InstructGPT方法简读
InstructGPT方法简读
引言
仅仅通过增大模型规模和数据规模来训练更大的模型并不能使得大模型更好地理解用户意图。由于数据的噪声极大,并且现在的大多数大型语言模型均为基于深度学习的“黑箱模型”,几乎不具有可解释性和可控性,因此,大模型很可能会输出虚构的、有害的,或者对用户无用的结果。换句话说,大模型并没有与用户对齐(aligned)。本文提出了一种通过微调人类反馈来调整语言模型和用户在广泛任务中的意图的方法。从一组标注员编写的 prompt 和通过 OpenAI API 提交的 prompt 开始,本文收集了人类标注的所需模型行为的数据集,使用该数据集通过有监督学习来微调 GPT-3。然后,由标注员对模型输出的回答质量进行排序,得到一个问答质量排序数据集。使用该数据集来训练一个评分模型,为回答质量进行打分。最后结合评分模型,使用强化学习来进一步微调第一步有监督微调过的模型。得到的模型称为InstructGPT。
从 GPT 到 InstructGPT/ChatGPT:对齐(align),不仅仅是简单的语言模型(LM),而能够进行对话。
优化目标:3H:Helpful、Honest、Harmless。三点优化目标要求模型输出人类想要的信息,分别是有用、诚实和无害。
方法
如图 1 所示,由 GPT 到 InstructGPT 的训练共有三个步骤,分别是第一阶段有监督微调、第二阶段奖励模型训练、第三阶段根据 PPO 近端算法进行强化学习训练。接下来将分别从三个阶段的数据集、模型和训练目标出发,介绍 InstructGPT 的完整训练过程。
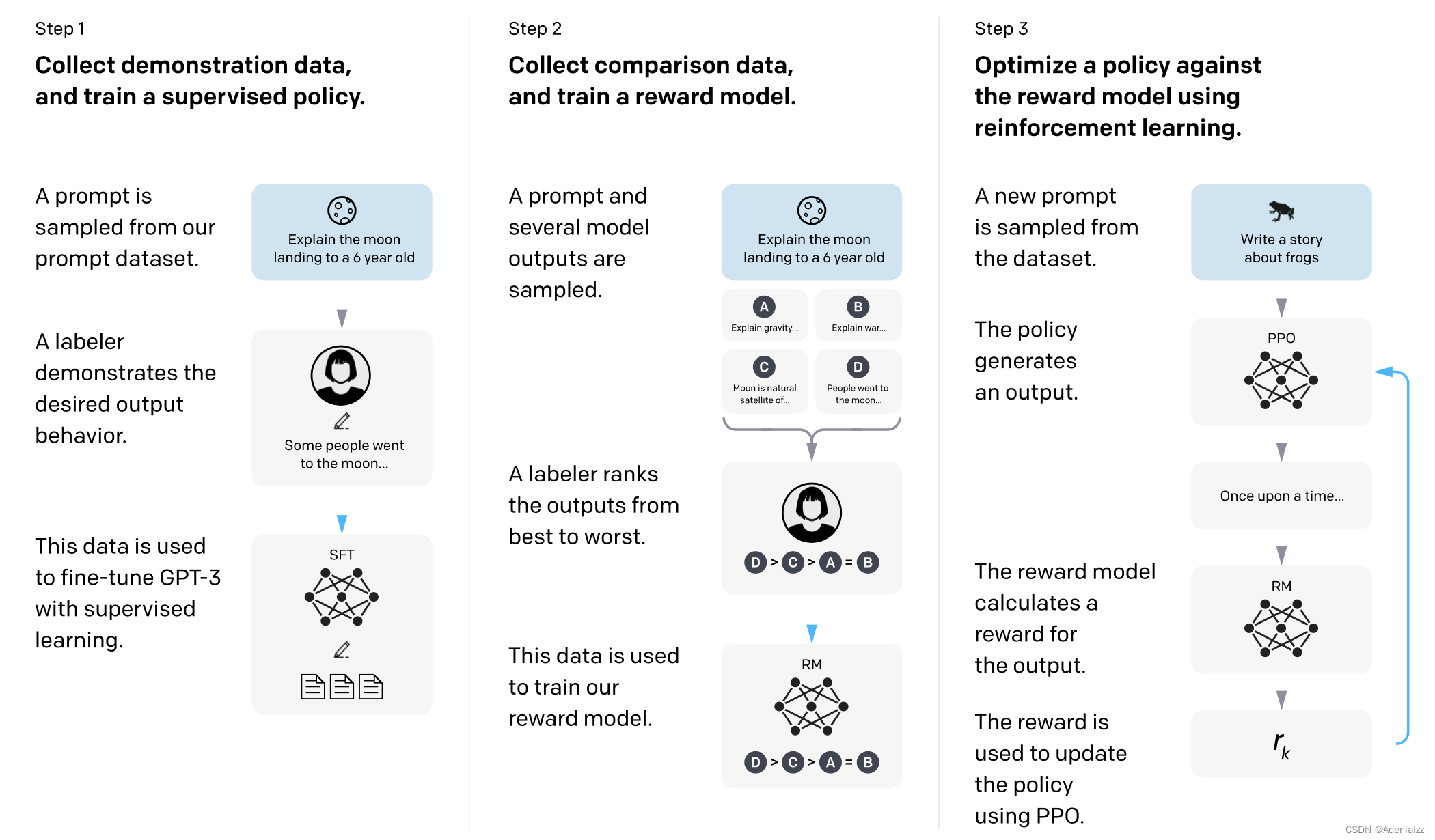
数据集
数据集的收集过程如下。首先使用初步模型,发布内测版接口给用户使用,收集问题(prompt)。根据这些问题构建数据集:
- 请标注工直接写问题的答案,用于微调训练 SFT 模型,~13k;
- 将问题输入 LM,生成多个答案,请标注工对这些答案的质量进行排序,用于训练 RM 模型,~33k;
- 不需要标注工,RM 模型对 LM 进行强化学习训练,~31k;
模型与训练目标
SFT(Supervised Fine-Tuned)
16ep,虽然 ep1 就过拟合了,但是由于是用于后续的训练步骤,而非最终模型,因此不怕过拟合。
RM(Reward Model)
在 SFT 模型的基础上进行微调,输出层改为 FC,最后输出一个标量值,表示问答质量得分(reward)。
该模型的训练数据是标注工标注的回答质量排序,而非具体的标量得分,损失函数为成对排序损失(pairwise ranking loss):
