稀疏矩阵的三元组表表示法及其转置
1. 什么是稀疏矩阵
稀疏矩阵是指矩阵中大多数元素为零的矩阵。
从直观上讲,当元素个数低于总元素的30%时,这样的矩阵被称为稀疏矩阵。
由于该种矩阵的特点,我们在存储这种矩阵时,如果直接采用二维数组,就会十分浪费空间,因为其中大多数元素都是重复的零。
稀疏矩阵的三元组表表示法
对于稀疏矩阵的压缩存储,采用只存储非零元素的方法。
由于稀疏矩阵中非零元素的分布没有规律,因此在存储非零元素值得同时,还必须存储该非零元素在矩阵中的位置信息,即行号和列号。
也就是采用三元组的结构存储:

为处理方便,将稀疏矩阵中非零元素对应的三元组行号依次增大进行存放。
这也就解释了,为什么稀疏矩阵是非零元素占比小于30%的矩阵。
因为采取三元组的结构储存,一个元素会占用三个单元的空间,只有当零元素占比小于30%时,这种存储结构才能在空间上有较明显的收益。
稀疏矩阵三元组表的类型定义
#define ElementType int//一个三元组元素
typedef struct
{int row, col;//非零元素行下标和列下标ElementType e;
}Triple;//稀疏矩阵
typedef struct
{Triple* data;//非零元素的三元组表int m, n, len;//矩阵行数,列数,非零元素个数int capacity;//容量
}TSMatrix;2. 对稀疏矩阵进行基本操作
//初始化稀疏矩阵
void TSMInite(TSMatrix* ps)
{assert(ps);ps->data = NULL;ps->m = TSM_ROWMAX;ps->n = TSM_COLMAX;ps->len = 0;ps->capacity = 0;
}//销毁稀疏矩阵
void TSMDestroy(TSMatrix* ps)
{assert(ps);free(ps->data);ps->data = NULL;ps->len = 0;ps->capacity = 0;
}//检查扩容
void CheckCapacity(TSMatrix* ps)
{assert(ps);if(ps->capacity == ps->len){int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;Triple* tmp = (Triple*)realloc(ps->data, newcapacity * sizeof(Triple));if(tmp == NULL){perror("realloc");exit(-1);}ps->data = tmp;ps->capacity = newcapacity;}
}//插入元素
void ElemInsert(TSMatrix* ps, Triple x)
{assert(ps);CheckCapacity(ps);if(ps->len == 0){ps->data[ps->len] = x;}if(x.row < ps->data[0].row){for(int j = ps->len; j > 0; j--){ps->data[j] = ps->data[j - 1];}ps->data[0] = x;}elsefor(int i = 0; i < ps->len; i++){if(x.row >= ps->data[i].row&&x.row <= ps->data[i + 1].row||i == ps->len - 1){for(int j = ps->len; j > i + 1; j--){ps->data[j] = ps->data[j - 1];}ps->data[i + 1] = x;break;}}ps->len++;
}//打印元素
void TSMPrint(TSMatrix ps)
{for(int i = 0; i < ps.len; i++){printf("row = %d col = %d e = %d\n", ps.data[i].row, ps.data[i].col, ps.data[i].e);}printf("\n");
}这些函数基本是以顺序表操作函数为蓝本写的,目的是为了方便我们实现稀疏矩阵的转置。
只不过插入元素的函数需要确保插入之后,三元组的行号是依次递增的。
3. 稀疏矩阵的转置
需要强调的是,矩阵的常规存储是二维的,而三元组表存储是一维的,由于矩阵存储结构的变化,也带来了运算方法的不同,必须认真分析。
3.1 稀疏矩阵转置的经典算法
void TransMatrix(ElementType source[m][n], ElementType dest[n][m])
{int i, j;for(i = 0; i < m; i++)for(j = 0; j < n; j++)dest[j][i] = source[i][j];
