性能测试-数据库优化二(SQL的优化、数据库拆表、分表分区,读写分离、redis)
数据库优化
explain select
重点: type类型,rows行数,extra
SQL的优化
- 在写on语句时,将数据量小的表放左边,大表写右边
- where后面的条件尽可能用索引字段,复合索引时,最好按复合索引顺序写where条件
- where后面有in语句,in字段的索引,最好放复合索引的后面,因为in的字段索引可能会失效
- 模糊查询时,尽量用 常量开头,不要用%开头,用%开头查询索引将失效
- select * from table where col like ‘明确%’;
- 尽量不要使用 or,否则索引失效
- 尽量不要使用类型转换(显式、隐式),否则索引失效 如果主查询数据量大,则使用in;
- 如果子查询数据量大,则使用exists
- select * from table_1 where id in(数据量小);
- 查询哪些列,就根据哪些列group\order by,不然会产生一个临时表
- 写select,尽可能的不用 *
实际项目中sql的优化:
- 获取慢sql
- 并发时候是慢sql
- 单独执行就是慢sql
- 执行sql
- 简单分析
- 简单分析
- 复杂的sql(行数在几十行)
- 先梳理sql的业务
- 业务的梳理,可以拆解sql
- 复杂sql能用代码实现的,尽可能用代码来实现
- 先梳理sql的业务
数据库的优化
数据库库层面优化:
- 数据库的配置参数、
- 操作系统参数、
- 磁盘
数据库表层面优化
- 表的存储引擎
- 建表的时候字段数量及字段类型
- 建索引,一般情况下mysql表的索引,一张表不超过5个
- 建视图表
- 内存表,不磁盘上
- sql优化
数据库拆表
数据库表中数据,产品使用一段时间会后,某些表的数据量的数据量就可能很大。同时数据库对于产品正常非常重要,万一数据库有问题了,导致产品无法正常使用,数据库还需要备份。
备份:一般会备份到其他地方
- 冷备份:指定一个备份规则,满足规则的时候做备份。
- 如:凌晨一两点、产品用户使用率最低的时候。
- 热备份:几乎实时对数据库的数据变更进行备份。
- 读写分离、主从同步
读写分离、主从同步
读写分离
主从同步:数据库,至少是两个以上。多个数据库,一般是在不同的机器
读写分离:读数据和数据变更实在不同的数据库中。
读、写,哪个用主数据库,哪个用从数据库?-------思考
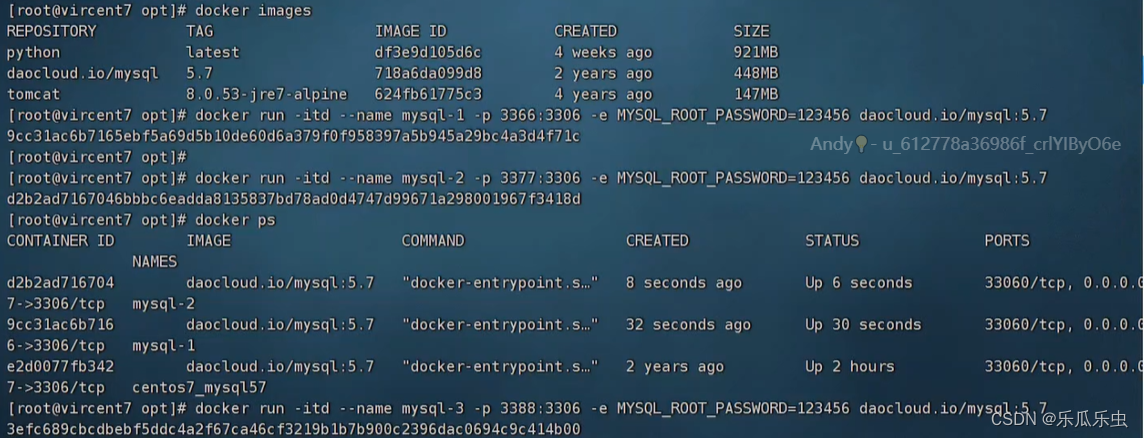
实操: 在一台机器中,用docker创建多个数据库 详细搭建教程看这里
docker run -itd --name mysql-1 -p 3366:3306 -e MYSQL_ROOT_PASSWORD=123456
mysql:5.7
docker run -itd --name mysql-2 -p 3377:3306 -e MYSQL_ROOT_PASSWORD=123456
mysql:5.7
docker run -itd --name mysql-3 -p 3388:3306 -e MYSQL_ROOT_PASSWORD=123456
mysql:5.7
 修改数据的配置文件,在配置文件中,设置数据库的服务id和日志同步文件格式,有多个数据库,数据 库的id不相同,id值越大,将来作为从数据库。
修改数据的配置文件,在配置文件中,设置数据库的服务id和日志同步文件格式,有多个数据库,数据 库的id不相同,id值越大,将来作为从数据库。
server-id=100
log-bin=mysql-bin登录准备作为从数据库的数据库,添加主数据库的信息,添加成功之后,从数据库才知道主数据库是哪 个?
