MapReduce过程解析
一、Map过程解析
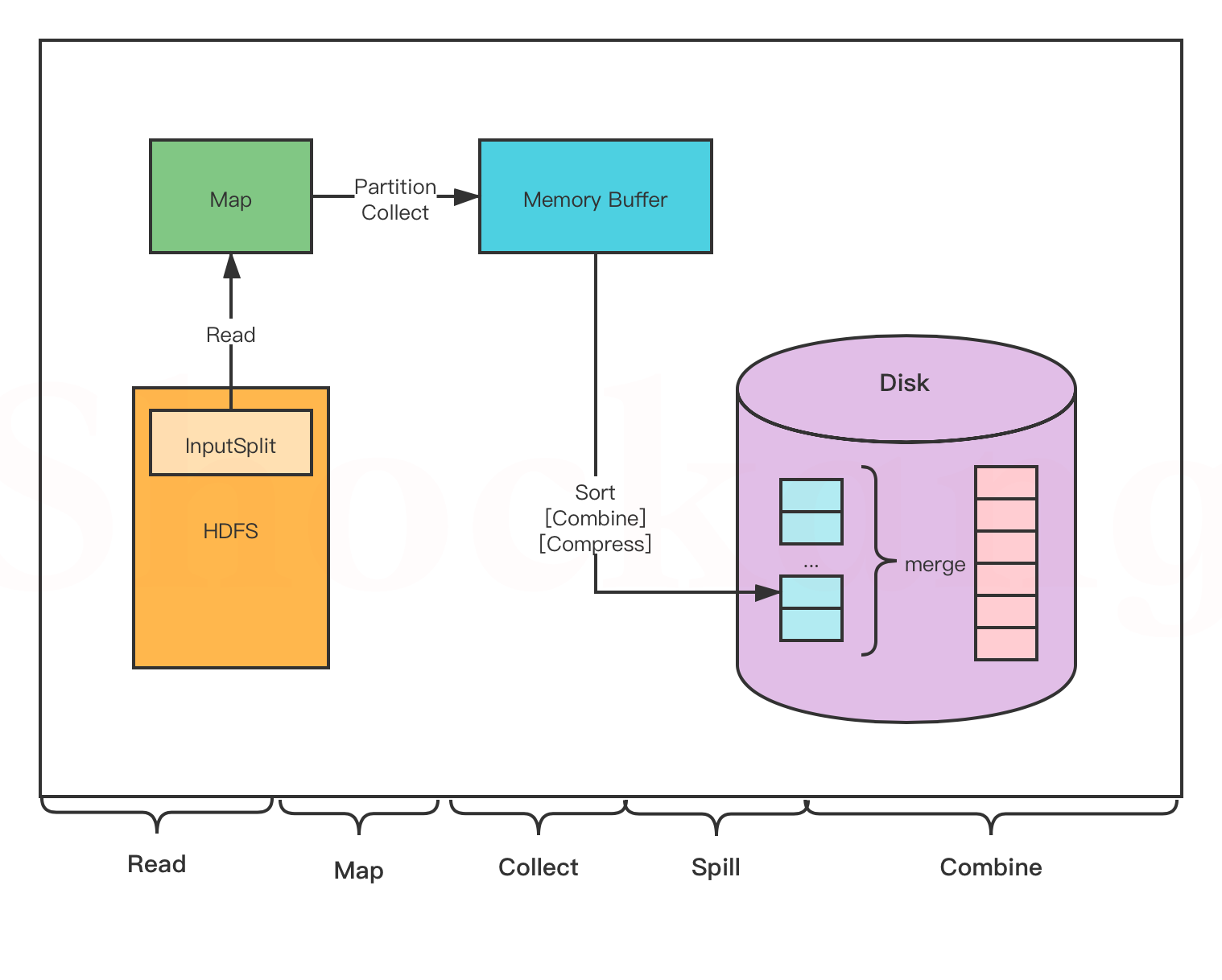
- Read阶段:MapTask通过用户编写的RecordReader,从输入的InputSplit中解析出一个个key/value。
- Map阶段:将解析出的key/value交给用户编写的Map()函数处理,并产生一系列的key/value。
- Collect阶段:在用户编写的map()函数中,数据处理完成后,一般会调用outputCollector.collect()输出结果,在该函数内部,它会将生成的key/value分片(通过调用partitioner),并写入一个环形缓冲区(该环形缓冲区的大小为100M)
- Spill阶段:即”溢写“,当缓冲区快要溢出时(默认达到缓冲区大小的80%),会在本地文件系统创建一个溢写文件,将该缓冲区的数据写入到这个文件。
- Combine阶段:当所有的数据处理完成以后,MapTask会对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
将数据写入本地磁盘前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
写入磁盘之前,线程会根据 ReduceTask 的数量,将数据分区,一个 Reduce 任务对应一个分区的数据。
