CLIP CLAP
文章目录
- CLIP
- abstract
- intro
- CLAP: LEARNING AUDIO CONCEPTS FROM NATURAL LANGUAGE SUPERVISION
- abstract
- method
CLIP
- open AI
- 2021.2
- 代码&预训练模型

abstract
-
原有的基于有监督数据训练的计算机分类任务,在面对新的分类目标时泛化性和可用性都会变差;
-
本文提出使用海量网络图文匹配的数据(400 millon),做预训练模型。和NLP中的GPT模型效果类似,1实现可以zero-shot的迁移到很多图像任务——在30多个图像数据集(比如OCR,视频动作识别以及细分的图像分类任务),都表现良好。比如对于ResNet-50 on ImageNet的分类任务,不需要训练数据达到精确度相当的结果。
-
CLIP, for Con- trastive Language-Image Pre-training
intro
- 受益于NLP大模型预训练的思路启发,是否能够利用海量的网络数据预训练模型,实现任务目标无关(task-agnoistic)的学习,从而更加适用于多样的下游任务。
- 之前的工作有做过描述图像内容的各种方法尝试,但是效果差于经典的方法。分析了之前的工作是在有限的标签数据以及海量的无限制文本两种方式学习的折衷。
CLAP: LEARNING AUDIO CONCEPTS FROM NATURAL LANGUAGE SUPERVISION
abstract
- Contrastive Language-Audio Pretraining (CLAP):文本和audio使用两个单独的encoder,使用对比学习的训练策略,定义到同一个多模态的空间表征embedding,
- 128k的text-audio pair用于训练,每条audio被处理成5s的数据(~127h),然后在16个下游任务中进行zero-shot以及finetune的对比
method
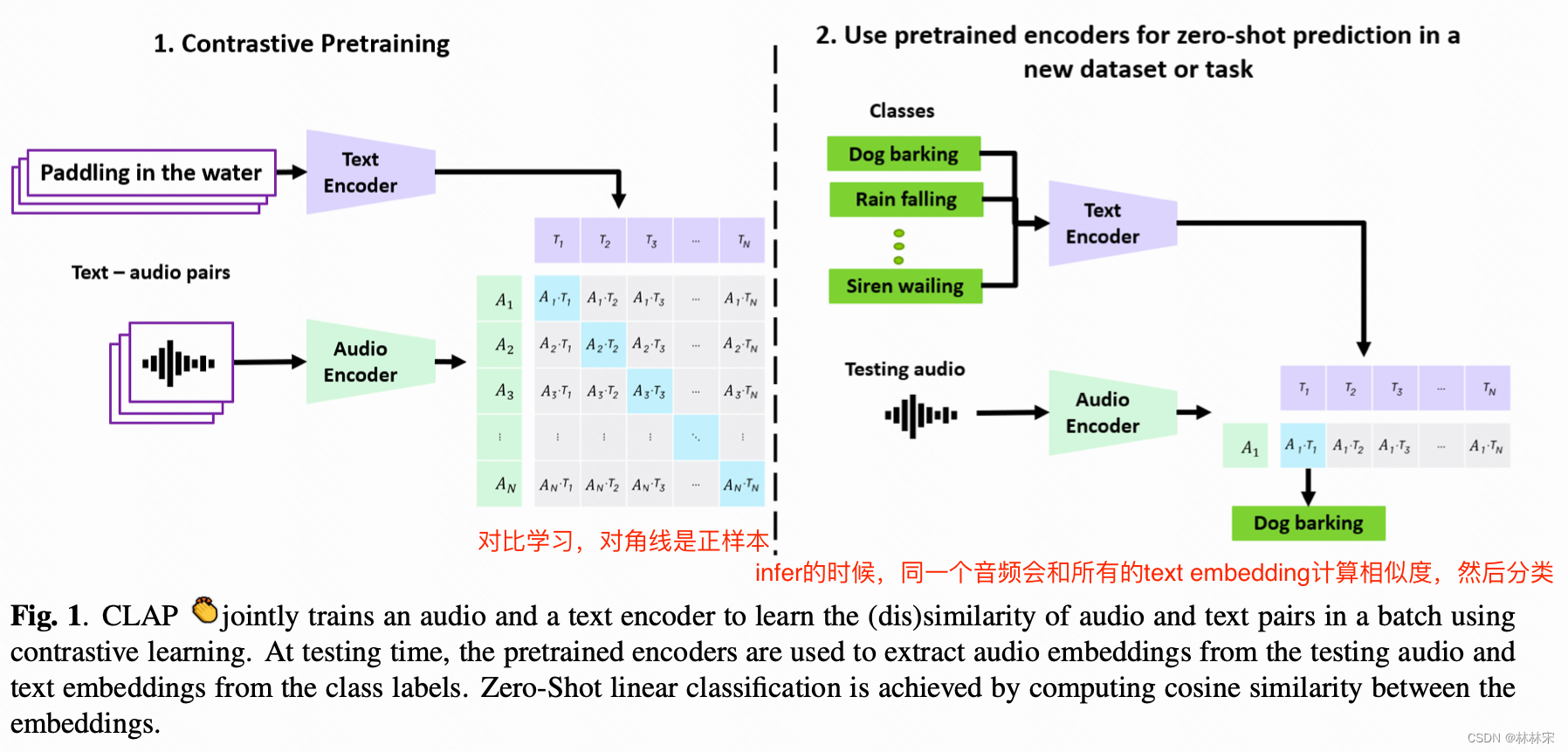
-
输入audio,text<1xL>
-
经过audio-encoder,将音频时间维度压缩,变成XaX_aXa:,N是batch size;text encoder编码后输出XtX_tXt:
-
分别经过线性变换,变成EaE_aEa和EtE_tEt
-
计算相似度矩阵