CHANGE MASTER TO
MASTER_HOST='192.168.130.130',
MASTER_PORT=3366,
MASTER_USER='root',
MASTER_PASSWORD='123456';
START SLAVE;
show slave status;
看执行的结果 Slave_SQL_Running Slave_IO_Running的值为Yes。
Slave_IO_Running:意思是二进制文件同步正在运行。Yes,就会从主数据库自动同步数据库二进制 文件到从数据。No,就不会同步文件
Slave_SQL_Running:二进制日志回放,正在运行,执行sql,Yes,同步过来的文件,就会执行。No, 同步过来的文件,也不会执行。
数据同步,只能是主数据库同步给从数据库,不能反过来。
在主数据库做的任何操作,都可以同步给从数据库,从数据库的数据变动,是不能同步给其他从数据库和主数据库的
从数据库改了数据,主数据库中新增一条新数据,还是可以同步给从数据库的,但是如果主数据库改了从数据库相同的数据,导致了从数据库冲突,冲突之后导致所有数据都不能同步过来。只能解决冲突才能再次同步(删除对应的数据并不能解决冲突)
所以数据变更是在主数据库,获取数据是在从数据库。 从数据库是用来读数据,主数据库是用来写数据的。
主从同步
企业中项目,70%的性能问题,都会与数据库有关。
项目中,从数据库中获取数据的使用率,远远高于进行数据变更的。
实现数据库读写分离的话,那么,进行数据变更,获取数据,就可以从不同的数据库中获取。这样,获 取数据的性能会要更高一些。
主从同步,至少要有两个以上的数据库。主数据库,主要是做数据变更,从数据库,数据会自动从主数 据库同步过来。这样就可以保障主从数据库的数据一致。读的时候,使用从数据库数据,数据不会错,变更数据,使用主数据库,这样一旦数据发生变化,自动同步给从数据库,获取数据是从从数据 库中获取,所以从数据库的数据,也是变更之后的数据。
从数据库可以是多个。多个从数据库,可以配置为集群。项目中,jdbc的url地址,就配置数据库的集群地址,这样项目就可以实现从多个从数据库中获取数据。这样获取数据的性能就提升了。
使用主从同步,读写分离,在企业项目中,是比较常见的。使用之后,数据库的性能也是可以得到明显 的提升。
分表分区
-详细看这里
分表
分表:拆表垂直拆表,水平拆表
拆表拆出来的子表,都是真实的物理表,表中数据,是落在磁盘上的。每个表在磁盘上的文件变小,表 的性能就提升了。
- 垂直拆表:根据一定的策略,把表的列拆分。
- 策略:如,根据sql语句中,使用率高低
- 水平拆表:根据一定的策略,把表的行数量拆分
- 策略:如,根据id的尾号
合表:主表(是一张虚拟表,不再磁盘上)的存储引擎是MRG_MYISAM,子表存储引擎必须为MYISAM。 mysql数据库中InnoDB存储引擎,不支持合表
分区
数据库表的数据落入磁盘时,写入不同的磁盘分区上去。
可以是一张表,根据一定的策略,把满足策略的数据,写入到不同硬盘的分区上。
也可以是数据库中的多张表,不同的表写入到不同的硬盘分区上。
写到不同的硬盘,每个硬盘都有自己的IO,写到不同的硬盘,就可以使用不同硬盘的IO性能
分区可以把表数据,落到磁盘上的文件变小,同时也可以使用不同硬盘IO性能,所以数据库表 分区对性能提升是很大的。
但是这种方法在企业中相对主从同步用的少一些。
主要原因:
- 成本,做数据表的分区,一般要使用RAID磁盘矩阵
- 技术,RAID技术、数据库分区的技术、数据恢复技术
总结关系型数据库性能优化
1、数据库是一个软件,是安装在操作系统中
- 优化:操作系统优化(硬件、系统参数)、数据库自身参数优化
- 优化:主从同步
2、数据库的建库、建表
- 优化:建表的存储引擎、字段类型、字段数量、表索引,关联表、建视图
- 优化:分表分区
3、数据库的使用
- 优化:sql优化
- 优化:读写分离
4、补充:现在数据库越来越多,出现了分布式数据库。TiDB
非关系型数据库
是相对于关系型数据库而言的,关系型数据库,表与表之间是有关联关系的。非关系型数据库,就是说表与表之间,没有明确的关联关系。
关系型数据库,表是二维表,把数据进行了栅格化。但是非关系型数据库,没有对数据进行统一的 标准化的格式化。
关系型数据库,统一标准的sql语句,非关系型数据库,没有统一标准的sql,各个不同的非关系型数据 库,都有自己的独立的sql语句。
总体的情况是非关系型数据库,数据结构虽然没有关系型数据库那么清晰,但是性能和数据扩展性 要远远高于关系型数据库。
现在企业项目数据库,一般会选择:关系型数据库为主数据库,非关系型数据库为辅助数据库,这种 多数据库组合的方式。
在企业项目中,redis作为缓存数据库是最常见的。
因为:redis数据库,是一个内存数据库,它的数据是保存在内存中,但是它又有一个自动同步磁盘的机制,可以根据设定的配置项目,自动间隔一段时间把内存中的数据写入磁盘。redis数据库可以实 现缓存集群。
性能测试学习redis:
- 是内存数据库,性能是比较好的,至少它的性能比磁盘数据库的性能要高。
- 也会存在性能问题。------→性能测试经历中,有见过接口响应时间规律性忽高忽低,这种情况很 大概率就是redis性能问题