这样做的目的是为了避免有些 Reduce 任务分配到大量数据,而有些 Reduce 任务分到很少的数据,甚至没有分到数据的尴尬局面。
如果此时设置了 Combiner ,将排序后的结果进行 Combine 操作,这样做的目的是尽可能少地执行数据写入磁盘的操作。
二、ReduceTask
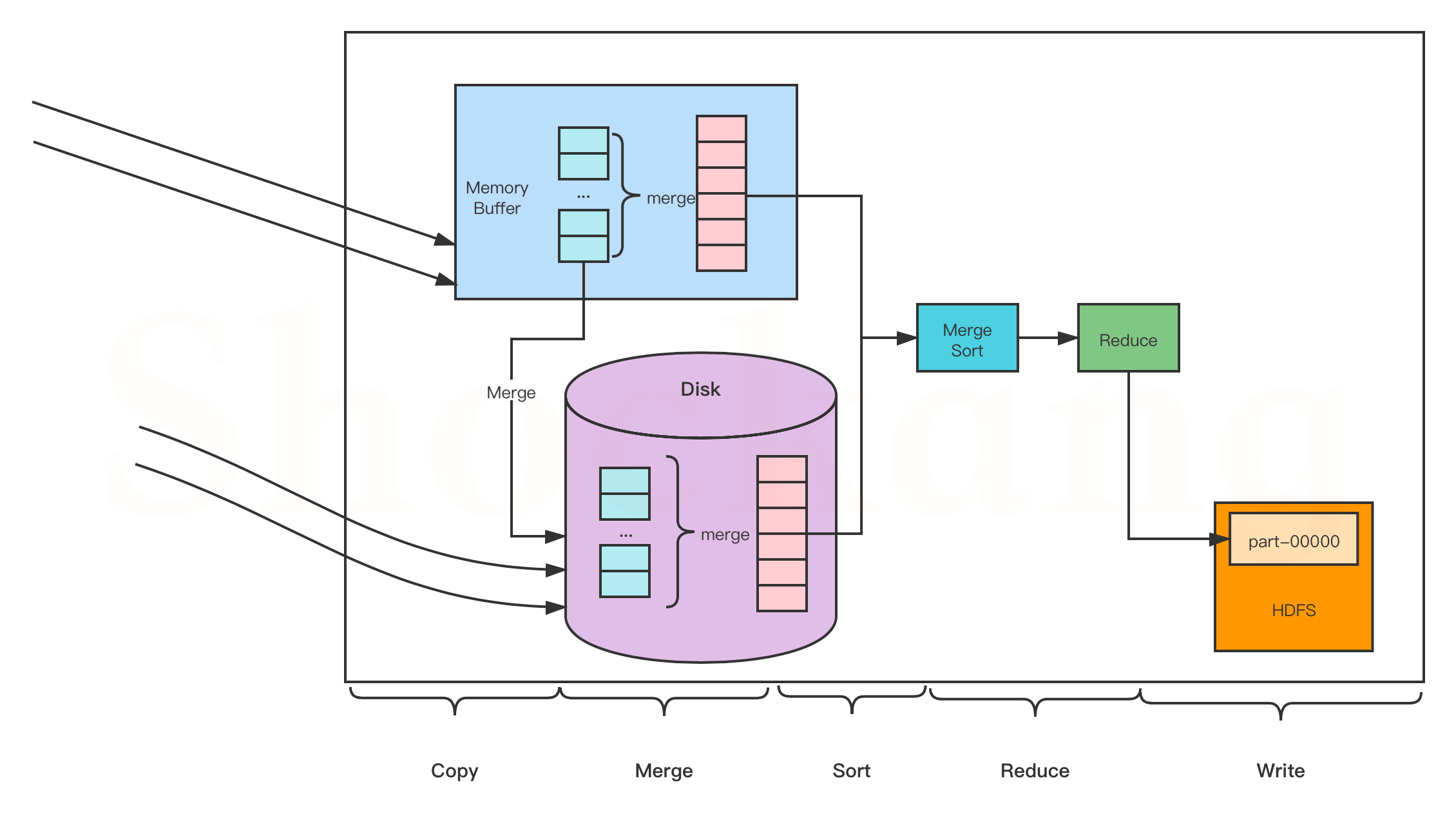
- Copy阶段:Reduce会从各个MapTask上远程复制一片数据(每个MapTask传来的数据都是有序的),并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中;
- Merge阶段:在远程复制数据的同时,ReduceTask会启动两个后台进程,分别对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘文件过多;
- Sort阶段:用户编写reduce()方法,输入数据是按key进行聚集的一组数据
- Reduce阶段:对排序后的键值对调用reduce()方法,键相等的键值对调用一次reduce()方法,每次调用会长生零个或者多个键值对,最后把这些输出的键值对亵渎到hdfs上;
- Write阶段:reduce()函数将计算结果写到HDFS上。