意义上的其他数据库有所不同。其中最大的差别是在其他数据库的设计中,追加数据后目录自身不会变化,只是在相同分区目录中追加新的数据文件,比如hive存储目录就是如此。
而MergeTree不同,随着每一批数据的写入,MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。
在之后某个时刻,Clickhouse会通过后台任务再将数据相同分区的多个目录合并成一个新的目录。已经存在的旧分区不会立即删除,而是在之后的某个时刻被后台任务删除(默认8分钟)。新目录的合并方式遵循以下规则:
MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。Level:取同一分区内最大的Level值并加一。
2.2.3 合并目录名称的变化过程
照例我这里先上一张图让大家直观的看一下合并目录名称的变化过程

按照上图所示,测试表按日期字段格式分区,即PARTITION BY toYTYYYMM(EvenT-Time)。假设在T0时刻,首先分3批插入如上3条数据,按照目录规则,上述代码会创建3个分区目录。分区目录的名称由PartitionID、MinBlockNum、MaxBlockNum和Level组成,3个分区目录ID依次是202111,202111和202112。
而对于每个新建的分区目录而言,它们的MinBlock- Num和MaxBlockNum取值相同,均来源于表内全局自增长的BlockNum。
- BlockNum初始为1,每次新建目录后累计加1。所以,3个分区目录的MinBlockNum和MaxBlockNum依次为
0_0,1_1,2_2。最后就是Level层级,每个新建的分区目录初始Level都是0。 - 假设在T1时刻,MergeTree的合并动作开始了,属于同一分区的目录就会发生合并,这个时候
202111_1_1_0和2021_2_2_0如上图所示完成合并动作之后形成一个新的分区202111_1_2_1。 - 其中MinBlockNum取同一分区内所有目录中
最小的MinBlockNum值所以是1。MaxBlockNum取同一分区内所有目录最大的MaxBlockNum值,也就是2。此时Level取同一分区内最大的Level值加1,即1。而后的合并就是重复上述的过程而已。
至此,大家已经知道了分区ID、目录命名和目录合并的相关规则。相信开始对Clickhouse有一些感觉了。
2.3 稀疏索引
如果仅仅只是分区的优化,详细大家还是会对Clickhouse持怀疑态度。其实相比于传统基于HDFS的OLAP引擎,clickhouse不仅有基于分区的过滤,还有基于列级别的稀疏索引,这样在进行条件查询的时候可以过滤到很多不需要扫描的块,这样对提升查询速度是很有帮助的。

2.3.1 稀疏索引与稠密索引
简单来说,在稠密索引中的每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中,每一行索引标记对应的是一段数据,而不是一行。
如果把MergeTree比作一本书,那么稀疏索引就好比这本书的一级章节目录。
稀疏索引的优势是显而易见的,他仅需要少量的索引标记就可以记录大量的区间位置信息,且数据量越大优势约为明显。以默认的索引粒度(8192)为例,只需要12208行索引就可以为1亿行的数据记录提供索引。由于稀疏索引占用空间小,索引primary.idx内的索引数据常驻内存,取用速度自然极快。
我们以一张图看下索引数据写入primary.idx又是如何进行的

上图不难理解,我们把AccountId作为我们的主键字段,Clickhouse每间隔8192行数据会取一次AccountId作为索引值,索引数据最终被写入primary.idx文件进行保存。
如上的编号0、编号1、编号2是按照字段顺序紧密排序在一起的,比如1112345689,因此我们可以看出MergeTree对于稀疏索引的存储还是非常紧凑的。
不仅此处,clickhouse中很多数据结构都被设计的非常紧凑。比如其使用位读取代替专门的标志位或状态码,不浪费哪怕一个字段的空间。以小见大,这也是为什么Clickhouse为何性能如此出众的深层原因之一。
说到这里,索引的查询过程就是我们不可回避的问题了。
了解索引的查询过程,首先需要了解什么是MarkRange
MarkRange在Clickhouse是用于定义标记区间的对象。通过先前的介绍可知,MergeTree按照自定义的间隔粒度,将一段完整的数据划分成了多个小的间隔数据段,一个具体的数据段即是一个MarkRange。MarkRange与索引编号对应,使用start和end两个属性表示其区间范围。