redis的安装与使用
redis的安装一
redis是6.x版本,这个版本要求GCC要大于5.3版本。
GCC是linux系统中,编译安装系统软件的必须的库,这个库linux中可以直接安装。centos7系统,默认直接安装的版本是4.8.5版本。来安装redis6.x版本会报错。
# centos7系统
# 安装gcc
yum install gcc* -y
# 可以使用 gcc -version 来查看gcc的版本
yum -y install centos-release-scl
# 可以使用 yum search devtoolset-* 来查看,当前系统可以安装的gcc的版本
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash
echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile安装redis
wget http://download.redis.io/releases/redis-6.0.8.tar.gz
tar -xzvf redis-6.0.8.tar.gz
cd redis-6.0.8
make
在当前这个路径下,redis.conf文件,就是redis的配置文件
在src路径下会有一些可执行的文件
使用 src/redis-server 启动了redis,但是,此时redis不是守护进程daemonize no 在redis默认情况下守护进程为no,不是守护进程
redis的安装二
安装的redis是6.x版本,gcc需要升级到5.3以上
- 升级gcc
- 解压redis包
配置项:
- protected-mode yes 默认是开启包含模式,如果开启了,用代码调用redis会报错,如果设置为 no,就可以不用密码连接redis
- daemonize yes 就是守护进程
使用 src/redis-cli 命令可以连接到redis的命令行模式
config get * 可以查看到所有的redis的配置信息
做性能测试,要懂得redis的安装、redis的配置,redis的使用要了解。
redis的使用
- redis有5种常用数据类型,以及这些类型是基本使用。
- string字符串类型 ----→ 值为string
- set 设置key和value,get获取key的值
- hash类型
- hmset key filed1 value1 flied2 value2 filed3 value3……
- hget key filedname
- list类型
- lpush key value1 value2 value3….. 往列表的左边插入数据
- lrange key start end 从列表的左边开始取值
- set集合 数据不会重复
- sadd key value1 value2
- smembers
- sorted set有序集合
- zadd 添加数据
- zrangebyscore 获取数据
redis是内存数据库,性能要比磁盘数据库性能要好很多。所以一般情况下不会有性能问题。
redis本身数据类型的操作的信息是非常快的。redis自带了一个性能测试工具,这个工具模拟对redis 进行数据操作
redis-benchmark
src/redis-benchmark --help
src/redis-benchmark -n 300000 -qredis的性能问题
主要的原因,redis数据需要设置一个有效时长,如果不设置这个key对应value就会一直存在redis数据库中,redis是一个内存数据库,随着使用时间越来越长,如果没有给key设置一个失效时长,内存总会出现不够用的情况。所以要给key设置一个有效时长。但是如果这个有效时长设置的不合理,就可能导致问题。
- redis的穿透
- redis是一个缓存数据库,是用于缓存从磁盘数据库中获取到数据,减少从磁盘获取数据的次 数,提高获取数据的速度。
- redis的穿透,是获取数据的时候,我们key是非法的,永远不存在的。获取key的值时,从 redis是永远拿不到值,就要去后面的磁盘数据库中获取,对磁盘数据库造成了很大的压力, 设置可能导致磁盘数据库宕机。
- 解决:在代码中,对非法的key进行处理就可以了。
- redis的击穿
- 持续一段时间内,有大量的请求,集中在少量的key上面,当key失效的时候,瞬间请求到了 后端磁盘数据库,导致后端磁盘数据库瞬间压力非常大。
- 解决:限量
- 持续一段时间内,有大量的请求,集中在少量的key上面,当key失效的时候,瞬间请求到了 后端磁盘数据库,导致后端磁盘数据库瞬间压力非常大。
- redis的雪崩
- redis中key是有一个失效时间,在同一个时间点里,有大面积的key失效,请求这些key的时 候,都请求到了后端磁盘数据库。
- 解决:redis设置key的失效时间随机
- redis中key是有一个失效时间,在同一个时间点里,有大面积的key失效,请求这些key的时 候,都请求到了后端磁盘数据库。
实战项目
redis_good_cache项目
数据库监控 mysql
数据库的监控、
redis数据库的监控