「论文阅读」还在手写Prompt,自动Prompt搜索超越人类水平
每周论文阅读笔记,来自于2023LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
code:https://github.com/keirp/automatic_prompt_engineer
手写prompt确实很费脑筋,但其实本身大语言模型就是一个很好的自动prompt工具,APE文章提出自动prompt工程(Automatic Prompt Engineer),利用语言模型来自动生成样例。
应用场景包括:
1)few-shot learning(in-context learning prompts);
2)zero-shot(chain-of-thought prompts);
方案思想
- Few-shot: 1)利用语言模型生成候选: 描述任务,输入样本,利用语言模型生成候选。2)利用语言模型对候选评分:以候选作为prompt,输出对应测试case的output,通过label验证。过滤掉得分太低的prompt候选。3)利用语言模型复述:过滤出来的高得分候选,对高得分候选进行改写,然后扩充更多相似的候选。
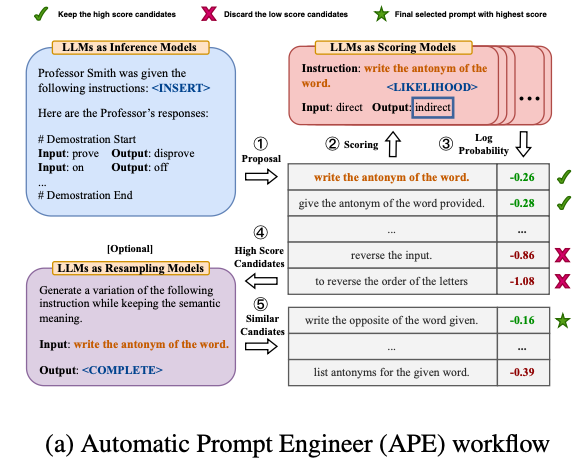
整个算法伪代码:

细节:
- 计算量控制:由于评分阶段计算量很大,会对数据进行切分多段进行分段评估过滤。
- 候选生成多样性:改变生成 instructions 的位置,包括最后、中间,以及改写。
Zero-shot: 因为没有样本,相对比较简单,自动的prompt话术是通用的,不会有人类针对特定任务详细的描述(但是可以二者结合),作者将其称为Chain of thought prompts
评估
Few-shot任务上都有所提升:
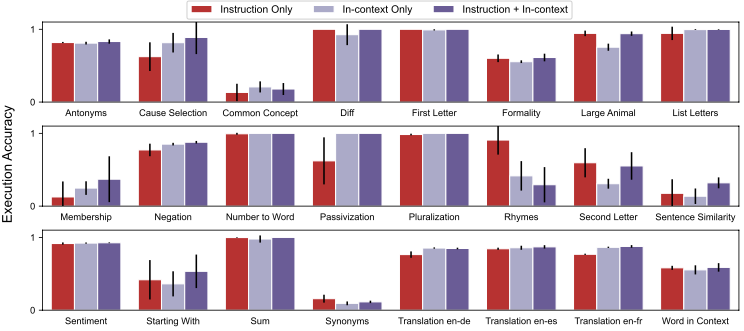
Zero-shot上的表现:Chain of thoughts思想,APE的生成结果确实带来了显著提升,即使相比于人类也有明显提升。

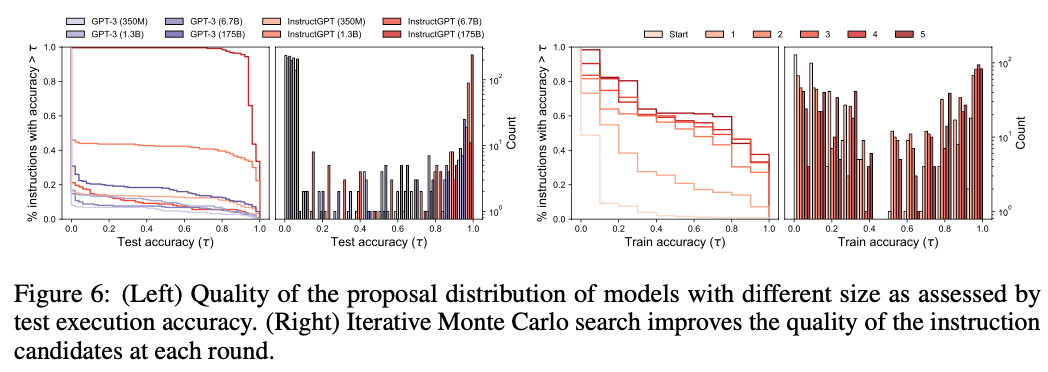
作者还做了定量分析:
不同参数量的模型:可以看到曲线中最大的提升还是来自于模型参数量,对于大模型提升较小。(所以这里怀疑这些工作可能后面随着模型优化意义不大,当然国内大模型情况下还是非常有用的🐶)
不同蒙特卡洛搜索次数下的候选:随着迭代次数越多,同准确率下instructions数量越多,证明了方法有效提升多样性。
后记:prompt工程分为soft prompts和natural language prompt,ChatGpt后的语言模型基本都是natural language prompt,本文也是后者。
公众号:百川NLP

Reference
- 2023LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
- https://blog.andrewcantino.com/blog/2021/04/21/prompt-engineering-tips-and-tricks/
- https://techcrunch.com/2022/07/29/a-startup-is-charging-1-99-for-strings-of-text-to-feed-to-dall-e-2/ • https://news.ycombinator.com/item?id=32943224
- https://promptomania.com/stable-diffusion-prompt-builder/
- https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3l8bkuotx4aog