使用ArrayList.removeAll(List list)导致的机器重启
背景
先说一下背景,博主所在的业务组有一个核心系统,需要同步两个不同数据源给过来的数据到redis中,但是每次同步之前需要过滤掉一部分数据,只存储剩下的数据。每次同步的数据与需要过滤掉的数据量级大概在0-100w的数据不等。
由于是两个数据源,虽然拿到数据后存数据的代码能共用,但是从数据源拿数据由于协议不同所以还是需要分开写,就安排了两位同事完成这个任务。
重启现象
项目上线大半年,线上运行一直很平稳,突然在某一天ops开始报警该系统的两台机器一直在重启,cpu也一直报警,线上cpu监控如下所示:

机器也处于不断重启中:
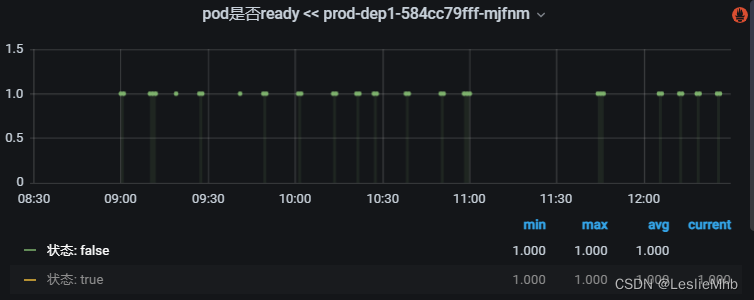
两台机器表现几乎一致,于是马上重启一台机器,同时联系ops运维同学帮助临时扩容机器,另外一台机器抓取一下当时的运行详情。直接用下面的火线图更明显:
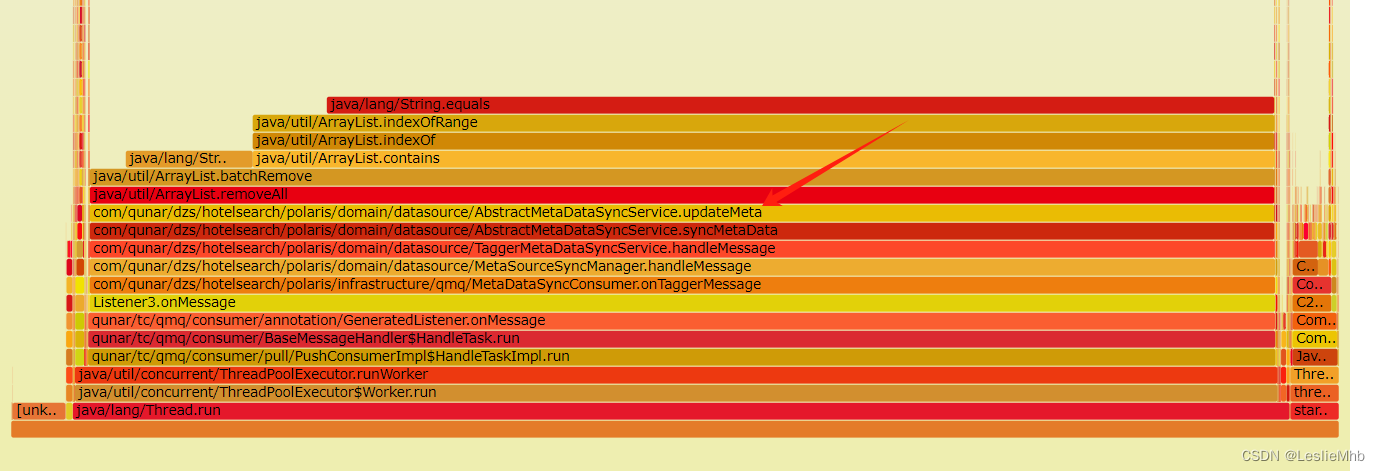
问题分析
可以看到几乎80%的cpu都在做一件事情:ArrayList.removeAll(),根据线程栈找到了线上的代码大致如下:
protected void updateMeta(String redisField, List<String> oldHotels, List<String> newHotels) {//1.diff两次数据涉及的酒店//2.从老数据中删除新数据oldHotels.removeAll(newHotels);
}可以看到其实cpu大部分的时间都在执行一行代码oldHotels.removeAll(newHotels),所以可以定位到问题所在。
前面提到我们同步数据其实是有两个数据源的,前面任务堵塞的数据源成为数据源1,另一个数据源称为数据源2,那么为什么数据源2没有阻塞呢?经过定位,发现关于数据源2更新数据的代码大致如下:
private List<String> calculateNeedDeleteHotelSeqByRedis(String tableName, Set<String> thisHotelSeqs) {List<String> saveHotelSeqs = queryHotelSeqs(STRING_OLD_SEQ_TABLE_PREFIX + tableName);if (CollectionUtils.isNotEmpty(saveHotelSeqs)) {// 删除diff数据saveHotelSeqs.removeAll(thisHotelSeqs);return saveHotelSeqs;}
其实两个方法要做的事情都是一样,只是各自的实现方式不一样,但是都有一个关键的步骤就是从新数据集合中批量删除掉老数据。第一个数据源调用的api是ArrayList.removeAll(List list),第二个数据源调用的api是ArrayList.removeAll(Set set),其实两个api都是同一个api,他的定义为:
//java.util.ArrayList#removeAllpublic boolean removeAll(Collection<?> c) {Objects.requireNonNull(c);return batchRemove(c, false);}所以,可以看出来其实区别就在于传参类型不同,接下来就需要深究为什么传参类型为List集合时会导致cpu上涨。
通过查询相关资料可以得知:在集合数据比较多的情况下, ArrayList.removeAll(Set)的速度远远高于ArrayList.removeAll(List)!从1百万数据中remove掉30万数据,前者需要0.031秒,后者需要1267秒!