loss(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]\text{loss}(\theta)=-\frac{1}{\begin{pmatrix}K\\2\end{pmatrix}}E_{(x,y_w,y_l)\sim D}[\log(\sigma(r_\theta(x,y_w)-r_\theta(x,y_l)))] loss(θ)=−(K2)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
其中 rθ(x,y)r_\theta(x,y)rθ(x,y) 是参数为 θ\thetaθ 的 RM 模型对于问答对 (x,y)(x,y)(x,y) 的评分,yw,yly_w,y_lyw,yl 是一对回答,其中 ywy_wyw 的质量相对更好,DDD 是标注员标注的问答质量排序数据集。该损失函数的优化目标就是 RM 需要对较好的回答给出更高的评分。
强化学习训练最终的 LM 模型
该阶段强化学习的目标函数为
objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))]\text{objective}(\phi)=E_{(x,y)\sim D_{\pi_\phi^{RL}}}[r_\theta(x,y)-\beta\log (\pi_\phi^{RL}(y|x)/\pi^{SFT}(y|x))]+\gamma E_{x\sim D_\text{pretrain}}[\log(\pi_\phi^{RL}(x))] objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))]
其中 πϕRL\pi_\phi^{RL}πϕRL 是要学习的 RL 策略(即最终的 InstructGPT 模型),πSFT\pi^{SFT}πSFT 是经过第一步有监督训练之后的模型,DpretrainD_\text{pretrain}Dpretrain 是预训练时的数据分布。式中二三两项分别是 KL 惩罚项和语言建模预训练正则项,分别用来约束模型参数不要与 πSFT\pi^{SFT}πSFT 差距太大,重新使用预训练阶段的语言建模作为优化目标,保证模型的通用 NLP 能力。β\betaβ 和 γ\gammaγ 分别是控制这两项的权重参数。
LM 模型对给定问题生成答案。目标函数共有三项,分别是
- 最大化 RM 评分值
- KL 散度正则项,使得模型与 SFT 模型的输出接近
- LM 预训练(原 GPT 训练) 正则项
Ref
-
Training language models to follow instructions with human feedback
-
InstructGPT 论文精读【论文精读·48】
-
ChatGPT/InstructGPT详解
-
关于Instruct GPT复现的一些细节与想法