机器学习的模型校准
背景知识
之前一直没了解过模型校准是什么东西,最近上班业务需要看了一下:
模型校准是指对分类模型进行修正以提高其概率预测的准确性。在分类模型中,预测结果通常以类别标签形式呈现(例如,0或1),但有时我们更关注的是预测的概率。
当使用某些分类模型(例如支持向量机(SVM)或随机森林)时,其预测的概率并不一定与真实标签的概率分布相匹配。这意味着,即使预测概率较高的类别出现的频率更高,模型的预测概率也可能偏离真实情况。这可能导致对模型的概率输出有误解,或者在需要高度依赖概率预测的任务(例如风险评估或阈值选择)中出现问题。
通过校准分类模型,我们可以将模型的预测概率调整为更准确地反映真实情况。`CalibratedClassifierCV`是Scikit-learn库中提供的用于校准分类器的类。它根据指定的校准方法(`method`),通过拟合后的分类器(`model`)和交叉验证拟合(`cv='prefit'`)来创建一个经过校准的分类器(`calibrated_model`)。
在代码中,使用`calibrated_model.fit(X_train, y_train)`通过使用交叉验证拟合来训练、校准模型。之后,使用`calibrated_model.predict(X_test)`对测试集进行预测,并使用`classification_report`输出校准模型的分类性能报告。
通过校准分类模型,我们可以使得模型的概率预测更为准确,从而提高在概率判断和相关任务中的性能和可靠性。
代码实现
模型校准主要是针对分类模型的,我之前都是做回归,难怪没怎么接触过。也没空找真实数据了,直接模拟数据来实现一下。
导入包和制作数据集
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.calibration import calibration_curve
from sklearn.ensemble import RandomForestClassifierimport matplotlib.pyplot as plt# 生成二分类数据集
X, y = make_classification(n_samples=10000, n_features=40, n_classes=2, weights=[0.9, 0.1], random_state=2, flip_y=0.3)查看分布:
pd.Series(y).value_counts()
不平衡样本。
标准化,划分训练集测试集
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y,stratify=y, test_size=0.2, random_state=2)训练,然后评价,这里就弄了个随机森林模型试试
# 模型训练
model =RandomForestClassifier()
model.fit(X_train, y_train)# 模型评价
y_pred = model.predict(X_test)
print("Classification Report:")
print(classification_report(y_test, y_pred))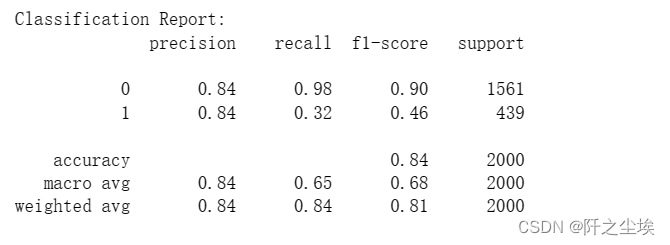
画校准曲线。
# 计算校准曲线
prob_true, prob_pred = calibration_curve(y_test, model.predict_proba(X_test)[:, 1], n_bins=10)# 绘制校准曲线
plt.figure(figsize=(7, 4),dpi=128)
plt.plot(prob_pred, prob_true, marker='o', label='uncalibrated')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray', label='perfectly calibrated')
plt.xlabel('Mean predicted probability')
plt.ylabel('Fraction of positives')
plt.title('Calibration Curve (Uncalibrated)')
plt.legend()
plt.show()
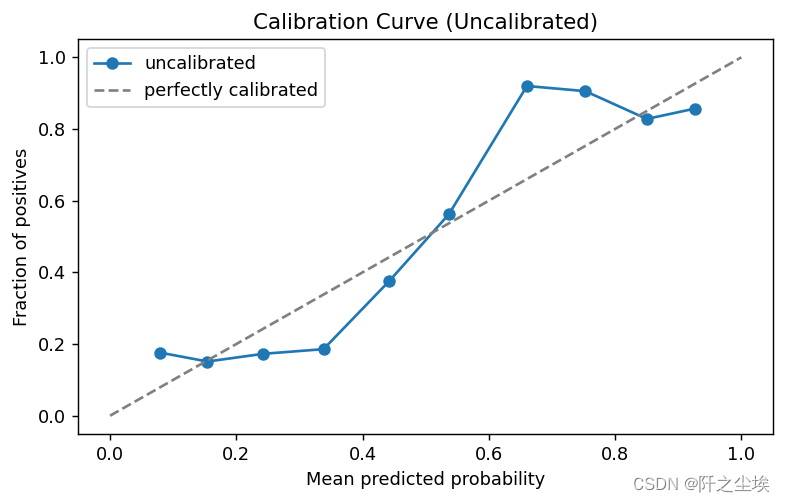
这玩意怎么看,,,我也不太懂,反正就是要单调,并且越靠近对角线越好。这个明显在0.1-0.2区间不单调,还有0.7-0.9也在下降。
来校准一下:
模型校准
模型校准很多方法,目前这个是用了 method='sigmoid',这个方法,好像叫做什么p系数校准。
from sklearn.calibration import CalibratedClassifierCV
