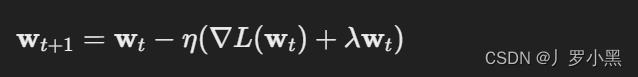在第一遍阅读的时候,只需要看题目,摘要和结论,先看题目是不是跟我的方向有关,看摘要是不是用到了我感兴趣的方法,看结论他是怎么解决摘要中提出的问题,或者怎么实现摘要中的方法,然后决定我要不要继续看第二遍 在第二遍阅读的时候不需要关注太过工程性的技巧,比如输入数据是怎么转换的,网络是怎么做分布式训练的,第二遍阅读重点关注方法上的创新或者方法上的技巧,因为工程上的技巧很复杂,不容易复现,但是方法上的创新相对比较简单 在介绍部分,我们不能只介绍自己使用的方法,这很窄,比如我想用DETR,那我就不能只介绍DETR,我可以介绍一下传统的OCR,比如CNN,YOLO等 对于图片领域来说,整个机器学习就是在做压缩,将本来人能看懂的输入图片,经过一个模型,最后压缩成一个向量,这个向量机器能够识别,机器能够学习之后,就能够拿它来做搜索、分类等各种各样的事情 权重衰减(weight decay)在深度学习中等价于L2正则化,都是让权重w的更新额外包括一个权重衰减项 λ w k λw_k λ w k 正则化是机器学习和统计建模中常用的一种技术,旨在减少模型的过拟合,提高模型的泛化能力。通过对模型添加约束或惩罚,正则化方法鼓励模型学习更加平滑或更简单的预测函数,从而不会对训练数据中的随机噪声做过度复杂的拟合。在实践中,这通常意味着对模型参数(如权重)的大小进行限制。 L1正则化:向损失函数添加参数的绝对值之和作为惩罚项。L1正则化倾向于产生稀疏的参数向量,即大多数参数值为零,这有助于特征选择,因为它可以自动忽略不重要的特征。 L2正则化:向损失函数添加参数的平方和作为惩罚项。L2正则化鼓励参数值趋向于较小的大小,从而避免任何参数对模型的预测产生过大的影响。这种方法对于处理参数间高度相关的数据特别有效。 在计算机视觉领域,可以重点关注某些竞赛的冠军、亚军,特别是那些提出了不一样的架构、方法的论文