整个索引的查询过程可以大致分为3个步骤:
- 生成查询条件区间:首先,将查询条件转换成条件区间。如:wehre AccountId = 'U003'会转换成['U003','U003']。
- 递归交集判断:以递归的方式,依次对MarkRange的数值区间与条件区间做交集判断。
- 如果不存在交集,直接
剪枝。 - 如果存在交集,判断MarkRange步长是否大于8(end - start) ,如果大于则进一步拆分成8个子区间(
merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续递归交集判断。 - 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
- 合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并他们的范围。
- 如果不存在交集,直接
Clickhouse同样支持二级索引,目的也是与一级索引一样,帮助查询时减少数据扫描的范围。
当然,Clickhouse在设计上还做了很多优化来提高我们的数据处理能力以及数据存储能力。篇幅有限,后面再对它们进行详细展开,现在可以大致了解一下。
2.4 其他特性
1)CPP
clickhouse是CPP编写的,代码中大量使用了CPP最新的特性来对查询进行加速。优秀的代码,对性能的极致追求。
2)列存储
最小化数据扫描范围。更好的进行数据压缩。
3)压缩数据块
有效减少数据大小,降低存储空间并加速数据传输效率。在具体读取某一列数据时,首先需要将压缩数据加载到内存并解压,这样才能进行后续的数据处理。通过压缩数据块,可以在不读取整个数据文件的情况下将读取的粒度降低到压缩数据级别,从而进一步缩小了数据读取的范围。
4)SIMD
Clickhouse利用CPU的SIMD指令来实现向量化执行。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式 ( 其他的还有指令级并行和线程级并行 )。
原理: 在CPU寄存器层面实现数据的并行操作。
简单来说就是一个指令能够同时处理多个数据。所以利用CPU向量化执行的特性,对于程序的性能提升意义非凡。
数据分片与分布式查询Clickhouse作为一款在线分析处理查询的大数据引擎,自然少不了集群部署、数据分片的能力。从而利用分布式查询横向扩展提高数据查询速度。
光说不练假把式,我们最后就来看看基于Clickhouse做去重究竟有多快~
3. ClickHouse去重优化
下面是我针对12亿数据做的测试,帮大家直观的感受下Clickhouse的速度。(涉及保密信息会被msk-手动狗头)
3.1 数据查询(非去重)
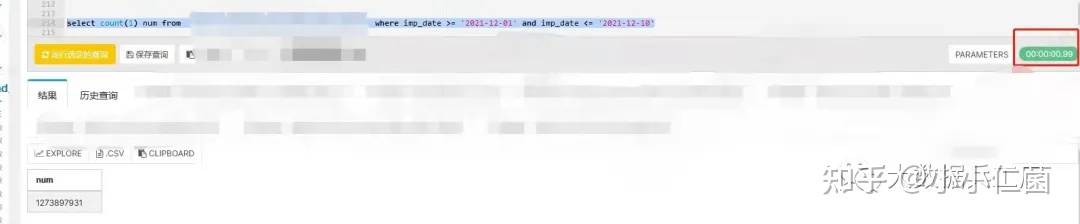
select count(1) num
from a
whereimp_date >= '2021-12-01' and imp_date <= '2021-12-10'
3.2 数据查询(去重)
下面看看Clickhouse普通去重的写法:
select count(distinct dt_accountid ) user_num
from awhere imp_date >= '2021-12-01' and imp_date <= '2021-12-10'
从两张图中的红框部分我们能得到两个信息:
- 基于
12亿数据做count聚合查询总数可以秒级别内得到响应,这与我前面提高的数据分区目录存储和索引密不可分。 - 基于12亿数据数据去重,响应时间在
7s左右
看到这样的测试结果,相信很多之前没有接触过Clickhouse的人会大吃一惊。因为它相比于spark、hive简直是太快了。其实它在去重上的能力还远不止于此。
3.3 数据查询(Bitmap去重)
下面我们使用Clihouse的Bitmap机制进行去重:

select groupBitmap(toUInt64OrZero (dt_accountid)) user_num
from a
where imp_date >= '2021-12-01' and imp_date <= '2021-12-10'
从图中我们会惊奇的发现,换了一个写法,Clickhouse基于Bitmap去重竟然将去重速度又提高了一个量级。
这就是我们经常在处理大数据去重为了加快速度和节省内存时做的终极优化: 利用Bitmap。
为什么用count(distinct)跟groupBitmap两个函数差异如此之大呢我们有必要看下源码:
// count(distinct)
// HashSetTable
void merge(const Self & rhs){if (!this->hasZero() && rhs.hasZero()){this->setHasZero();++this->m_size;}for (size_t i = 0; i < rhs.grower.bufSize(); ++i)if (!rhs.buf[i].isZero(*this))this->insert(rhs.buf[i].getValue());}
// groupBitmap
// RoaringBitmapWithSmallSet
void merge(const RoaringBitmapWithSmallSet & r1){if (r1.isLarge()){if (isSmall())toLarge();*rb |= *r1.rb;}else{for (const auto & x : r1.small)add(x.getValue());}}
Bitmap原理
- 从上面的代码块我们可以很清楚地看到:
count(distinct)用到的uniqExact是使用一个hash表来合并聚合数据,利用hash表的唯一特性来精确去重,在10亿级别的for循环中十分耗时(gdb打印了rhs.grower.bufSize()的值为20亿,耗时2分钟左右)。 - 而
RoaringBitmapWithSmallSet的merge在高基维场景下只做了一次或运算,耗时基本可以忽略。大家如果还不了解HashSetTable和RoaringBitmap可以自行补上这些知识,这里暂且不展开来讲。
所以我们发现即便在Clickhouse这种场景下,不深入了解他的基本原理,我们对于同一个业务不同的实现性能也会差别极大。