calibrated_model = CalibratedClassifierCV(model, method='sigmoid', cv='prefit')
calibrated_model.fit(X_train, y_train)# 模型评价(校准后)
y_pred_calibrated = calibrated_model.predict(X_test)
print("Classification Report (Calibrated Model):")
print(classification_report(y_test, y_pred_calibrated))
emmm,效果好像没有明显提升。
method='isotonic',这个是什么保序回归方法校准。
calibrated_model2 = CalibratedClassifierCV(model, method='isotonic', cv='prefit')
calibrated_model2.fit(X_train, y_train)# 模型评价(校准后)
y_pred_calibrated2 = calibrated_model2.predict(X_test)
print("Classification Report (Calibrated Model):")
print(classification_report(y_test, y_pred_calibrated2))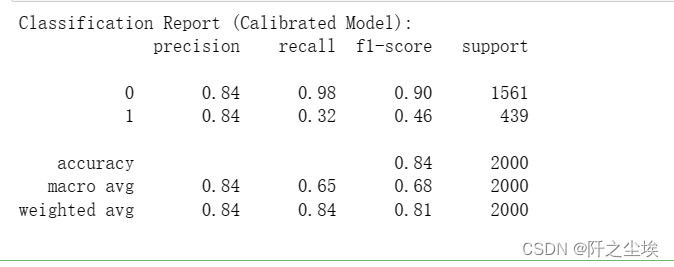
效果也差不多。
画出校准曲线的对比图:
# 计算校准后的校准曲线
prob_true_calibrated, prob_pred_calibrated = calibration_curve(y_pred_calibrated,calibrated_model.predict_proba(X_test)[:, 1], n_bins=10)
prob_true_calibrated2, prob_pred_calibrated2 = calibration_curve(y_pred_calibrated2,calibrated_model2.predict_proba(X_test)[:, 1], n_bins=10)
# 绘制校准后的校准曲线
plt.figure(figsize=(7, 4),dpi=128)
plt.plot(prob_pred, prob_true, marker='o', label='uncalibrated')
plt.plot(prob_pred_calibrated, prob_true_calibrated, marker='o', label='sigmoid calibrated')
plt.plot(prob_pred_calibrated2, prob_true_calibrated2, marker='o', label='isotonic calibrated')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray', label='perfectly calibrated')
plt.xlabel('Mean predicted probability')
plt.ylabel('Fraction of positives')
plt.title('Calibration Curve (Calibrated)')
plt.legend()
plt.show()
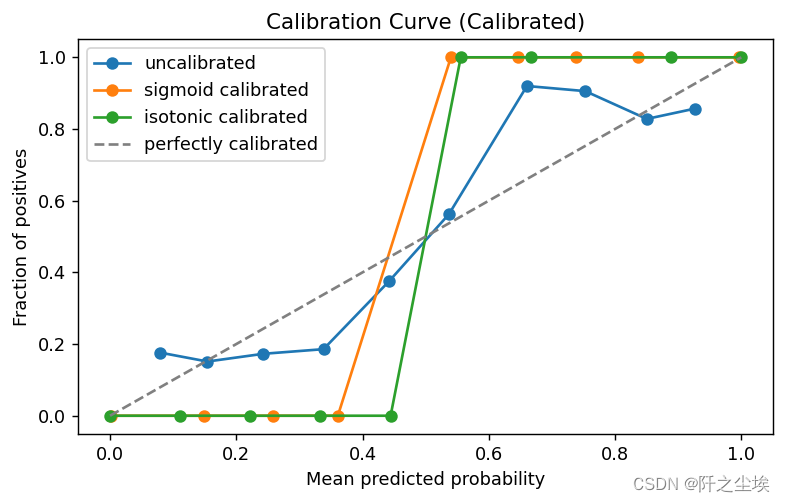
可以看到模型校准之后这个线都是单调上升的了。但是都很奇怪,而且预测效果也没太多改善,可能是我这个数据集是随便造的原因。
校准曲线的单调性在模型校准中确实非常重要。校准曲线的单调性指的是在横轴表示预测概率的均值,纵轴表示实际观测到的正例比例时,曲线应该是单调递增的,即预测概率越高,观测到的正例比例也应该越高。
校准曲线的单调性反映了模型输出的概率与实际观测之间的一致性。如果校准曲线的单调性较差,意味着模型的输出概率与实际观测之间存在较大的偏差,可能会导致模型在实际应用中表现不稳定或不可靠。因此,单调的校准曲线通常被认为是一个良好校准的指标之一。
在实际应用中,如果模型的校准曲线不单调,可能需要进一步考虑以下问题:
模型的输出概率是否准确反映了样本的真实概率:如果模型输出的概率存在系统性的偏差,可能需要对模型进行校准,使其输出更加准确地反映样本的真实概率。
模型是否过度自信或不足自信:校准曲线的不单调性可能反映了模型在某些概率范围内过度自信或不足自信的问题。对于过度自信的模型,可能需要降低其输出概率;对于不足自信的模型,可能需要提高其输出概率。
模型的可靠性:校准曲线的单调性也反映了模型的可靠性。单调递增的校准曲线意味着模型的输出概率与实际观测之间的一致性较好,通常更可靠。
因此,校准曲线的单调性对于评估模型的校准效果和可靠性具有重要意义,在模型校准过程中应该注意观察和优化校准曲线的单调性。
嗯,都是gpt的话,看看了解一下就行。