结合以下类图:
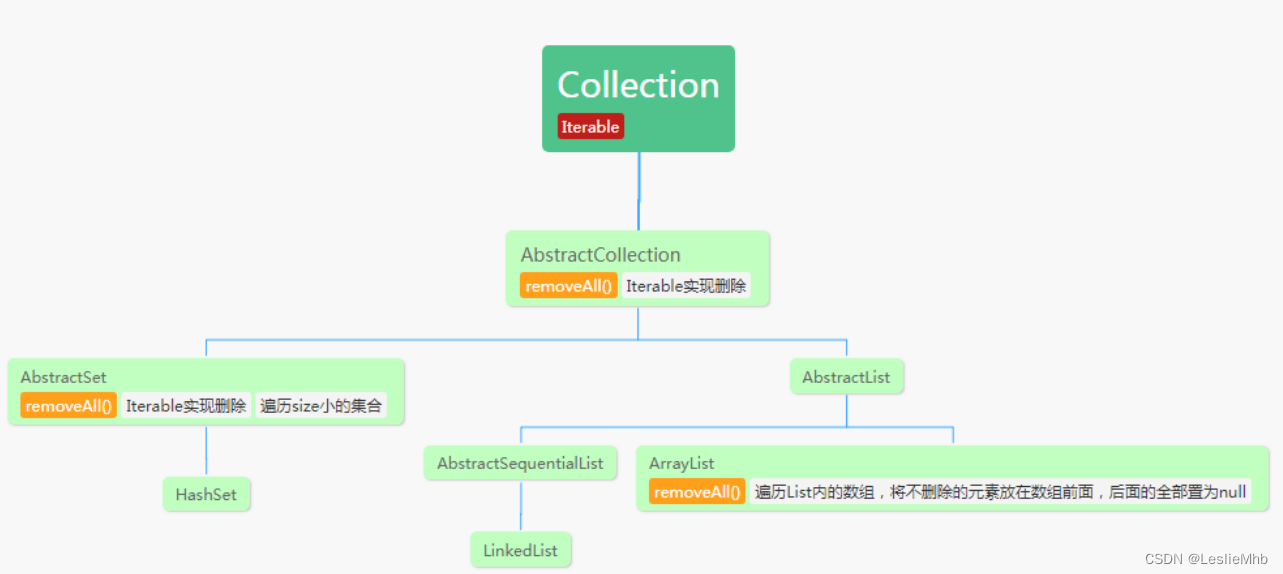
从图中可以看到,图中相关的集合类(HashSet、LinkedList、ArrayList),除了ArrayList自己实现了removeAll()方法外,其他两个集合都是借助父类(或超父类)的Iterator迭代器进行删除。接下来再来看一下ArrayList类的removeAll()方法的实现。
private boolean batchRemove(Collection<?> c, boolean complement) {final Object[] elementData = this.elementData;int r = 0, w = 0;boolean modified = false;try {for (; r < size; r++)if (c.contains(elementData[r]) == complement)elementData[w++] = elementData[r];} finally {// Preserve behavioral compatibility with AbstractCollection,// even if c.contains() throws.if (r != size) {System.arraycopy(elementData, r,elementData, w,size - r);w += size - r;}if (w != size) {// clear to let GC do its workfor (int i = w; i < size; i++)elementData[i] = null;modCount += size - w;size = w;modified = true;}}return modified;}从火线图中可以看出,主要是卡在执行contains()方法,而contains()方法则是调用入参自身的方法,因此需要对比的是HashSet.contains() vs ArrayList.contains()。
ArrayList.contains()
实现很简单,即调用
indexOf(),一个一个地遍历查找。最坏时间复杂度为O(总数据量)。
HashSet.contains()
我们知道,
HashSet的底层是HashMap,因此,实际也就是调用map.containKey()方法。
大家都知道,HashMap的查找速度非常快!因此,到这里,我们也就解释题目的问题。
解决方案
在数据量比较大的的情况下,使用arrayList.removeAll(subList)时,可以更改为:
- 将
subList封装为HashSet:arrayList.removeAll(new HashSet(subList)) - 将
arrayList改为LinkedList:new LinkedList(arrayList).removeAll(subList)
最终我们将数据源一的代码修改如下,解决问题:
protected void updateMeta(String redisField, List<String> oldHotels, List<String> newHotels) {//1.diff两次数据涉及的酒店//2.从老数据中删除新数据// 包装为set集合Set<String> newHotelSet = Sets.newHashSet(newHotels);oldHotels.removeAll(newHotels);
}