}这个算法是针对传统的二维数组的存储方式。
3.2 用三元组表实现稀疏矩阵的转置
假设A和B是稀疏矩阵source和dest的三元组表,则实现转置的简单方法如下:
1. 三元组表A的行,列互换就可以得到B中的元素。
2. 转置后的矩阵的三元组表B中的三元组不是以“行序为主序”存储的,为保证三元组表B也是以“行序为主序”进行存放的,则需要对该三元组表B按行下标(即A的列下标)以递增顺序重新排列。
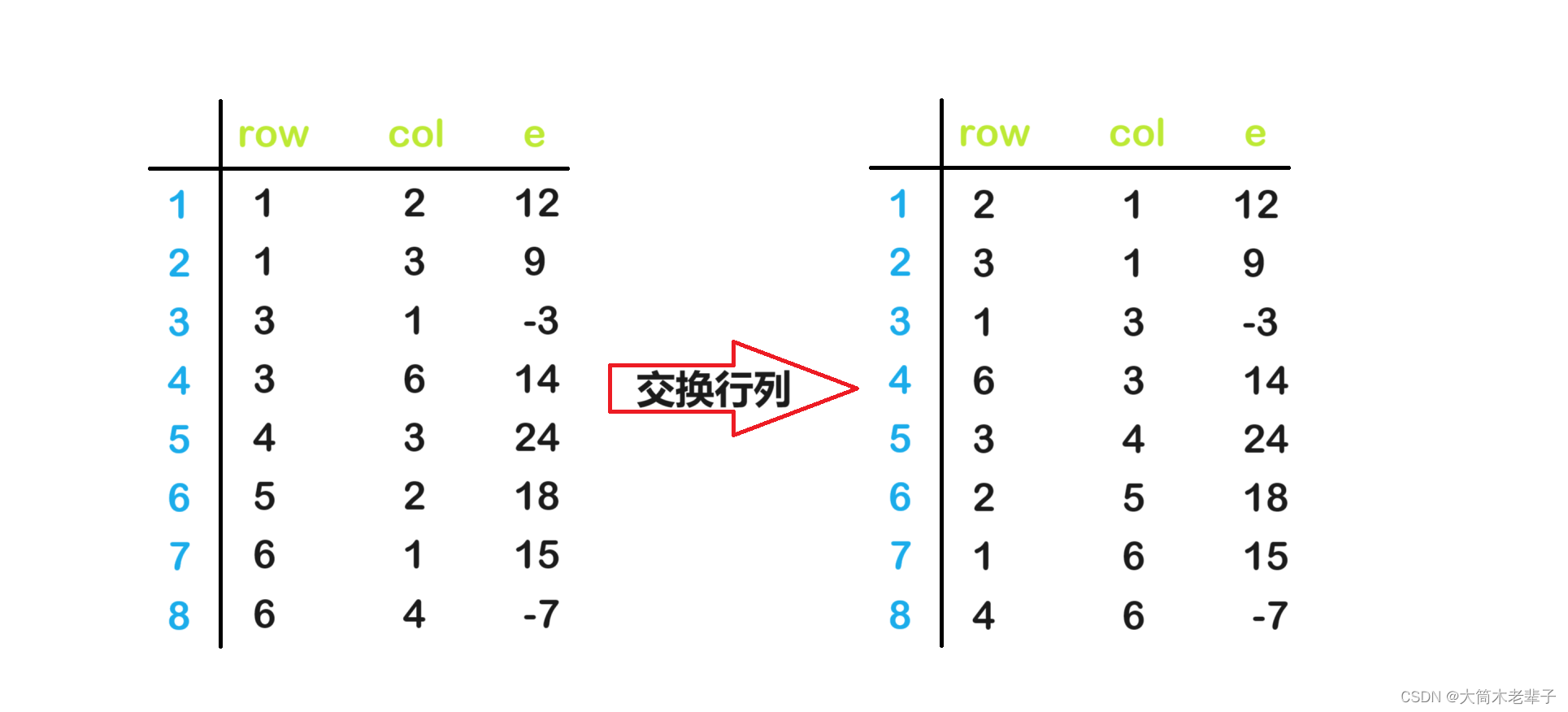
上图中的步骤很容易实现,但是重新排序势必会大量移动元素,从而影响算法的效率。
为避免上述简单转置算法中重新排序引起的元素移动,可采取接下来的两种处理方法。
3.2.1 列序递增转置法
算法思想
这里的列序指的是A的列,也就是按照A的列序来将元素转置到B中。
即将A的第一列全部转置到B中(得到B的第一行)后,再将A的第二列全部转置到B中,以此类推。
代码
//列序递增转置法
void TSMSwitch1(TSMatrix A, TSMatrix* B)
{assert(B);TSMDestroy(B);B->data = (Triple*)malloc(A.capacity * sizeof(Triple));B->capacity = A.capacity;B->len = A.len;B->m = A.n;B->n = A.m;int j = 0;//记录B当前空位for(int k = 0; k < A.n; k++){for(int i = 0; i < A.len; i++){if(A.data[i].col == k){B->data[j].row = A.data[i].col;B->data[j].col = A.data[i].row;B->data[j].e = A.data[i].e;j++;}}}
}分析
这种算法确实使得我们不用再单独进行排序,但是双重循环依然造成了较高的时间复杂度(O(A.n * A.len))。
那么我们能否降低该算法的时间复杂度呢?
如果能,那么我们的着手点一定是想办法优化掉二重循环。
可以发现,该算法中二重循环出现的原因在于,必须将A的第一列全部转置之后才能转置第二列,每列转置需要重新扫描一次A。
那么,我们有没有办法使得各列同时进行存放呢,这样就只用扫描一次A了。
3.2.2 一次定位快速转置法
算法思想
如果我们知道A的每一列有多少个元素,那么就可以推知B中每一行的起始位置。
这样一来,假如某次在A中扫描到第n列的元素,我们就可以直接将其放到B中的第n行所在位置,而不用先放完一列再放下一列。
所以,我们准备进行三次循环:
1. 定义数组num,数组的下标表示A的列,遍历A并将每一列元素的个数记录在num中。
2. 定义数组position,数组下标表示B的行,遍历position,根据A每一列元素的个数得到对应行的起始位置。
3. 遍历A,根据position数组,将A中的元素转置到B的对应行。
代码
//一次定位快速转置算法
void TSMSwitch2(TSMatrix A, TSMatrix* B)
{assert(B);TSMDestroy(B);B->data = (Triple*)malloc(A.capacity * sizeof(Triple));B->capacity = A.capacity;B->len = A.len;B->m = A.n;B->n = A.m;int num[B->m];int position[B->m];memset(num, 0, B->m * sizeof(int));memset(num, 0, B->m * sizeof(int));for(int i = 0; i < A.len; i++){num[A.data[i].col]++;}position[0] = 0;for(int row = 1; row < B->m; row++){position[row] = position[row - 1] + num[row - 1];}for(int i = 0; i < A.len; i++){B->data[position[A.data[i].col]].row = A.data[i].col;B->data[position[A.data[i].col]].col = A.data[i].row;B->data[position[A.data[i].col]].e = A.data[i].e;position[A.data[i].col]++;}
}算法分析
显然,一次定位快速转置算法的时间效率要高得多,它在时间性能上由于列序递增转置法,但在空间耗费上增加了两个辅助向量空间,即num和position。
由此可见,算法在时间上的节省是以更多的储存空间为代价的。